 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytic Convolutional Layer: A Step to Analytic Neural Network
Jul 03, 2024



The prevailing approach to embedding prior knowledge within convolutional layers typically includes the design of steerable kernels or their modulation using designated kernel banks. In this study, we introduce the Analytic Convolutional Layer (ACL), an innovative model-driven convolutional layer, which is a mosaic of analytical convolution kernels (ACKs) and traditional convolution kernels. ACKs are characterized by mathematical functions governed by analytic kernel parameters (AKPs) learned in training process. Learnable AKPs permit the adaptive update of incorporated knowledge to align with the features representation of data. Our extensive experiments demonstrate that the ACLs not only have a remarkable capacity for feature representation with a reduced number of parameters but also attain increased reliability through the analytical formulation of ACKs. Furthermore, ACLs offer a means for neural network interpretation, thereby paving the way for the intrinsic interpretability of neural network. The source code will be published in company with the paper.
Applications of Tao General Difference in Discrete Domain
Jan 27, 2024Numerical difference computation is one of the cores and indispensable in the modern digital era. Tao general difference (TGD) is a novel theory and approach to difference computation for discrete sequences and arrays in multidimensional space. Built on the solid theoretical foundation of the general difference in a finite interval, the TGD operators demonstrate exceptional signal processing capabilities in real-world applications. A novel smoothness property of a sequence is defined on the first- and second TGD. This property is used to denoise one-dimensional signals, where the noise is the non-smooth points in the sequence. Meanwhile, the center of the gradient in a finite interval can be accurately location via TGD calculation. This solves a traditional challenge in computer vision, which is the precise localization of image edges with noise robustness. Furthermore, the power of TGD operators extends to spatio-temporal edge detection in three-dimensional arrays, enabling the identification of kinetic edges in video data. These diverse applications highlight the properties of TGD in discrete domain and the significant promise of TGD for the computation across signal processing, image analysis, and video analytic.
The changing rule of human bone density with aging based on a novel definition and mensuration of bone density with computed tomography
Aug 05, 2023

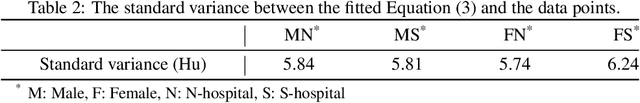
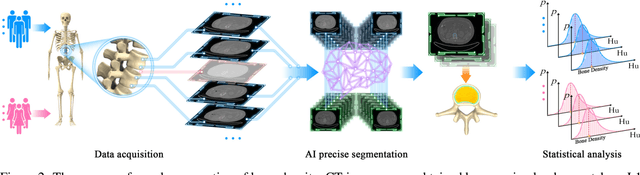
Osteoporosis and fragility fractures have emerged as major public health concerns in an aging population. However, measuring age-related changes in bone density using dual-energy X-ray absorptiometry has limited personalized risk assessment due to susceptibility to interference from various factors. In this study, we propose an innovative statistical model of bone pixel distribution in fine-segmented computed tomography (CT) images, along with a novel approach to measuring bone density based on CT values of bone pixels. Our findings indicate that bone density exhibits a linear decline with age during adulthood between the ages of 39 and 80, with the rate of decline being approximately 1.6 times faster in women than in men. This contradicts the widely accepted notion that bone density starts declining in women at menopause and in men at around 50 years of age. The linearity of age-related changes provides further insights into the dynamics of the aging human body. Consequently, our findings suggest that the definition of osteoporosis by the World Health Organization should be revised to the standard deviation of age-based bone density. Furthermore, these results open up new avenues for research in bone health care and clinical investigation of osteoporosis.
Tao General Differential and Difference: Theory and Application
May 14, 2023Modern numerical analysis is executed on discrete data, of which numerical difference computation is one of the cores and is indispensable. Nevertheless, difference algorithms have a critical weakness in their sensitivity to noise, which has long posed a challenge in various fields including signal processing. Difference is an extension or generalization of differential in the discrete domain. However, due to the finite interval in discrete calculation, there is a failure in meeting the most fundamental definition of differential, where dy and dx are both infinitesimal (Leibniz) or the limit of dx is 0 (Cauchy). In this regard, the generalization of differential to difference does not hold. To address this issue, we depart from the original derivative approach, construct a finite interval-based differential, and further generalize it to obtain the difference by convolution. Based on this theory, we present a variety of difference operators suitable for practical signal processing. Experimental results demonstrate that these difference operators possess exceptional signal processing capabilities, including high noise immunity.
Are we ready for a new paradigm shift? A Survey on Visual Deep MLP
Nov 23, 2021



