 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarmageNet: A Dataset and Scalable Representation for Generic Garment Modeling
Apr 02, 2025

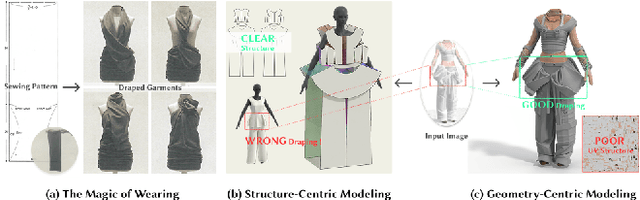
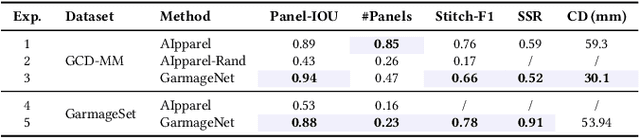
High-fidelity garment modeling remains challenging due to the lack of large-scale, high-quality datasets and efficient representations capable of handling non-watertight, multi-layer geometries. In this work, we introduce Garmage, a neural-network-and-CG-friendly garment representation that seamlessly encodes the accurate geometry and sewing pattern of complex multi-layered garments as a structured set of per-panel geometry images. As a dual-2D-3D representation, Garmage achieves an unprecedented integration of 2D image-based algorithms with 3D modeling workflows, enabling high fidelity, non-watertight, multi-layered garment geometries with direct compatibility for industrial-grade simulations.Built upon this representation, we present GarmageNet, a novel generation framework capable of producing detailed multi-layered garments with body-conforming initial geometries and intricate sewing patterns, based on user prompts or existing in-the-wild sewing patterns. Furthermore, we introduce a robust stitching algorithm that recovers per-vertex stitches, ensuring seamless integration into flexible simulation pipelines for downstream editing of sewing patterns, material properties, and dynamic simulations. Finally, we release an industrial-standard, large-scale, high-fidelity garment dataset featuring detailed annotations, vertex-wise correspondences, and a robust pipeline for converting unstructured production sewing patterns into GarmageNet standard structural assets, paving the way for large-scale, industrial-grade garment generation systems.
Design2GarmentCode: Turning Design Concepts to Tangible Garments Through Program Synthesis
Dec 12, 2024



Sewing patterns, the essential blueprints for fabric cutting and tailoring, act as a crucial bridge between design concepts and producible garments. However, existing uni-modal sewing pattern generation models struggle to effectively encode complex design concepts with a multi-modal nature and correlate them with vectorized sewing patterns that possess precise geometric structures and intricate sewing relations. In this work, we propose a novel sewing pattern generation approach Design2GarmentCode based on Large Multimodal Models (LMMs), to generate parametric pattern-making programs from multi-modal design concepts. LMM offers an intuitive interface for interpreting diverse design inputs, while pattern-making programs could serve as well-structured and semantically meaningful representations of sewing patterns, and act as a robust bridge connecting the cross-domain pattern-making knowledge embedded in LMMs with vectorized sewing patterns. Experimental results demonstrate that our method can flexibly handle various complex design expressions such as images, textual descriptions, designer sketches, or their combinations, and convert them into size-precise sewing patterns with correct stitches. Compared to previous methods, our approach significantly enhances training efficiency, generation quality, and authoring flexibility. Our code and data will be publicly available.
Analytic Convolutional Layer: A Step to Analytic Neural Network
Jul 03, 2024



The prevailing approach to embedding prior knowledge within convolutional layers typically includes the design of steerable kernels or their modulation using designated kernel banks. In this study, we introduce the Analytic Convolutional Layer (ACL), an innovative model-driven convolutional layer, which is a mosaic of analytical convolution kernels (ACKs) and traditional convolution kernels. ACKs are characterized by mathematical functions governed by analytic kernel parameters (AKPs) learned in training process. Learnable AKPs permit the adaptive update of incorporated knowledge to align with the features representation of data. Our extensive experiments demonstrate that the ACLs not only have a remarkable capacity for feature representation with a reduced number of parameters but also attain increased reliability through the analytical formulation of ACKs. Furthermore, ACLs offer a means for neural network interpretation, thereby paving the way for the intrinsic interpretability of neural network. The source code will be published in company with the paper.
