 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyRecon: Arbitrary-View 3D Reconstruction with Video Diffusion Model
Apr 21, 2026Sparse-view 3D reconstruction is essential for modeling scenes from casual captures, but remain challenging for non-generative reconstruction. Existing diffusion-based approaches mitigates this issues by synthesizing novel views, but they often condition on only one or two capture frames, which restricts geometric consistency and limits scalability to large or diverse scenes. We propose AnyRecon, a scalable framework for reconstruction from arbitrary and unordered sparse inputs that preserves explicit geometric control while supporting flexible conditioning cardinality. To support long-range conditioning, our method constructs a persistent global scene memory via a prepended capture view cache, and removes temporal compression to maintain frame-level correspondence under large viewpoint changes. Beyond better generative model, we also find that the interplay between generation and reconstruction is crucial for large-scale 3D scenes. Thus, we introduce a geometry-aware conditioning strategy that couples generation and reconstruction through an explicit 3D geometric memory and geometry-driven capture-view retrieval. To ensure efficiency, we combine 4-step diffusion distillation with context-window sparse attention to reduce quadratic complexity. Extensive experiments demonstrate robust and scalable reconstruction across irregular inputs, large viewpoint gaps, and long trajectories.
DA-VAE: Plug-in Latent Compression for Diffusion via Detail Alignment
Mar 23, 2026Reducing token count is crucial for efficient training and inference of latent diffusion models, especially at high resolution. A common strategy is to build high-compression image tokenizers with more channels per token. However, when trained only for reconstruction, high-dimensional latent spaces often lose meaningful structure, making diffusion training harder. Existing methods address this with extra objectives such as semantic alignment or selective dropout, but usually require costly diffusion retraining. Pretrained diffusion models, however, already exhibit a structured, lower-dimensional latent space; thus, a simpler idea is to expand the latent dimensionality while preserving this structure. We therefore propose \textbf{D}etail-\textbf{A}ligned VAE, which increases the compression ratio of a pretrained VAE with only lightweight adaptation of the pretrained diffusion backbone. DA-VAE uses an explicit latent layout: the first $C$ channels come directly from the pretrained VAE at a base resolution, while an additional $D$ channels encode higher-resolution details. A simple detail-alignment mechanism encourages the expanded latent space to retain the structure of the original one. With a warm-start fine-tuning strategy, our method enables $1024 \times 1024$ image generation with Stable Diffusion 3.5 using only $32 \times 32$ tokens, $4\times$ fewer than the original model, within 5 H100-days. It further unlocks $2048 \times 2048$ generation with SD3.5, achieving a $6\times$ speedup while preserving image quality. We also validate the method and its design choices quantitatively on ImageNet.
MindDriver: Introducing Progressive Multimodal Reasoning for Autonomous Driving
Feb 25, 2026Vision-Language Models (VLM) exhibit strong reasoning capabilities, showing promise for end-to-end autonomous driving systems. Chain-of-Thought (CoT), as VLM's widely used reasoning strategy, is facing critical challenges. Existing textual CoT has a large gap between text semantic space and trajectory physical space. Although the recent approach utilizes future image to replace text as CoT process, it lacks clear planning-oriented objective guidance to generate images with accurate scene evolution. To address these, we innovatively propose MindDriver, a progressive multimodal reasoning framework that enables VLM to imitate human-like progressive thinking for autonomous driving. MindDriver presents semantic understanding, semantic-to-physical space imagination, and physical-space trajectory planning. To achieve aligned reasoning processes in MindDriver, we develop a feedback-guided automatic data annotation pipeline to generate aligned multimodal reasoning training data. Furthermore, we develop a progressive reinforcement fine-tuning method to optimize the alignment through progressive high- level reward-based learning. MindDriver demonstrates superior performance in both nuScences open-loop and Bench2Drive closed-loop evaluation. Codes are available at https://github.com/hotdogcheesewhite/MindDriver.
FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution
Oct 14, 2025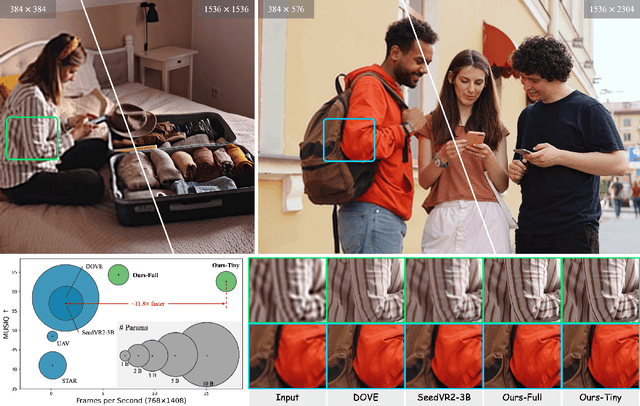
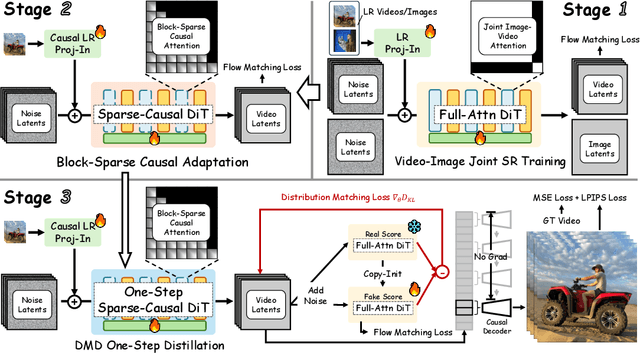
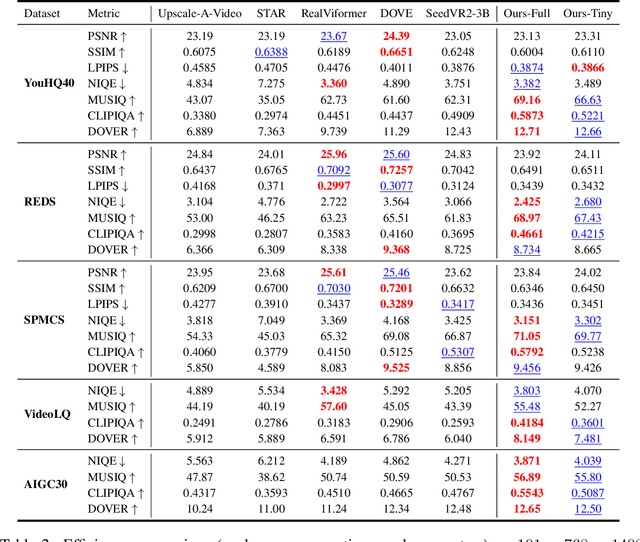
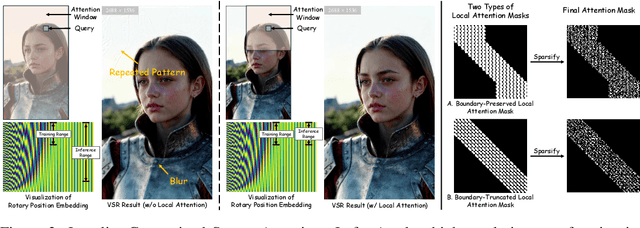
Diffusion models have recently advanced video restoration, but applying them to real-world video super-resolution (VSR) remains challenging due to high latency, prohibitive computation, and poor generalization to ultra-high resolutions. Our goal in this work is to make diffusion-based VSR practical by achieving efficiency, scalability, and real-time performance. To this end, we propose FlashVSR, the first diffusion-based one-step streaming framework towards real-time VSR. FlashVSR runs at approximately 17 FPS for 768x1408 videos on a single A100 GPU by combining three complementary innovations: (i) a train-friendly three-stage distillation pipeline that enables streaming super-resolution, (ii) locality-constrained sparse attention that cuts redundant computation while bridging the train-test resolution gap, and (iii) a tiny conditional decoder that accelerates reconstruction without sacrificing quality. To support large-scale training, we also construct VSR-120K, a new dataset with 120k videos and 180k images. Extensive experiments show that FlashVSR scales reliably to ultra-high resolutions and achieves state-of-the-art performance with up to 12x speedup over prior one-step diffusion VSR models. We will release the code, pretrained models, and dataset to foster future research in efficient diffusion-based VSR.
