 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecouple and Orthogonalize: A Data-Free Framework for LoRA Merging
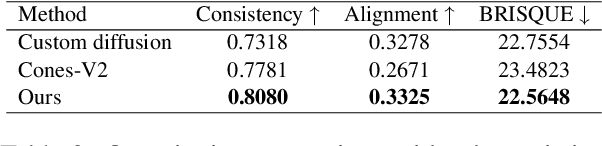
May 21, 2025With more open-source models available for diverse tasks, model merging has gained attention by combining models into one, reducing training, storage, and inference costs. Current research mainly focuses on model merging for full fine-tuning, overlooking the popular LoRA. However, our empirical analysis reveals that: a) existing merging methods designed for full fine-tuning perform poorly on LoRA; b) LoRA modules show much larger parameter magnitude variance than full fine-tuned weights; c) greater parameter magnitude variance correlates with worse merging performance. Considering that large magnitude variances cause deviations in the distribution of the merged parameters, resulting in information loss and performance degradation, we propose a Decoupled and Orthogonal merging approach(DO-Merging). By separating parameters into magnitude and direction components and merging them independently, we reduce the impact of magnitude differences on the directional alignment of the merged models, thereby preserving task information. Furthermore, we introduce a data-free, layer-wise gradient descent method with orthogonal constraints to mitigate interference during the merging of direction components. We provide theoretical guarantees for both the decoupling and orthogonal components. And we validate through extensive experiments across vision, language, and multi-modal domains that our proposed DO-Merging can achieve significantly higher performance than existing merging methods at a minimal cost. Notably, each component can be flexibly integrated with existing methods, offering near free-lunch improvements across tasks.
Scene123: One Prompt to 3D Scene Generation via Video-Assisted and Consistency-Enhanced MAE
Aug 10, 2024



As Artificial Intelligence Generated Content (AIGC) advances, a variety of methods have been developed to generate text, images, videos, and 3D objects from single or multimodal inputs, contributing efforts to emulate human-like cognitive content creation. However, generating realistic large-scale scenes from a single input presents a challenge due to the complexities involved in ensuring consistency across extrapolated views generated by models. Benefiting from recent video generation models and implicit neural representations, we propose Scene123, a 3D scene generation model, that not only ensures realism and diversity through the video generation framework but also uses implicit neural fields combined with Masked Autoencoders (MAE) to effectively ensures the consistency of unseen areas across views. Specifically, we initially warp the input image (or an image generated from text) to simulate adjacent views, filling the invisible areas with the MAE model. However, these filled images usually fail to maintain view consistency, thus we utilize the produced views to optimize a neural radiance field, enhancing geometric consistency. Moreover, to further enhance the details and texture fidelity of generated views, we employ a GAN-based Loss against images derived from the input image through the video generation model. Extensive experiments demonstrate that our method can generate realistic and consistent scenes from a single prompt. Both qualitative and quantitative results indicate that our approach surpasses existing state-of-the-art methods. We show encourage video examples at https://yiyingyang12.github.io/Scene123.github.io/.
Lightweight Model Pre-training via Language Guided Knowledge Distillation
Jun 17, 2024