Multilayer perceptron (MLP), as the first neural network structure to appear, was a big hit. But constrained by the hardware computing power and the size of the datasets, it once sank for tens of years. During this period, we have witnessed a paradigm shift from manual feature extraction to the CNN with local receptive field, and further to the Transformer with global receptive field based on self-attention mechanism. And this year (2021), with the introduction of MLP-Mixer, MLP has re-entered the limelight and has attracted extensive research from the computer vision community. Compare to the conventional MLP, it gets deeper but changes the input from full flattening to patch flattening. Given its high performance and less need for vision-specific inductive bias, the community can't help but wonder, \emph{Will deep MLP, the simplest structure with global receptive field but no attention, become a new computer vision paradigm}? To answer this question, this survey aims to provide a comprehensive overview of the recent development of deep MLP models in vision. Specifically, we review these MLPs in detail, from the subtle sub-module design to the global network structure. We compare the receptive field, computational complexity, and other properties of different network designs in order to understand the development path of MLPs clearly. The investigation shows that MLPs' resolution-sensitivity and computational densities remain unresolved, and pure MLPs are gradually evolving towards CNN-like. We suggest that the current data volume and computational power are not ready to embrace pure MLPs, and artificial visual guidance remains important. Finally, we provide our viewpoint about open research directions and potential future works. We hope this effort will ignite further interest in the community and encourage better visual tailored design for the neural network in the future.
Adversarial Attack Driven Data Augmentation for Accurate And Robust Medical Image Segmentation
May 25, 2021



Segmentation is considered to be a very crucial task in medical image analysis. This task has been easier since deep learning models have taken over with its high performing behavior. However, deep learning models dependency on large data proves it to be an obstacle in medical image analysis because of insufficient data samples. Several data augmentation techniques have been used to mitigate this problem. We propose a new augmentation method by introducing adversarial learning attack techniques, specifically Fast Gradient Sign Method (FGSM). Furthermore, We have also introduced the concept of Inverse FGSM (InvFGSM), which works in the opposite manner of FGSM for the data augmentation. This two approaches worked together to improve the segmentation accuracy, as well as helped the model to gain robustness against adversarial attacks. The overall analysis of experiments indicates a novel use of adversarial machine learning along with robustness enhancement.
Towards All-around Knowledge Transferring: Learning From Task-irrelevant Labels
Nov 17, 2020



Deep neural models have hitherto achieved significant performances on numerous classification tasks, but meanwhile require sufficient manually annotated data. Since it is extremely time-consuming and expensive to annotate adequate data for each classification task, learning an empirically effective model with generalization on small dataset has received increased attention. Existing efforts mainly focus on transferring task-relevant knowledge from other similar data to tackle the issue. These approaches have yielded remarkable improvements, yet neglecting the fact that the task-irrelevant features could bring out massive negative transfer effects. To date, no large-scale studies have been performed to investigate the impact of task-irrelevant features, let alone the utilization of this kind of features. In this paper, we firstly propose Task-Irrelevant Transfer Learning (TIRTL) to exploit task-irrelevant features, which mainly are extracted from task-irrelevant labels. Particularly, we suppress the expression of task-irrelevant information and facilitate the learning process of classification. We also provide a theoretical explanation of our method. In addition, TIRTL does not conflict with those that have previously exploited task-relevant knowledge and can be well combined to enable the simultaneous utilization of task-relevant and task-irrelevant features for the first time. In order to verify the effectiveness of our theory and method, we conduct extensive experiments on facial expression recognition and digit recognition tasks. Our source code will be also available in the future for reproducibility.