 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCOF: Self-iterative Text Generation for Copywriting Using Large Language Model
Feb 21, 2024
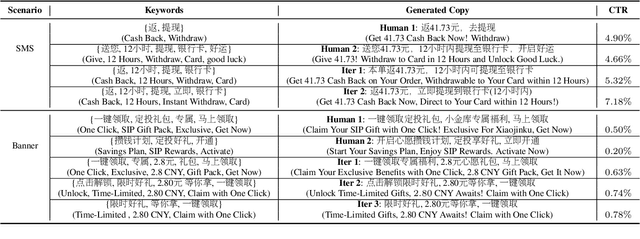
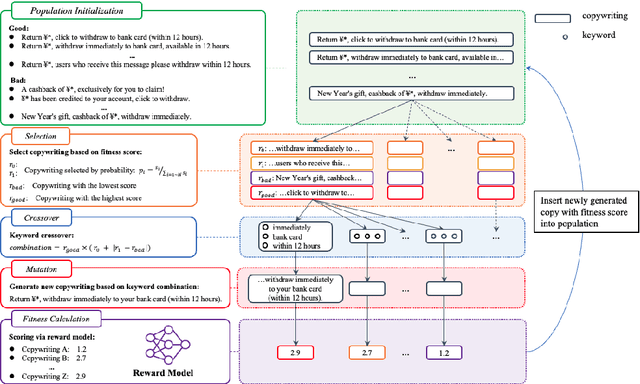

Large language models(LLM) such as ChatGPT have substantially simplified the generation of marketing copy, yet producing content satisfying domain specific requirements, such as effectively engaging customers, remains a significant challenge. In this work, we introduce the Genetic Copy Optimization Framework (GCOF) designed to enhance both efficiency and engagememnt of marketing copy creation. We conduct explicit feature engineering within the prompts of LLM. Additionally, we modify the crossover operator in Genetic Algorithm (GA), integrating it into the GCOF to enable automatic feature engineering. This integration facilitates a self-iterative refinement of the marketing copy. Compared to human curated copy, Online results indicate that copy produced by our framework achieves an average increase in click-through rate (CTR) of over $50\%$.
Unifying Token and Span Level Supervisions for Few-Shot Sequence Labeling
Jul 20, 2023Few-shot sequence labeling aims to identify novel classes based on only a few labeled samples. Existing methods solve the data scarcity problem mainly by designing token-level or span-level labeling models based on metric learning. However, these methods are only trained at a single granularity (i.e., either token level or span level) and have some weaknesses of the corresponding granularity. In this paper, we first unify token and span level supervisions and propose a Consistent Dual Adaptive Prototypical (CDAP) network for few-shot sequence labeling. CDAP contains the token-level and span-level networks, jointly trained at different granularities. To align the outputs of two networks, we further propose a consistent loss to enable them to learn from each other. During the inference phase, we propose a consistent greedy inference algorithm that first adjusts the predicted probability and then greedily selects non-overlapping spans with maximum probability. Extensive experiments show that our model achieves new state-of-the-art results on three benchmark datasets.
Finding Similar Exercises in Retrieval Manner
Mar 15, 2023


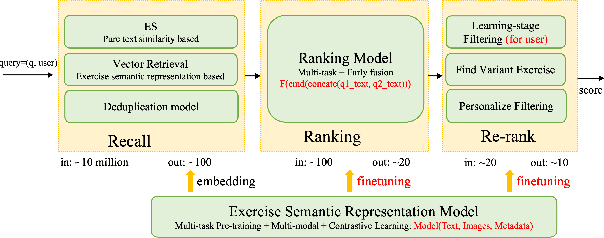
When students make a mistake in an exercise, they can consolidate it by ``similar exercises'' which have the same concepts, purposes and methods. Commonly, for a certain subject and study stage, the size of the exercise bank is in the range of millions to even tens of millions, how to find similar exercises for a given exercise becomes a crucial technical problem. Generally, we can assign a variety of explicit labels to the exercise, and then query through the labels, but the label annotation is time-consuming, laborious and costly, with limited precision and granularity, so it is not feasible. In practice, we define ``similar exercises'' as a retrieval process of finding a set of similar exercises based on recall, ranking and re-rank procedures, called the \textbf{FSE} problem (Finding similar exercises). Furthermore, comprehensive representation of the semantic information of exercises was obtained through representation learning. In addition to the reasonable architecture, we also explore what kind of tasks are more conducive to the learning of exercise semantic information from pre-training and supervised learning. It is difficult to annotate similar exercises and the annotation consistency among experts is low. Therefore this paper also provides solutions to solve the problem of low-quality annotated data. Compared with other methods, this paper has obvious advantages in both architecture rationality and algorithm precision, which now serves the daily teaching of hundreds of schools.