This paper studies the problem of pre-training for small models, which is essential for many mobile devices. Current state-of-the-art methods on this problem transfer the representational knowledge of a large network (as a Teacher) into a smaller model (as a Student) using self-supervised distillation, improving the performance of the small model on downstream tasks. However, existing approaches are insufficient in extracting the crucial knowledge that is useful for discerning categories in downstream tasks during the distillation process. In this paper, for the first time, we introduce language guidance to the distillation process and propose a new method named Language-Guided Distillation (LGD) system, which uses category names of the target downstream task to help refine the knowledge transferred between the teacher and student. To this end, we utilize a pre-trained text encoder to extract semantic embeddings from language and construct a textual semantic space called Textual Semantics Bank (TSB). Furthermore, we design a Language-Guided Knowledge Aggregation (LGKA) module to construct the visual semantic space, also named Visual Semantics Bank (VSB). The task-related knowledge is transferred by driving a student encoder to mimic the similarity score distribution inferred by a teacher over TSB and VSB. Compared with other small models obtained by either ImageNet pre-training or self-supervised distillation, experiment results show that the distilled lightweight model using the proposed LGD method presents state-of-the-art performance and is validated on various downstream tasks, including classification, detection, and segmentation. We have made the code available at https://github.com/mZhenz/LGD.
DualMamba: A Lightweight Spectral-Spatial Mamba-Convolution Network for Hyperspectral Image Classification
Jun 11, 2024
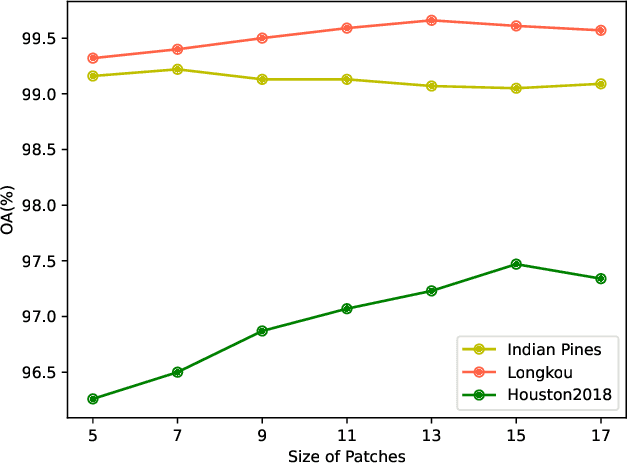
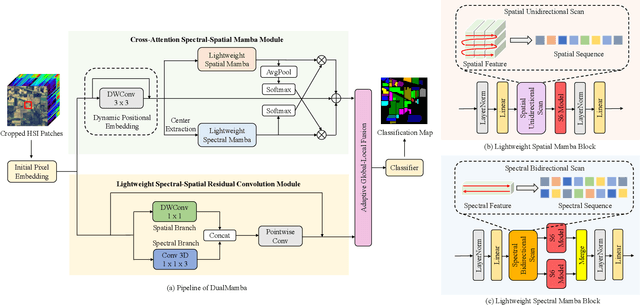
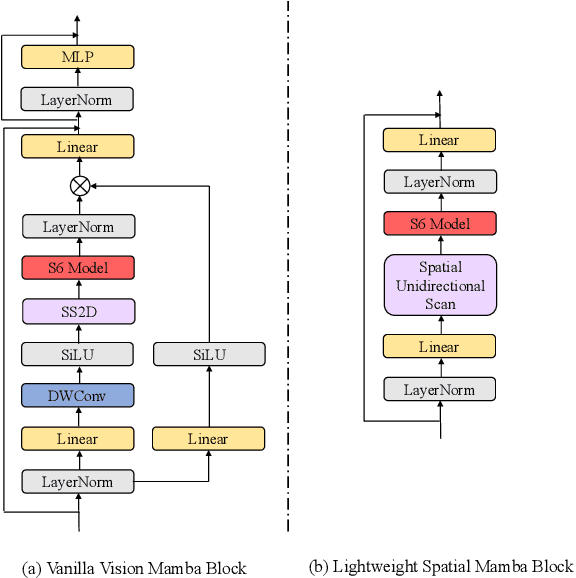
The effectiveness and efficiency of modeling complex spectral-spatial relations are both crucial for Hyperspectral image (HSI) classification. Most existing methods based on CNNs and transformers still suffer from heavy computational burdens and have room for improvement in capturing the global-local spectral-spatial feature representation. To this end, we propose a novel lightweight parallel design called lightweight dual-stream Mamba-convolution network (DualMamba) for HSI classification. Specifically, a parallel lightweight Mamba and CNN block are first developed to extract global and local spectral-spatial features. First, the cross-attention spectral-spatial Mamba module is proposed to leverage the global modeling of Mamba at linear complexity. Within this module, dynamic positional embedding is designed to enhance the spatial location information of visual sequences. The lightweight spectral/spatial Mamba blocks comprise an efficient scanning strategy and a lightweight Mamba design to efficiently extract global spectral-spatial features. And the cross-attention spectral-spatial fusion is designed to learn cross-correlation and fuse spectral-spatial features. Second, the lightweight spectral-spatial residual convolution module is proposed with lightweight spectral and spatial branches to extract local spectral-spatial features through residual learning. Finally, the adaptive global-local fusion is proposed to dynamically combine global Mamba features and local convolution features for a global-local spectral-spatial representation. Compared with state-of-the-art HSI classification methods, experimental results demonstrate that DualMamba achieves significant classification accuracy on three public HSI datasets and a superior reduction in model parameters and floating point operations (FLOPs).
Adapter-X: A Novel General Parameter-Efficient Fine-Tuning Framework for Vision
Jun 06, 2024