Applications of Tao General Difference in Discrete Domain
Jan 27, 2024Numerical difference computation is one of the cores and indispensable in the modern digital era. Tao general difference (TGD) is a novel theory and approach to difference computation for discrete sequences and arrays in multidimensional space. Built on the solid theoretical foundation of the general difference in a finite interval, the TGD operators demonstrate exceptional signal processing capabilities in real-world applications. A novel smoothness property of a sequence is defined on the first- and second TGD. This property is used to denoise one-dimensional signals, where the noise is the non-smooth points in the sequence. Meanwhile, the center of the gradient in a finite interval can be accurately location via TGD calculation. This solves a traditional challenge in computer vision, which is the precise localization of image edges with noise robustness. Furthermore, the power of TGD operators extends to spatio-temporal edge detection in three-dimensional arrays, enabling the identification of kinetic edges in video data. These diverse applications highlight the properties of TGD in discrete domain and the significant promise of TGD for the computation across signal processing, image analysis, and video analytic.
Neural Impostor: Editing Neural Radiance Fields with Explicit Shape Manipulation
Oct 09, 2023Neural Radiance Fields (NeRF) have significantly advanced the generation of highly realistic and expressive 3D scenes. However, the task of editing NeRF, particularly in terms of geometry modification, poses a significant challenge. This issue has obstructed NeRF's wider adoption across various applications. To tackle the problem of efficiently editing neural implicit fields, we introduce Neural Impostor, a hybrid representation incorporating an explicit tetrahedral mesh alongside a multigrid implicit field designated for each tetrahedron within the explicit mesh. Our framework bridges the explicit shape manipulation and the geometric editing of implicit fields by utilizing multigrid barycentric coordinate encoding, thus offering a pragmatic solution to deform, composite, and generate neural implicit fields while maintaining a complex volumetric appearance. Furthermore, we propose a comprehensive pipeline for editing neural implicit fields based on a set of explicit geometric editing operations. We show the robustness and adaptability of our system through diverse examples and experiments, including the editing of both synthetic objects and real captured data. Finally, we demonstrate the authoring process of a hybrid synthetic-captured object utilizing a variety of editing operations, underlining the transformative potential of Neural Impostor in the field of 3D content creation and manipulation.
The changing rule of human bone density with aging based on a novel definition and mensuration of bone density with computed tomography
Aug 05, 2023

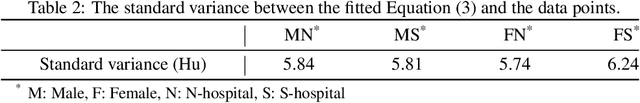
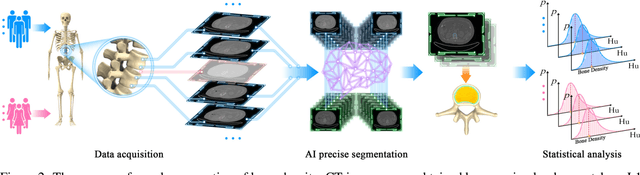
Osteoporosis and fragility fractures have emerged as major public health concerns in an aging population. However, measuring age-related changes in bone density using dual-energy X-ray absorptiometry has limited personalized risk assessment due to susceptibility to interference from various factors. In this study, we propose an innovative statistical model of bone pixel distribution in fine-segmented computed tomography (CT) images, along with a novel approach to measuring bone density based on CT values of bone pixels. Our findings indicate that bone density exhibits a linear decline with age during adulthood between the ages of 39 and 80, with the rate of decline being approximately 1.6 times faster in women than in men. This contradicts the widely accepted notion that bone density starts declining in women at menopause and in men at around 50 years of age. The linearity of age-related changes provides further insights into the dynamics of the aging human body. Consequently, our findings suggest that the definition of osteoporosis by the World Health Organization should be revised to the standard deviation of age-based bone density. Furthermore, these results open up new avenues for research in bone health care and clinical investigation of osteoporosis.
Tao General Differential and Difference: Theory and Application
May 14, 2023Modern numerical analysis is executed on discrete data, of which numerical difference computation is one of the cores and is indispensable. Nevertheless, difference algorithms have a critical weakness in their sensitivity to noise, which has long posed a challenge in various fields including signal processing. Difference is an extension or generalization of differential in the discrete domain. However, due to the finite interval in discrete calculation, there is a failure in meeting the most fundamental definition of differential, where dy and dx are both infinitesimal (Leibniz) or the limit of dx is 0 (Cauchy). In this regard, the generalization of differential to difference does not hold. To address this issue, we depart from the original derivative approach, construct a finite interval-based differential, and further generalize it to obtain the difference by convolution. Based on this theory, we present a variety of difference operators suitable for practical signal processing. Experimental results demonstrate that these difference operators possess exceptional signal processing capabilities, including high noise immunity.