RubikSQL: Lifelong Learning Agentic Knowledge Base as an Industrial NL2SQL System
Aug 25, 2025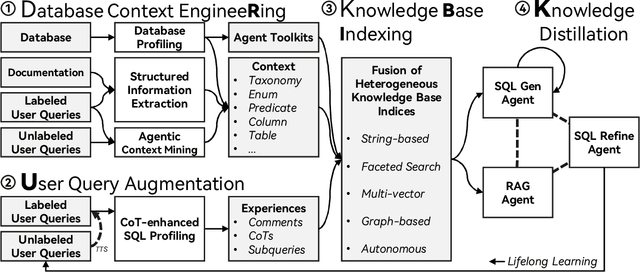
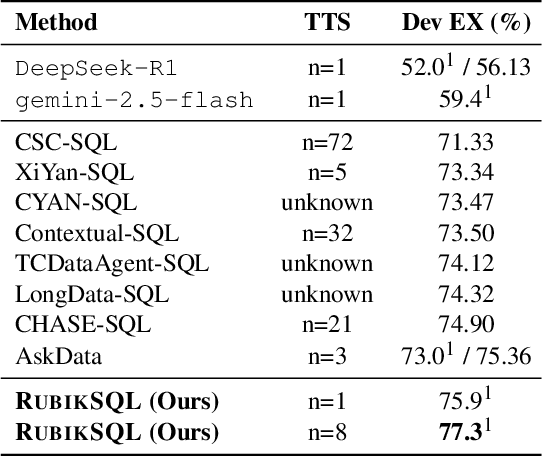
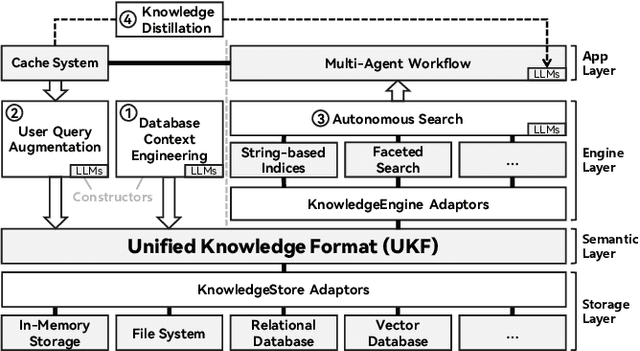
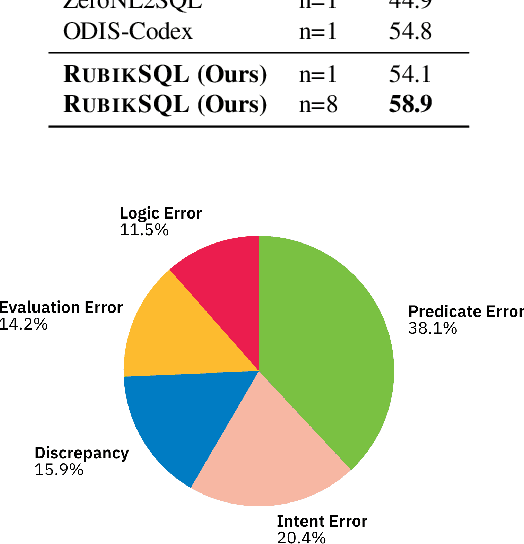
We present RubikSQL, a novel NL2SQL system designed to address key challenges in real-world enterprise-level NL2SQL, such as implicit intents and domain-specific terminology. RubikSQL frames NL2SQL as a lifelong learning task, demanding both Knowledge Base (KB) maintenance and SQL generation. RubikSQL systematically builds and refines its KB through techniques including database profiling, structured information extraction, agentic rule mining, and Chain-of-Thought (CoT)-enhanced SQL profiling. RubikSQL then employs a multi-agent workflow to leverage this curated KB, generating accurate SQLs. RubikSQL achieves SOTA performance on both the KaggleDBQA and BIRD Mini-Dev datasets. Finally, we release the RubikBench benchmark, a new benchmark specifically designed to capture vital traits of industrial NL2SQL scenarios, providing a valuable resource for future research.
LoRA-Edit: Controllable First-Frame-Guided Video Editing via Mask-Aware LoRA Fine-Tuning
Jun 11, 2025Video editing using diffusion models has achieved remarkable results in generating high-quality edits for videos. However, current methods often rely on large-scale pretraining, limiting flexibility for specific edits. First-frame-guided editing provides control over the first frame, but lacks flexibility over subsequent frames. To address this, we propose a mask-based LoRA (Low-Rank Adaptation) tuning method that adapts pretrained Image-to-Video (I2V) models for flexible video editing. Our approach preserves background regions while enabling controllable edits propagation. This solution offers efficient and adaptable video editing without altering the model architecture. To better steer this process, we incorporate additional references, such as alternate viewpoints or representative scene states, which serve as visual anchors for how content should unfold. We address the control challenge using a mask-driven LoRA tuning strategy that adapts a pre-trained image-to-video model to the editing context. The model must learn from two distinct sources: the input video provides spatial structure and motion cues, while reference images offer appearance guidance. A spatial mask enables region-specific learning by dynamically modulating what the model attends to, ensuring that each area draws from the appropriate source. Experimental results show our method achieves superior video editing performance compared to state-of-the-art methods.