Parameter-efficient fine-tuning (PEFT) has become increasingly important as foundation models continue to grow in both popularity and size. Adapter has been particularly well-received due to their potential for parameter reduction and adaptability across diverse tasks. However, striking a balance between high efficiency and robust generalization across tasks remains a challenge for adapter-based methods. We analyze existing methods and find that: 1) parameter sharing is the key to reducing redundancy; 2) more tunable parameters, dynamic allocation, and block-specific design are keys to improving performance. Unfortunately, no previous work considers all these factors. Inspired by this insight, we introduce a novel framework named Adapter-X. First, a Sharing Mixture of Adapters (SMoA) module is proposed to fulfill token-level dynamic allocation, increased tunable parameters, and inter-block sharing at the same time. Second, some block-specific designs like Prompt Generator (PG) are introduced to further enhance the ability of adaptation. Extensive experiments across 2D image and 3D point cloud modalities demonstrate that Adapter-X represents a significant milestone as it is the first to outperform full fine-tuning in both 2D image and 3D point cloud modalities with significantly fewer parameters, i.e., only 0.20% and 1.88% of original trainable parameters for 2D and 3D classification tasks. Our code will be publicly available.
MotionChain: Conversational Motion Controllers via Multimodal Prompts
Apr 03, 2024



Recent advancements in language models have demonstrated their adeptness in conducting multi-turn dialogues and retaining conversational context. However, this proficiency remains largely unexplored in other multimodal generative models, particularly in human motion models. By integrating multi-turn conversations in controlling continuous virtual human movements, generative human motion models can achieve an intuitive and step-by-step process of human task execution for humanoid robotics, game agents, or other embodied systems. In this work, we present MotionChain, a conversational human motion controller to generate continuous and long-term human motion through multimodal prompts. Specifically, MotionChain consists of multi-modal tokenizers that transform various data types such as text, image, and motion, into discrete tokens, coupled with a Vision-Motion-aware Language model. By leveraging large-scale language, vision-language, and vision-motion data to assist motion-related generation tasks, MotionChain thus comprehends each instruction in multi-turn conversation and generates human motions followed by these prompts. Extensive experiments validate the efficacy of MotionChain, demonstrating state-of-the-art performance in conversational motion generation, as well as more intuitive manners of controlling and interacting with virtual humans.
MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies
Mar 03, 2024
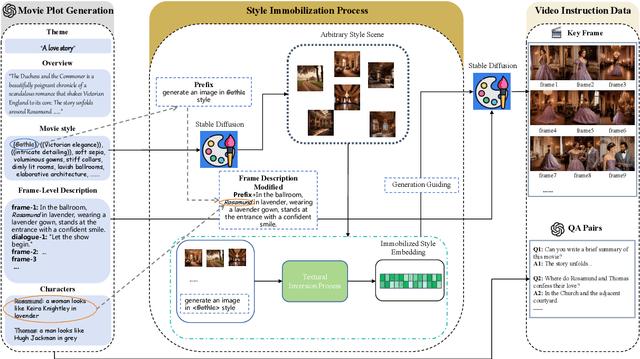
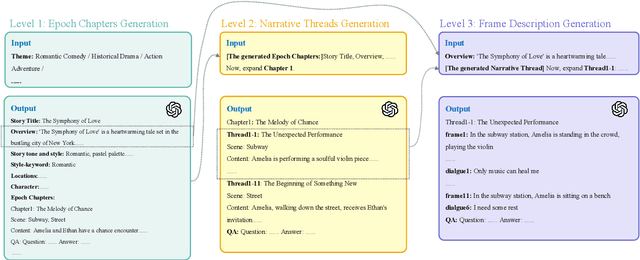
The development of multimodal models has marked a significant step forward in how machines understand videos. These models have shown promise in analyzing short video clips. However, when it comes to longer formats like movies, they often fall short. The main hurdles are the lack of high-quality, diverse video data and the intensive work required to collect or annotate such data. In the face of these challenges, we propose MovieLLM, a novel framework designed to create synthetic, high-quality data for long videos. This framework leverages the power of GPT-4 and text-to-image models to generate detailed scripts and corresponding visuals. Our approach stands out for its flexibility and scalability, making it a superior alternative to traditional data collection methods. Our extensive experiments validate that the data produced by MovieLLM significantly improves the performance of multimodal models in understanding complex video narratives, overcoming the limitations of existing datasets regarding scarcity and bias.
Rethinking of Feature Interaction for Multi-task Learning on Dense Prediction
Dec 21, 2023



