 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLenslessFace: An End-to-End Optimized Lensless System for Privacy-Preserving Face Verification
Jun 06, 2024



Lensless cameras, innovatively replacing traditional lenses for ultra-thin, flat optics, encode light directly onto sensors, producing images that are not immediately recognizable. This compact, lightweight, and cost-effective imaging solution offers inherent privacy advantages, making it attractive for privacy-sensitive applications like face verification. Typical lensless face verification adopts a two-stage process of reconstruction followed by verification, incurring privacy risks from reconstructed faces and high computational costs. This paper presents an end-to-end optimization approach for privacy-preserving face verification directly on encoded lensless captures, ensuring that the entire software pipeline remains encoded with no visible faces as intermediate results. To achieve this, we propose several techniques to address unique challenges from the lensless setup which precludes traditional face detection and alignment. Specifically, we propose a face center alignment scheme, an augmentation curriculum to build robustness against variations, and a knowledge distillation method to smooth optimization and enhance performance. Evaluations under both simulation and real environment demonstrate our method outperforms two-stage lensless verification while enhancing privacy and efficiency. Project website: \url{lenslessface.github.io}.
MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies
Mar 03, 2024
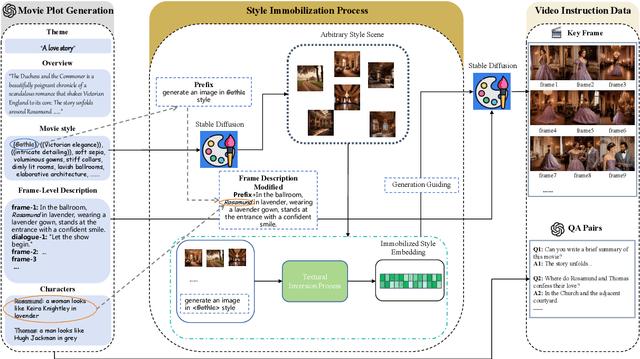
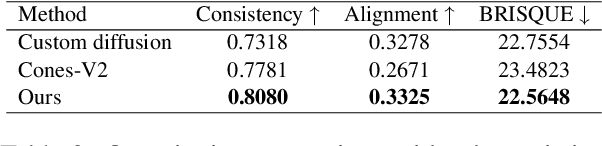
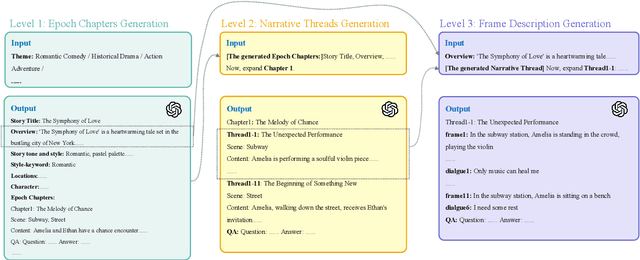
The development of multimodal models has marked a significant step forward in how machines understand videos. These models have shown promise in analyzing short video clips. However, when it comes to longer formats like movies, they often fall short. The main hurdles are the lack of high-quality, diverse video data and the intensive work required to collect or annotate such data. In the face of these challenges, we propose MovieLLM, a novel framework designed to create synthetic, high-quality data for long videos. This framework leverages the power of GPT-4 and text-to-image models to generate detailed scripts and corresponding visuals. Our approach stands out for its flexibility and scalability, making it a superior alternative to traditional data collection methods. Our extensive experiments validate that the data produced by MovieLLM significantly improves the performance of multimodal models in understanding complex video narratives, overcoming the limitations of existing datasets regarding scarcity and bias.