Linguistic Rules-Based Corpus Generation for Native Chinese Grammatical Error Correction
Oct 19, 2022
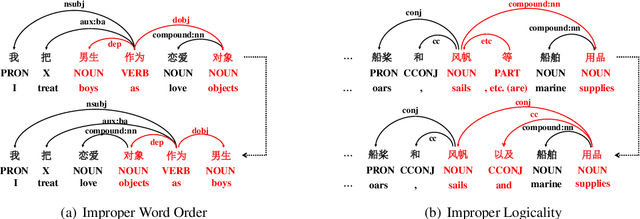
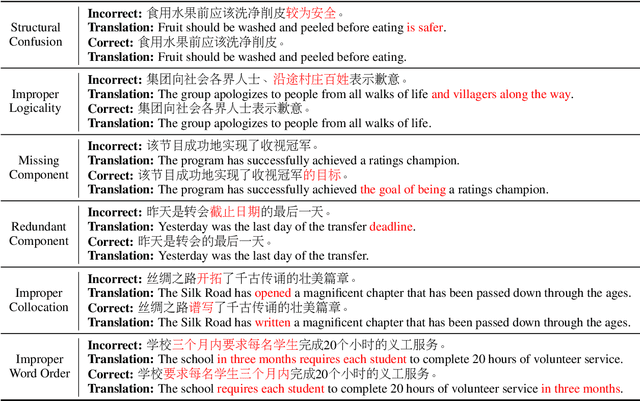
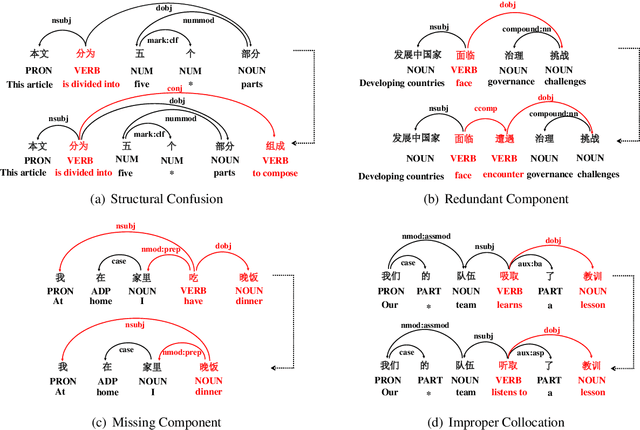
Chinese Grammatical Error Correction (CGEC) is both a challenging NLP task and a common application in human daily life. Recently, many data-driven approaches are proposed for the development of CGEC research. However, there are two major limitations in the CGEC field: First, the lack of high-quality annotated training corpora prevents the performance of existing CGEC models from being significantly improved. Second, the grammatical errors in widely used test sets are not made by native Chinese speakers, resulting in a significant gap between the CGEC models and the real application. In this paper, we propose a linguistic rules-based approach to construct large-scale CGEC training corpora with automatically generated grammatical errors. Additionally, we present a challenging CGEC benchmark derived entirely from errors made by native Chinese speakers in real-world scenarios. Extensive experiments and detailed analyses not only demonstrate that the training data constructed by our method effectively improves the performance of CGEC models, but also reflect that our benchmark is an excellent resource for further development of the CGEC field.