Existing works generally adopt the encoder-decoder structure for Multi-task Dense Prediction, where the encoder extracts the task-generic features, and multiple decoders generate task-specific features for predictions. We observe that low-level representations with rich details and high-level representations with abundant task information are not both involved in the multi-task interaction process. Additionally, low-quality and low-efficiency issues also exist in current multi-task learning architectures. In this work, we propose to learn a comprehensive intermediate feature globally from both task-generic and task-specific features, we reveal an important fact that this intermediate feature, namely the bridge feature, is a good solution to the above issues. Based on this, we propose a novel Bridge-Feature-Centirc Interaction (BRFI) method. A Bridge Feature Extractor (BFE) is designed for the generation of strong bridge features and Task Pattern Propagation (TPP) is applied to ensure high-quality task interaction participants. Then a Task-Feature Refiner (TFR) is developed to refine final task predictions with the well-learned knowledge from the bridge features. Extensive experiments are conducted on NYUD-v2 and PASCAL Context benchmarks, and the superior performance shows the proposed architecture is effective and powerful in promoting different dense prediction tasks simultaneously.
ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model
Dec 01, 2023



The advent of large language models, enabling flexibility through instruction-driven approaches, has revolutionized many traditional generative tasks, but large models for 3D data, particularly in comprehensively handling 3D shapes with other modalities, are still under-explored. By achieving instruction-based shape generations, versatile multimodal generative shape models can significantly benefit various fields like 3D virtual construction and network-aided design. In this work, we present ShapeGPT, a shape-included multi-modal framework to leverage strong pre-trained language models to address multiple shape-relevant tasks. Specifically, ShapeGPT employs a word-sentence-paragraph framework to discretize continuous shapes into shape words, further assembles these words for shape sentences, as well as integrates shape with instructional text for multi-modal paragraphs. To learn this shape-language model, we use a three-stage training scheme, including shape representation, multimodal alignment, and instruction-based generation, to align shape-language codebooks and learn the intricate correlations among these modalities. Extensive experiments demonstrate that ShapeGPT achieves comparable performance across shape-relevant tasks, including text-to-shape, shape-to-text, shape completion, and shape editing.
LL3DA: Visual Interactive Instruction Tuning for Omni-3D Understanding, Reasoning, and Planning
Nov 30, 2023


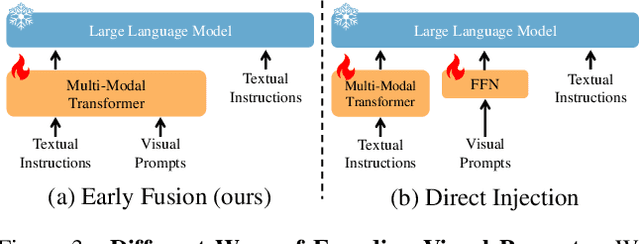
Recent advances in Large Multimodal Models (LMM) have made it possible for various applications in human-machine interactions. However, developing LMMs that can comprehend, reason, and plan in complex and diverse 3D environments remains a challenging topic, especially considering the demand for understanding permutation-invariant point cloud 3D representations of the 3D scene. Existing works seek help from multi-view images, and project 2D features to 3D space as 3D scene representations. This, however, leads to huge computational overhead and performance degradation. In this paper, we present LL3DA, a Large Language 3D Assistant that takes point cloud as direct input and respond to both textual-instructions and visual-prompts. This help LMMs better comprehend human interactions and further help to remove the ambiguities in cluttered 3D scenes. Experiments show that LL3DA achieves remarkable results, and surpasses various 3D vision-language models on both 3D Dense Captioning and 3D Question Answering.