 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre we ready for a new paradigm shift? A Survey on Visual Deep MLP
Nov 23, 2021



Multilayer perceptron (MLP), as the first neural network structure to appear, was a big hit. But constrained by the hardware computing power and the size of the datasets, it once sank for tens of years. During this period, we have witnessed a paradigm shift from manual feature extraction to the CNN with local receptive field, and further to the Transformer with global receptive field based on self-attention mechanism. And this year (2021), with the introduction of MLP-Mixer, MLP has re-entered the limelight and has attracted extensive research from the computer vision community. Compare to the conventional MLP, it gets deeper but changes the input from full flattening to patch flattening. Given its high performance and less need for vision-specific inductive bias, the community can't help but wonder, \emph{Will deep MLP, the simplest structure with global receptive field but no attention, become a new computer vision paradigm}? To answer this question, this survey aims to provide a comprehensive overview of the recent development of deep MLP models in vision. Specifically, we review these MLPs in detail, from the subtle sub-module design to the global network structure. We compare the receptive field, computational complexity, and other properties of different network designs in order to understand the development path of MLPs clearly. The investigation shows that MLPs' resolution-sensitivity and computational densities remain unresolved, and pure MLPs are gradually evolving towards CNN-like. We suggest that the current data volume and computational power are not ready to embrace pure MLPs, and artificial visual guidance remains important. Finally, we provide our viewpoint about open research directions and potential future works. We hope this effort will ignite further interest in the community and encourage better visual tailored design for the neural network in the future.
Can Attention Enable MLPs To Catch Up With CNNs?
May 31, 2021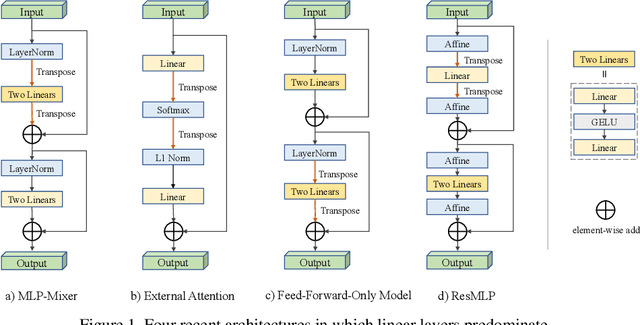
In the first week of May, 2021, researchers from four different institutions: Google, Tsinghua University, Oxford University and Facebook, shared their latest work [16, 7, 12, 17] on arXiv.org almost at the same time, each proposing new learning architectures, consisting mainly of linear layers, claiming them to be comparable, or even superior to convolutional-based models. This sparked immediate discussion and debate in both academic and industrial communities as to whether MLPs are sufficient, many thinking that learning architectures are returning to MLPs. Is this true? In this perspective, we give a brief history of learning architectures, including multilayer perceptrons (MLPs), convolutional neural networks (CNNs) and transformers. We then examine what the four newly proposed architectures have in common. Finally, we give our views on challenges and directions for new learning architectures, hoping to inspire future research.
Recursive-NeRF: An Efficient and Dynamically Growing NeRF
May 19, 2021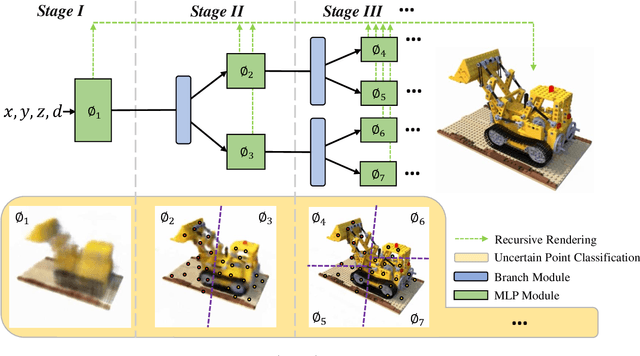

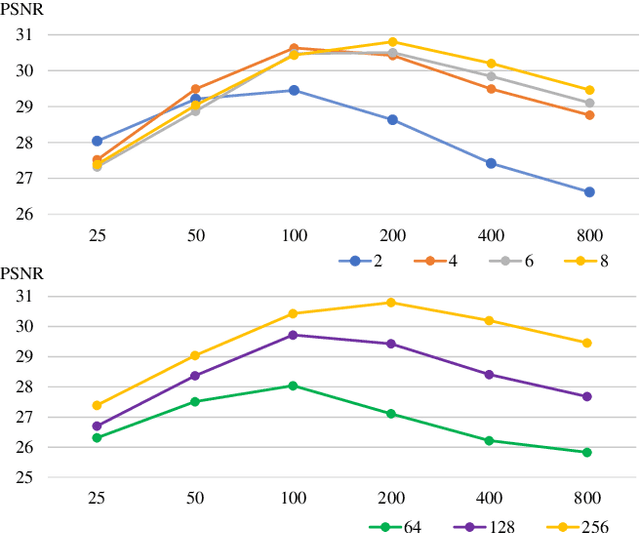
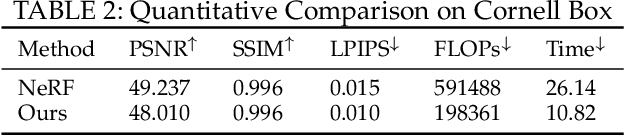
View synthesis methods using implicit continuous shape representations learned from a set of images, such as the Neural Radiance Field (NeRF) method, have gained increasing attention due to their high quality imagery and scalability to high resolution. However, the heavy computation required by its volumetric approach prevents NeRF from being useful in practice; minutes are taken to render a single image of a few megapixels. Now, an image of a scene can be rendered in a level-of-detail manner, so we posit that a complicated region of the scene should be represented by a large neural network while a small neural network is capable of encoding a simple region, enabling a balance between efficiency and quality. Recursive-NeRF is our embodiment of this idea, providing an efficient and adaptive rendering and training approach for NeRF. The core of Recursive-NeRF learns uncertainties for query coordinates, representing the quality of the predicted color and volumetric intensity at each level. Only query coordinates with high uncertainties are forwarded to the next level to a bigger neural network with a more powerful representational capability. The final rendered image is a composition of results from neural networks of all levels. Our evaluation on three public datasets shows that Recursive-NeRF is more efficient than NeRF while providing state-of-the-art quality. The code will be available at https://github.com/Gword/Recursive-NeRF.
What and Where: A Context-based Recommendation System for Object Insertion
Nov 24, 2018