* 37th Conference on AAAI 2023 Artificial Intelligence for Education(AI4Edu)
TQ-Net: Mixed Contrastive Representation Learning For Heterogeneous Test Questions
Mar 09, 2023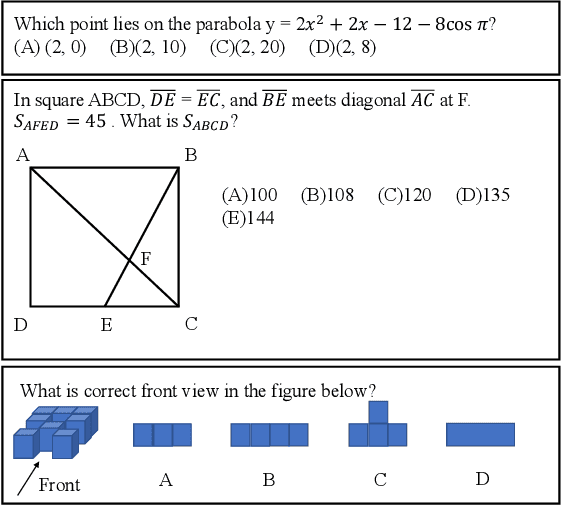

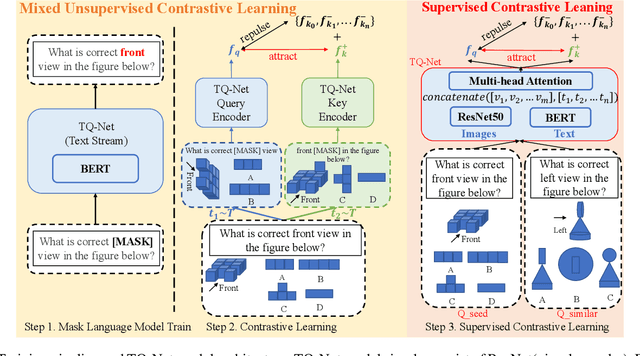
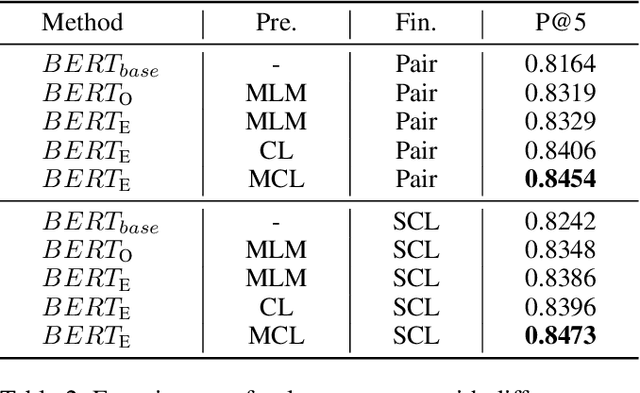
Recently, more and more people study online for the convenience of access to massive learning materials (e.g. test questions/notes), thus accurately understanding learning materials became a crucial issue, which is essential for many educational applications. Previous studies focus on using language models to represent the question data. However, test questions (TQ) are usually heterogeneous and multi-modal, e.g., some of them may only contain text, while others half contain images with information beyond their literal description. In this context, both supervised and unsupervised methods are difficult to learn a fused representation of questions. Meanwhile, this problem cannot be solved by conventional methods such as image caption, as the images may contain information complementary rather than duplicate to the text. In this paper, we first improve previous text-only representation with a two-stage unsupervised instance level contrastive based pre-training method (MCL: Mixture Unsupervised Contrastive Learning). Then, TQ-Net was proposed to fuse the content of images to the representation of heterogeneous data. Finally, supervised contrastive learning was conducted on relevance prediction-related downstream tasks, which helped the model to learn the representation of questions effectively. We conducted extensive experiments on question-based tasks on large-scale, real-world datasets, which demonstrated the effectiveness of TQ-Net and improve the precision of downstream applications (e.g. similar questions +2.02% and knowledge point prediction +7.20%). Our code will be available, and we will open-source a subset of our data to promote the development of relative studies.
