 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEME2.0: Towards More Interpretable Evaluation by Disentangling Edits for Grammatical Error Correction
Jul 01, 2024The paper focuses on improving the interpretability of Grammatical Error Correction (GEC) metrics, which receives little attention in previous studies. To bridge the gap, we propose CLEME2.0, a reference-based evaluation strategy that can describe four elementary dimensions of GEC systems, namely hit-correction, error-correction, under-correction, and over-correction. They collectively contribute to revealing the critical characteristics and locating drawbacks of GEC systems. Evaluating systems by Combining these dimensions leads to high human consistency over other reference-based and reference-less metrics. Extensive experiments on 2 human judgement datasets and 6 reference datasets demonstrate the effectiveness and robustness of our method. All the codes will be released after the peer review.
When LLMs Meet Cunning Questions: A Fallacy Understanding Benchmark for Large Language Models
Feb 16, 2024
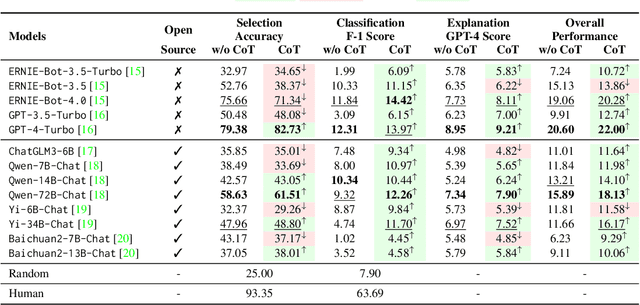

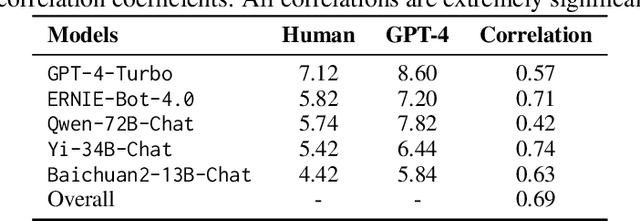
Recently, Large Language Models (LLMs) have made remarkable evolutions in language understanding and generation. Following this, various benchmarks for measuring all kinds of capabilities of LLMs have sprung up. In this paper, we challenge the reasoning and understanding abilities of LLMs by proposing a FaLlacy Understanding Benchmark (FLUB) containing cunning questions that are easy for humans to understand but difficult for models to grasp. Specifically, the cunning questions that FLUB focuses on mainly consist of the tricky, humorous, and misleading questions collected from the real internet environment. And we design three tasks with increasing difficulty in the FLUB benchmark to evaluate the fallacy understanding ability of LLMs. Based on FLUB, we investigate the performance of multiple representative and advanced LLMs, reflecting our FLUB is challenging and worthy of more future study. Interesting discoveries and valuable insights are achieved in our extensive experiments and detailed analyses. We hope that our benchmark can encourage the community to improve LLMs' ability to understand fallacies.
Towards Real-World Writing Assistance: A Chinese Character Checking Benchmark with Faked and Misspelled Characters
Nov 19, 2023



Writing assistance is an application closely related to human life and is also a fundamental Natural Language Processing (NLP) research field. Its aim is to improve the correctness and quality of input texts, with character checking being crucial in detecting and correcting wrong characters. From the perspective of the real world where handwriting occupies the vast majority, characters that humans get wrong include faked characters (i.e., untrue characters created due to writing errors) and misspelled characters (i.e., true characters used incorrectly due to spelling errors). However, existing datasets and related studies only focus on misspelled characters mainly caused by phonological or visual confusion, thereby ignoring faked characters which are more common and difficult. To break through this dilemma, we present Visual-C$^3$, a human-annotated Visual Chinese Character Checking dataset with faked and misspelled Chinese characters. To the best of our knowledge, Visual-C$^3$ is the first real-world visual and the largest human-crafted dataset for the Chinese character checking scenario. Additionally, we also propose and evaluate novel baseline methods on Visual-C$^3$. Extensive empirical results and analyses show that Visual-C$^3$ is high-quality yet challenging. The Visual-C$^3$ dataset and the baseline methods will be publicly available to facilitate further research in the community.
A Frustratingly Easy Plug-and-Play Detection-and-Reasoning Module for Chinese Spelling Check
Oct 13, 2023In recent years, Chinese Spelling Check (CSC) has been greatly improved by designing task-specific pre-training methods or introducing auxiliary tasks, which mostly solve this task in an end-to-end fashion. In this paper, we propose to decompose the CSC workflow into detection, reasoning, and searching subtasks so that the rich external knowledge about the Chinese language can be leveraged more directly and efficiently. Specifically, we design a plug-and-play detection-and-reasoning module that is compatible with existing SOTA non-autoregressive CSC models to further boost their performance. We find that the detection-and-reasoning module trained for one model can also benefit other models. We also study the primary interpretability provided by the task decomposition. Extensive experiments and detailed analyses demonstrate the effectiveness and competitiveness of the proposed module.