One Framework to Rule Them All: Unifying RL-Based and RL-Free Methods in RLHF
Mar 26, 2025
In this article, we primarily examine a variety of RL-based and RL-free methods designed to address Reinforcement Learning from Human Feedback (RLHF) and Large Reasoning Models (LRMs). We begin with a concise overview of the typical steps involved in RLHF and LRMs. Next, we reinterpret several RL-based and RL-free algorithms through the perspective of neural structured bandit prediction, providing a clear conceptual framework that uncovers a deeper connection between these seemingly distinct approaches. Following this, we briefly review some core principles of reinforcement learning, drawing attention to an often-overlooked aspect in existing RLHF studies. This leads to a detailed derivation of the standard RLHF objective within a full RL context, demonstrating its equivalence to neural structured bandit prediction. Finally, by reinvestigating the principles behind Proximal Policy Optimization (PPO), we pinpoint areas needing adjustment, which culminates in the introduction of the Generalized Reinforce Optimization (GRO) framework, seamlessly integrating RL-based and RL-free methods in RLHF. We look forward to the community's efforts to empirically validate GRO and invite constructive feedback.
UltraFusion: Ultra High Dynamic Imaging using Exposure Fusion
Jan 20, 2025



Capturing high dynamic range (HDR) scenes is one of the most important issues in camera design. Majority of cameras use exposure fusion technique, which fuses images captured by different exposure levels, to increase dynamic range. However, this approach can only handle images with limited exposure difference, normally 3-4 stops. When applying to very high dynamic scenes where a large exposure difference is required, this approach often fails due to incorrect alignment or inconsistent lighting between inputs, or tone mapping artifacts. In this work, we propose UltraFusion, the first exposure fusion technique that can merge input with 9 stops differences. The key idea is that we model the exposure fusion as a guided inpainting problem, where the under-exposed image is used as a guidance to fill the missing information of over-exposed highlight in the over-exposed region. Using under-exposed image as a soft guidance, instead of a hard constrain, our model is robust to potential alignment issue or lighting variations. Moreover, utilizing the image prior of the generative model, our model also generates natural tone mapping, even for very high-dynamic range scene. Our approach outperforms HDR-Transformer on latest HDR benchmarks. Moreover, to test its performance in ultra high dynamic range scene, we capture a new real-world exposure fusion benchmark, UltraFusion Dataset, with exposure difference up to 9 stops, and experiments show that \model~can generate beautiful and high-quality fusion results under various scenarios. An online demo is provided at https://openimaginglab.github.io/UltraFusion/.
Teaching Large Language Models to Regress Accurate Image Quality Scores using Score Distribution
Jan 20, 2025



With the rapid advancement of Multi-modal Large Language Models (MLLMs), MLLM-based Image Quality Assessment (IQA) methods have shown promising performance in linguistic quality description. However, current methods still fall short in accurately scoring image quality. In this work, we aim to leverage MLLMs to regress accurate quality scores. A key challenge is that the quality score is inherently continuous, typically modeled as a Gaussian distribution, whereas MLLMs generate discrete token outputs. This mismatch necessitates score discretization. Previous approaches discretize the mean score into a one-hot label, resulting in information loss and failing to capture inter-image relationships. We propose a distribution-based approach that discretizes the score distribution into a soft label. This method preserves the characteristics of the score distribution, achieving high accuracy and maintaining inter-image relationships. Moreover, to address dataset variation, where different IQA datasets exhibit various distributions, we introduce a fidelity loss based on Thurstone's model. This loss captures intra-dataset relationships, facilitating co-training across multiple IQA datasets. With these designs, we develop the distribution-based Depicted image Quality Assessment model for Score regression (DeQA-Score). Experiments across multiple benchmarks show that DeQA-Score stably outperforms baselines in score regression. Also, DeQA-Score can predict the score distribution that closely aligns with human annotations. Codes and model weights have been released in https://depictqa.github.io/deqa-score/.
DetailGen3D: Generative 3D Geometry Enhancement via Data-Dependent Flow
Nov 25, 2024Modern 3D generation methods can rapidly create shapes from sparse or single views, but their outputs often lack geometric detail due to computational constraints. We present DetailGen3D, a generative approach specifically designed to enhance these generated 3D shapes. Our key insight is to model the coarse-to-fine transformation directly through data-dependent flows in latent space, avoiding the computational overhead of large-scale 3D generative models. We introduce a token matching strategy that ensures accurate spatial correspondence during refinement, enabling local detail synthesis while preserving global structure. By carefully designing our training data to match the characteristics of synthesized coarse shapes, our method can effectively enhance shapes produced by various 3D generation and reconstruction approaches, from single-view to sparse multi-view inputs. Extensive experiments demonstrate that DetailGen3D achieves high-fidelity geometric detail synthesis while maintaining efficiency in training.