DialogUSR: Complex Dialogue Utterance Splitting and Reformulation for Multiple Intent Detection
Oct 20, 2022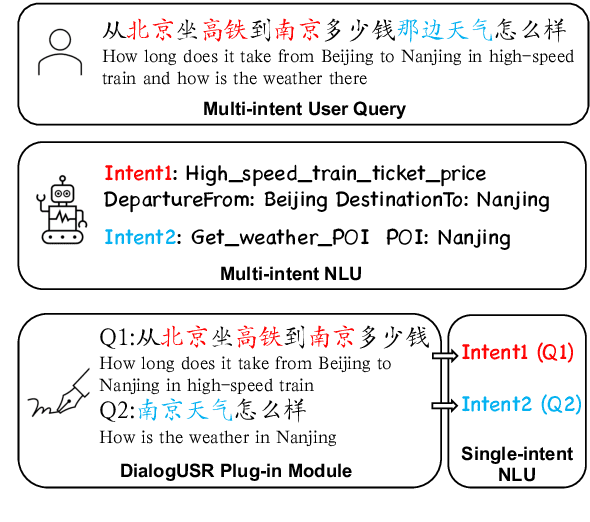
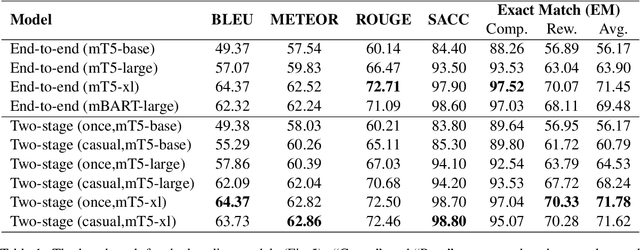

While interacting with chatbots, users may elicit multiple intents in a single dialogue utterance. Instead of training a dedicated multi-intent detection model, we propose DialogUSR, a dialogue utterance splitting and reformulation task that first splits multi-intent user query into several single-intent sub-queries and then recovers all the coreferred and omitted information in the sub-queries. DialogUSR can serve as a plug-in and domain-agnostic module that empowers the multi-intent detection for the deployed chatbots with minimal efforts. We collect a high-quality naturally occurring dataset that covers 23 domains with a multi-step crowd-souring procedure. To benchmark the proposed dataset, we propose multiple action-based generative models that involve end-to-end and two-stage training, and conduct in-depth analyses on the pros and cons of the proposed baselines.
Exploring Student Representation For Neural Cognitive Diagnosis
Nov 17, 2021


Cognitive diagnosis, the goal of which is to obtain the proficiency level of students on specific knowledge concepts, is an fundamental task in smart educational systems. Previous works usually represent each student as a trainable knowledge proficiency vector, which cannot capture the relations of concepts and the basic profile(e.g. memory or comprehension) of students. In this paper, we propose a method of student representation with the exploration of the hierarchical relations of knowledge concepts and student embedding. Specifically, since the proficiency on parent knowledge concepts reflects the correlation between knowledge concepts, we get the first knowledge proficiency with a parent-child concepts projection layer. In addition, a low-dimension dense vector is adopted as the embedding of each student, and obtain the second knowledge proficiency with a full connection layer. Then, we combine the two proficiency vector above to get the final representation of students. Experiments show the effectiveness of proposed representation method.