Learning from the Dictionary: Heterogeneous Knowledge Guided Fine-tuning for Chinese Spell Checking
Oct 19, 2022
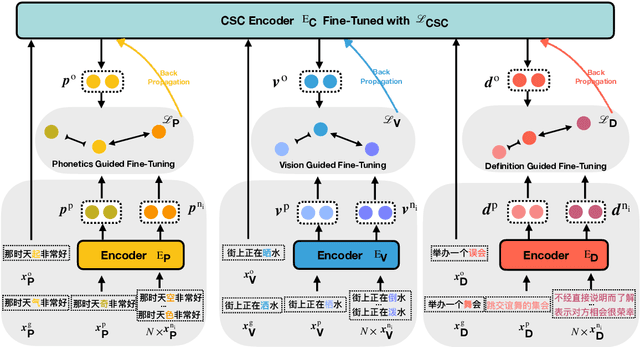
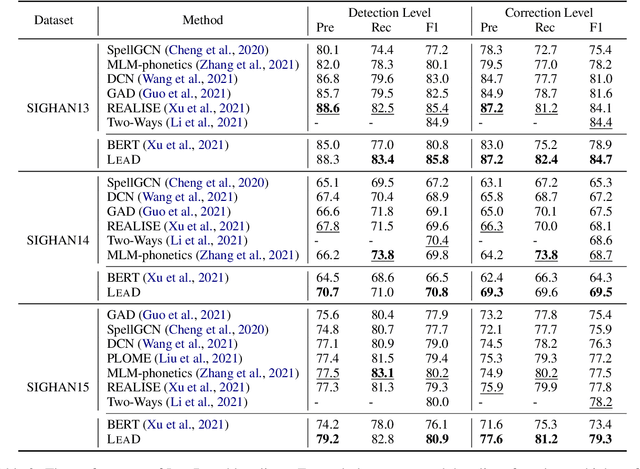

Chinese Spell Checking (CSC) aims to detect and correct Chinese spelling errors. Recent researches start from the pretrained knowledge of language models and take multimodal information into CSC models to improve the performance. However, they overlook the rich knowledge in the dictionary, the reference book where one can learn how one character should be pronounced, written, and used. In this paper, we propose the LEAD framework, which renders the CSC model to learn heterogeneous knowledge from the dictionary in terms of phonetics, vision, and meaning. LEAD first constructs positive and negative samples according to the knowledge of character phonetics, glyphs, and definitions in the dictionary. Then a unified contrastive learning-based training scheme is employed to refine the representations of the CSC models. Extensive experiments and detailed analyses on the SIGHAN benchmark datasets demonstrate the effectiveness of our proposed methods.
Automatic Context Pattern Generation for Entity Set Expansion
Jul 19, 2022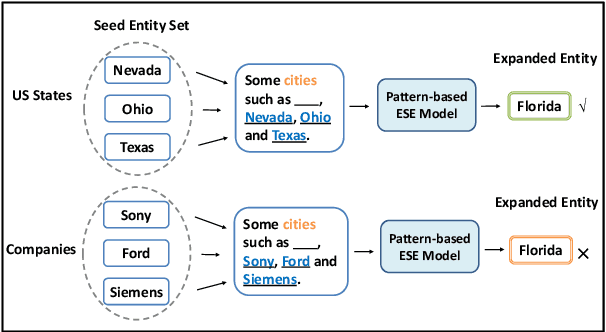

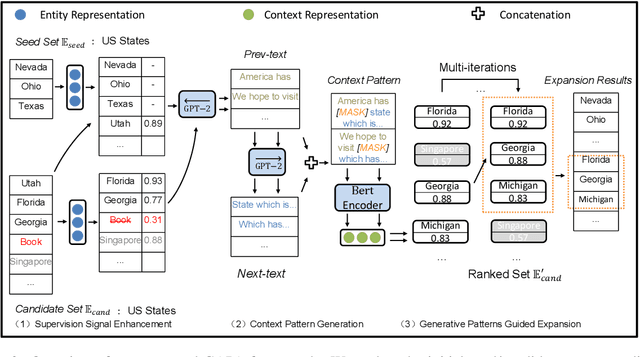
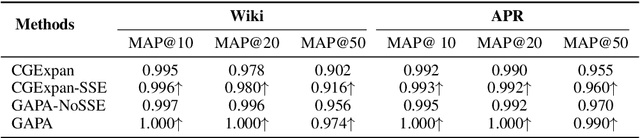
Entity Set Expansion (ESE) is a valuable task that aims to find entities of the target semantic class described by given seed entities. Various NLP and IR downstream applications have benefited from ESE due to its ability to discover knowledge. Although existing bootstrapping methods have achieved great progress, most of them still rely on manually pre-defined context patterns. A non-negligible shortcoming of the pre-defined context patterns is that they cannot be flexibly generalized to all kinds of semantic classes, and we call this phenomenon as "semantic sensitivity". To address this problem, we devise a context pattern generation module that utilizes autoregressive language models (e.g., GPT-2) to automatically generate high-quality context patterns for entities. In addition, we propose the GAPA, a novel ESE framework that leverages the aforementioned GenerAted PAtterns to expand target entities. Extensive experiments and detailed analyses on three widely used datasets demonstrate the effectiveness of our method. All the codes of our experiments will be available for reproducibility.