 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimaX: Animating the Inanimate in 3D with Joint Video-Pose Diffusion Models
Jun 24, 2025We present AnimaX, a feed-forward 3D animation framework that bridges the motion priors of video diffusion models with the controllable structure of skeleton-based animation. Traditional motion synthesis methods are either restricted to fixed skeletal topologies or require costly optimization in high-dimensional deformation spaces. In contrast, AnimaX effectively transfers video-based motion knowledge to the 3D domain, supporting diverse articulated meshes with arbitrary skeletons. Our method represents 3D motion as multi-view, multi-frame 2D pose maps, and enables joint video-pose diffusion conditioned on template renderings and a textual motion prompt. We introduce shared positional encodings and modality-aware embeddings to ensure spatial-temporal alignment between video and pose sequences, effectively transferring video priors to motion generation task. The resulting multi-view pose sequences are triangulated into 3D joint positions and converted into mesh animation via inverse kinematics. Trained on a newly curated dataset of 160,000 rigged sequences, AnimaX achieves state-of-the-art results on VBench in generalization, motion fidelity, and efficiency, offering a scalable solution for category-agnostic 3D animation. Project page: \href{https://anima-x.github.io/}{https://anima-x.github.io/}.
DetailGen3D: Generative 3D Geometry Enhancement via Data-Dependent Flow
Nov 25, 2024Modern 3D generation methods can rapidly create shapes from sparse or single views, but their outputs often lack geometric detail due to computational constraints. We present DetailGen3D, a generative approach specifically designed to enhance these generated 3D shapes. Our key insight is to model the coarse-to-fine transformation directly through data-dependent flows in latent space, avoiding the computational overhead of large-scale 3D generative models. We introduce a token matching strategy that ensures accurate spatial correspondence during refinement, enabling local detail synthesis while preserving global structure. By carefully designing our training data to match the characteristics of synthesized coarse shapes, our method can effectively enhance shapes produced by various 3D generation and reconstruction approaches, from single-view to sparse multi-view inputs. Extensive experiments demonstrate that DetailGen3D achieves high-fidelity geometric detail synthesis while maintaining efficiency in training.
LineNet: a Zoomable CNN for Crowdsourced High Definition Maps Modeling in Urban Environments
Jul 16, 2018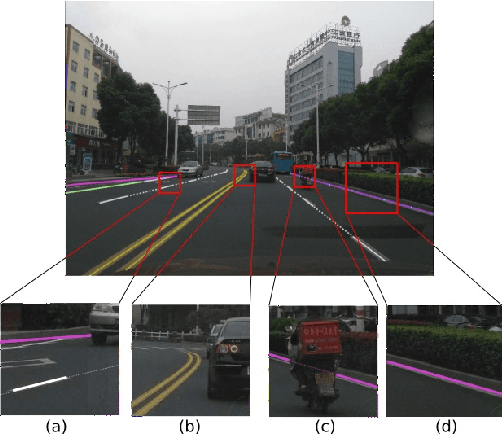
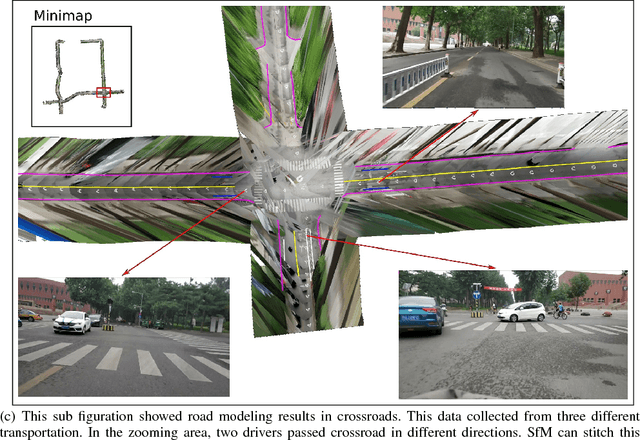
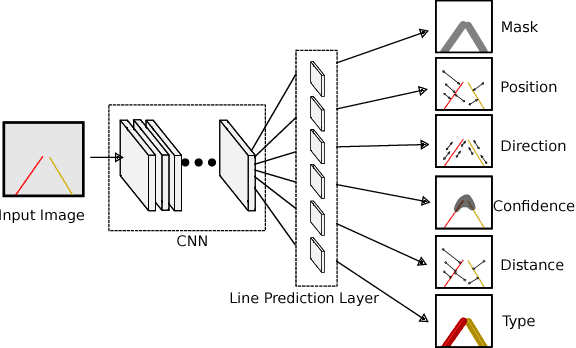
High Definition (HD) maps play an important role in modern traffic scenes. However, the development of HD maps coverage grows slowly because of the cost limitation. To efficiently model HD maps, we proposed a convolutional neural network with a novel prediction layer and a zoom module, called LineNet. It is designed for state-of-the-art lane detection in an unordered crowdsourced image dataset. And we introduced TTLane, a dataset for efficient lane detection in urban road modeling applications. Combining LineNet and TTLane, we proposed a pipeline to model HD maps with crowdsourced data for the first time. And the maps can be constructed precisely even with inaccurate crowdsourced data.