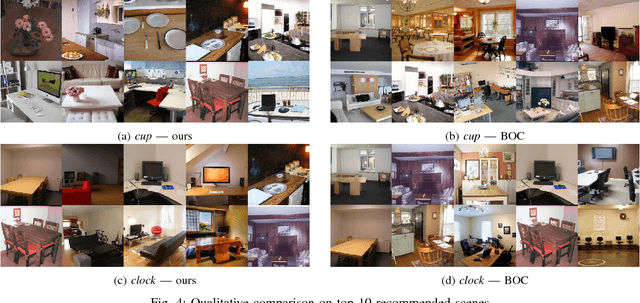

In this work, we propose a novel topic consisting of two dual tasks: 1) given a scene, recommend objects to insert, 2) given an object category, retrieve suitable background scenes. A bounding box for the inserted object is predicted in both tasks, which helps downstream applications such as semi-automated advertising and video composition. The major challenge lies in the fact that the target object is neither present nor localized at test time, whereas available datasets only provide scenes with existing objects. To tackle this problem, we build an unsupervised algorithm based on object-level contexts, which explicitly models the joint probability distribution of object categories and bounding boxes with a Gaussian mixture model. Experiments on our newly annotated test set demonstrate that our system outperforms existing baselines on all subtasks, and do so under a unified framework. Our contribution promises future extensions and applications.
LineNet: a Zoomable CNN for Crowdsourced High Definition Maps Modeling in Urban Environments
Jul 16, 2018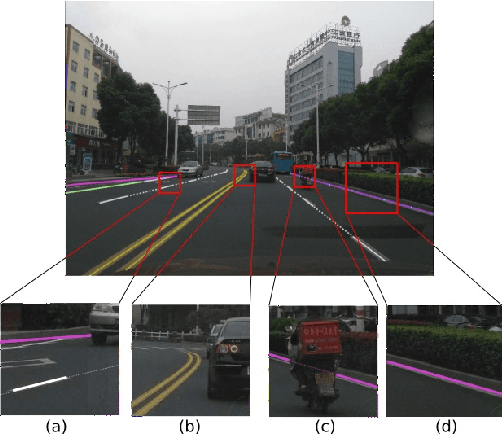
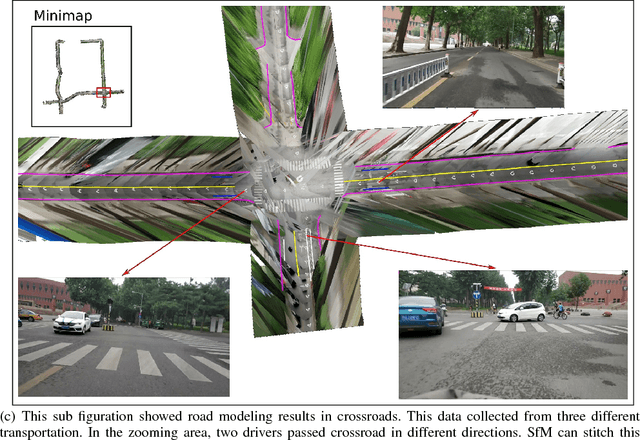
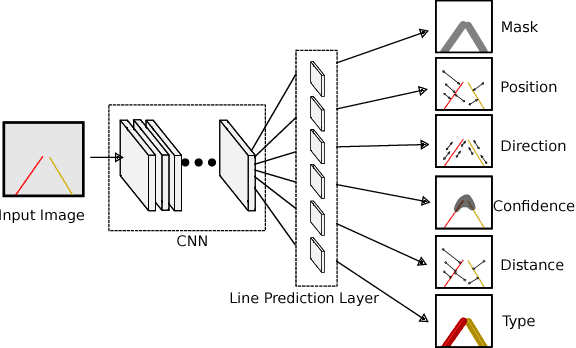
High Definition (HD) maps play an important role in modern traffic scenes. However, the development of HD maps coverage grows slowly because of the cost limitation. To efficiently model HD maps, we proposed a convolutional neural network with a novel prediction layer and a zoom module, called LineNet. It is designed for state-of-the-art lane detection in an unordered crowdsourced image dataset. And we introduced TTLane, a dataset for efficient lane detection in urban road modeling applications. Combining LineNet and TTLane, we proposed a pipeline to model HD maps with crowdsourced data for the first time. And the maps can be constructed precisely even with inaccurate crowdsourced data.