Enhancing Phrase Representation by Information Bottleneck Guided Text Diffusion Process for Keyphrase Extraction
Aug 17, 2023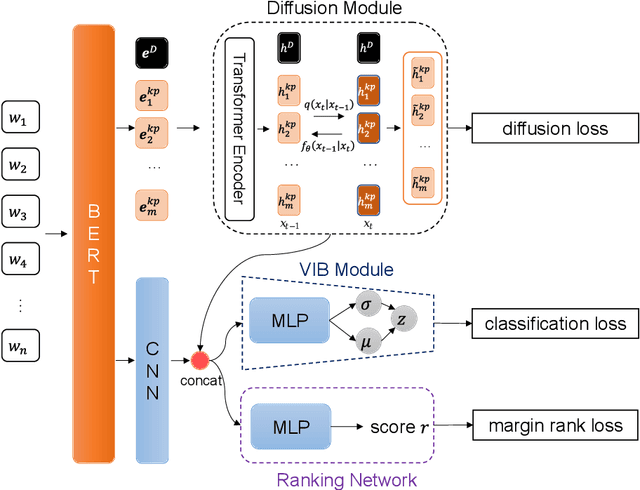



Keyphrase extraction (KPE) is an important task in Natural Language Processing for many scenarios, which aims to extract keyphrases that are present in a given document. Many existing supervised methods treat KPE as sequential labeling, span-level classification, or generative tasks. However, these methods lack the ability to utilize keyphrase information, which may result in biased results. In this study, we propose Diff-KPE, which leverages the supervised Variational Information Bottleneck (VIB) to guide the text diffusion process for generating enhanced keyphrase representations. Diff-KPE first generates the desired keyphrase embeddings conditioned on the entire document and then injects the generated keyphrase embeddings into each phrase representation. A ranking network and VIB are then optimized together with rank loss and classification loss, respectively. This design of Diff-KPE allows us to rank each candidate phrase by utilizing both the information of keyphrases and the document. Experiments show that Diff-KPE outperforms existing KPE methods on a large open domain keyphrase extraction benchmark, OpenKP, and a scientific domain dataset, KP20K.
Unifying Token and Span Level Supervisions for Few-Shot Sequence Labeling
Jul 20, 2023Few-shot sequence labeling aims to identify novel classes based on only a few labeled samples. Existing methods solve the data scarcity problem mainly by designing token-level or span-level labeling models based on metric learning. However, these methods are only trained at a single granularity (i.e., either token level or span level) and have some weaknesses of the corresponding granularity. In this paper, we first unify token and span level supervisions and propose a Consistent Dual Adaptive Prototypical (CDAP) network for few-shot sequence labeling. CDAP contains the token-level and span-level networks, jointly trained at different granularities. To align the outputs of two networks, we further propose a consistent loss to enable them to learn from each other. During the inference phase, we propose a consistent greedy inference algorithm that first adjusts the predicted probability and then greedily selects non-overlapping spans with maximum probability. Extensive experiments show that our model achieves new state-of-the-art results on three benchmark datasets.
On the Effectiveness of Large Language Models for Chinese Text Correction
Jul 18, 2023Recently, the development and progress of Large Language Models (LLMs) have amazed the entire Artificial Intelligence community. As an outstanding representative of LLMs and the foundation model that set off this wave of research on LLMs, ChatGPT has attracted more and more researchers to study its capabilities and performance on various downstream Natural Language Processing (NLP) tasks. While marveling at ChatGPT's incredible performance on kinds of tasks, we notice that ChatGPT also has excellent multilingual processing capabilities, such as Chinese. To explore the Chinese processing ability of ChatGPT, we focus on Chinese Text Correction, a fundamental and challenging Chinese NLP task. Specifically, we evaluate ChatGPT on the Chinese Grammatical Error Correction (CGEC) and Chinese Spelling Check (CSC) tasks, which are two main Chinese Text Correction scenarios. From extensive analyses and comparisons with previous state-of-the-art fine-tuned models, we empirically find that the ChatGPT currently has both amazing performance and unsatisfactory behavior for Chinese Text Correction. We believe our findings will promote the landing and application of LLMs in the Chinese NLP community.
CLEME: Debiasing Multi-reference Evaluation for Grammatical Error Correction
May 18, 2023It is intractable to evaluate the performance of Grammatical Error Correction (GEC) systems since GEC is a highly subjective task. Designing an evaluation metric that is as objective as possible is crucial to the development of GEC task. Previous mainstream evaluation metrics, i.e., reference-based metrics, introduce bias into the multi-reference evaluation because they extract edits without considering the presence of multiple references. To overcome the problem, we propose Chunk-LEvel Multi-reference Evaluation (CLEME) designed to evaluate GEC systems in multi-reference settings. First, CLEME builds chunk sequences with consistent boundaries for the source, the hypothesis and all the references, thus eliminating the bias caused by inconsistent edit boundaries. Then, based on the discovery that there exist boundaries between different grammatical errors, we automatically determine the grammatical error boundaries and compute F$_{0.5}$ scores in a novel way. Our proposed CLEME approach consistently and substantially outperforms existing reference-based GEC metrics on multiple reference sets in both corpus-level and sentence-level settings. Extensive experiments and detailed analyses demonstrate the correctness of our discovery and the effectiveness of our designed evaluation metric.