LANA: Towards Personalized Deep Knowledge Tracing Through Distinguishable Interactive Sequences
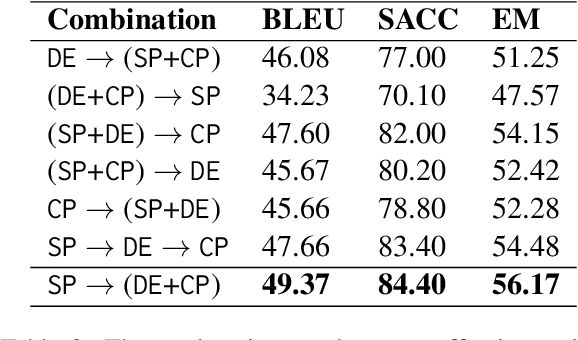
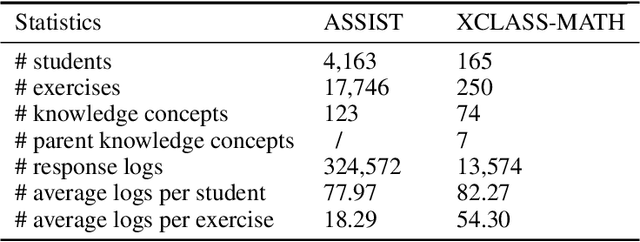
Apr 21, 2021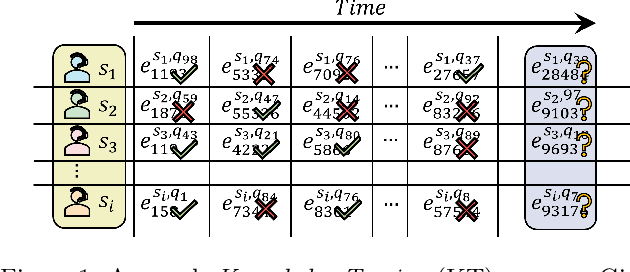

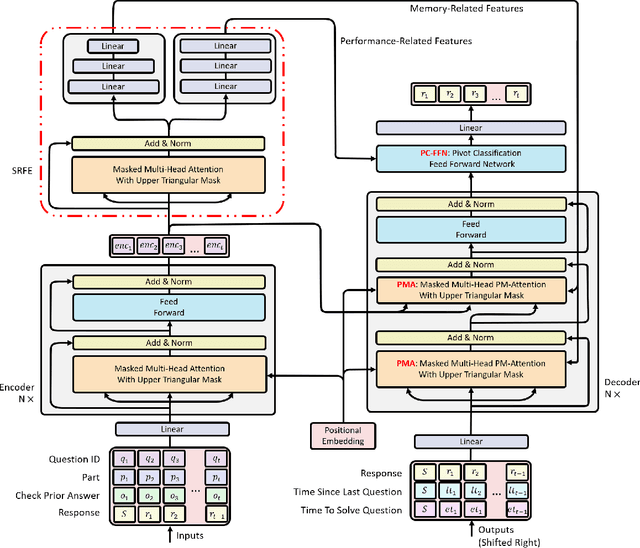
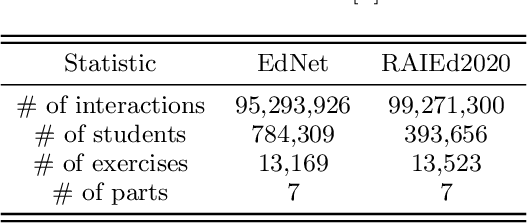
In educational applications, Knowledge Tracing (KT), the problem of accurately predicting students' responses to future questions by summarizing their knowledge states, has been widely studied for decades as it is considered a fundamental task towards adaptive online learning. Among all the proposed KT methods, Deep Knowledge Tracing (DKT) and its variants are by far the most effective ones due to the high flexibility of the neural network. However, DKT often ignores the inherent differences between students (e.g. memory skills, reasoning skills, ...), averaging the performances of all students, leading to the lack of personalization, and therefore was considered insufficient for adaptive learning. To alleviate this problem, in this paper, we proposed Leveled Attentive KNowledge TrAcing (LANA), which firstly uses a novel student-related features extractor (SRFE) to distill students' unique inherent properties from their respective interactive sequences. Secondly, the pivot module was utilized to dynamically reconstruct the decoder of the neural network on attention of the extracted features, successfully distinguishing the performance between students over time. Moreover, inspired by Item Response Theory (IRT), the interpretable Rasch model was used to cluster students by their ability levels, and thereby utilizing leveled learning to assign different encoders to different groups of students. With pivot module reconstructed the decoder for individual students and leveled learning specialized encoders for groups, personalized DKT was achieved. Extensive experiments conducted on two real-world large-scale datasets demonstrated that our proposed LANA improves the AUC score by at least 1.00% (i.e. EdNet 1.46% and RAIEd2020 1.00%), substantially surpassing the other State-Of-The-Art KT methods.