Instance Segmentation for Chinese Character Stroke Extraction, Datasets and Benchmarks
Oct 25, 2022



Stroke is the basic element of Chinese character and stroke extraction has been an important and long-standing endeavor. Existing stroke extraction methods are often handcrafted and highly depend on domain expertise due to the limited training data. Moreover, there are no standardized benchmarks to provide a fair comparison between different stroke extraction methods, which, we believe, is a major impediment to the development of Chinese character stroke understanding and related tasks. In this work, we present the first public available Chinese Character Stroke Extraction (CCSE) benchmark, with two new large-scale datasets: Kaiti CCSE (CCSE-Kai) and Handwritten CCSE (CCSE-HW). With the large-scale datasets, we hope to leverage the representation power of deep models such as CNNs to solve the stroke extraction task, which, however, remains an open question. To this end, we turn the stroke extraction problem into a stroke instance segmentation problem. Using the proposed datasets to train a stroke instance segmentation model, we surpass previous methods by a large margin. Moreover, the models trained with the proposed datasets benefit the downstream font generation and handwritten aesthetic assessment tasks. We hope these benchmark results can facilitate further research. The source code and datasets are publicly available at: https://github.com/lizhaoliu-Lec/CCSE.
Linguistic Rules-Based Corpus Generation for Native Chinese Grammatical Error Correction
Oct 19, 2022
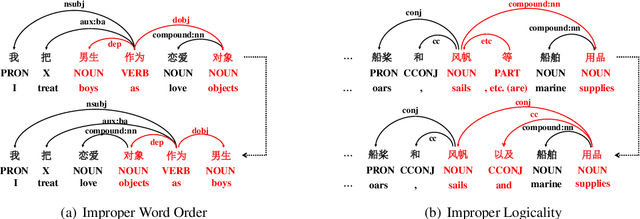
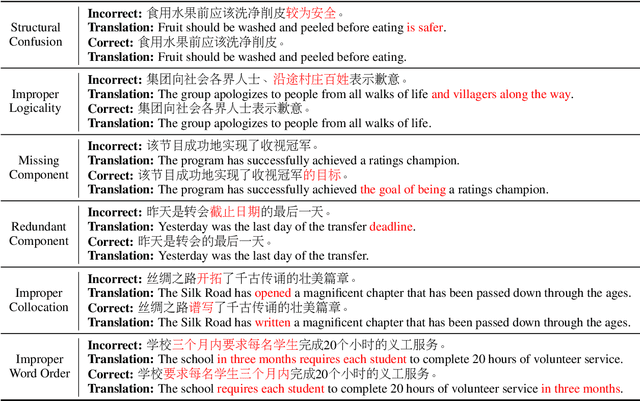
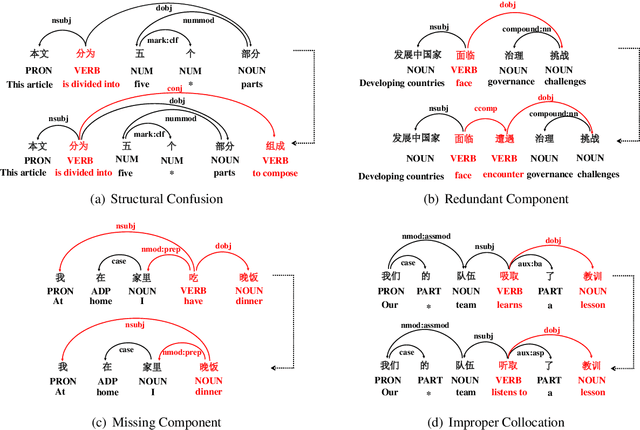
Chinese Grammatical Error Correction (CGEC) is both a challenging NLP task and a common application in human daily life. Recently, many data-driven approaches are proposed for the development of CGEC research. However, there are two major limitations in the CGEC field: First, the lack of high-quality annotated training corpora prevents the performance of existing CGEC models from being significantly improved. Second, the grammatical errors in widely used test sets are not made by native Chinese speakers, resulting in a significant gap between the CGEC models and the real application. In this paper, we propose a linguistic rules-based approach to construct large-scale CGEC training corpora with automatically generated grammatical errors. Additionally, we present a challenging CGEC benchmark derived entirely from errors made by native Chinese speakers in real-world scenarios. Extensive experiments and detailed analyses not only demonstrate that the training data constructed by our method effectively improves the performance of CGEC models, but also reflect that our benchmark is an excellent resource for further development of the CGEC field.