 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogPortrait: Fine-Grained Eye-Region Control in Portrait Animation via Hierarchical Agent Planning
May 27, 2026Portrait animation methods have achieved substantial visual quality and lip synchronization, but fine-grained manipulation of the eye region still faces a trade-off between input granularity and motion accuracy. Existing methods using emotion labels or coarse text prompts are insufficient for describing subtle ocular dynamics, whereas approaches based on Action Units or driving videos provide higher fidelity at the cost of a heavier input burden. These limitations are still restrictive for beyond-emotion states (e.g., thinking) and drowsiness. In light of the above, we propose CogPortrait, a two-stage framework that generates portrait animations from high-level labels. In the first stage, three chain-of-thought Multimodal Large Language Models (MLLMs) agents compile high-level labels into facial keypoints through temporal event planning, prototype retrieval, and composition from a real-behavior library, and semantic-physiological constraint enforcement. In the second stage, a DiT-based video generation backbone synthesizes the final animation conditioned on the keypoints, reference portrait, audio, and text prompt, enhanced by a dynamic classifier-free guidance strategy with eye-region-aware reweighting and KTO-based refinement for boundary cases. We further introduce the EMH benchmark covering diverse emotions and beyond-emotion categories with two AU-level metrics for evaluating fine-grained eye-region and head-motion control. Extensive experiments on HDTF and the EMH benchmark demonstrate that CogPortrait achieves more precise eye-region control than existing methods while maintaining supe- rior visual quality and identity consistency
One-Shot Pose-Driving Face Animation Platform
Jul 12, 2024
The objective of face animation is to generate dynamic and expressive talking head videos from a single reference face, utilizing driving conditions derived from either video or audio inputs. Current approaches often require fine-tuning for specific identities and frequently fail to produce expressive videos due to the limited effectiveness of Wav2Pose modules. To facilitate the generation of one-shot and more consecutive talking head videos, we refine an existing Image2Video model by integrating a Face Locator and Motion Frame mechanism. We subsequently optimize the model using extensive human face video datasets, significantly enhancing its ability to produce high-quality and expressive talking head videos. Additionally, we develop a demo platform using the Gradio framework, which streamlines the process, enabling users to quickly create customized talking head videos.
DialogUSR: Complex Dialogue Utterance Splitting and Reformulation for Multiple Intent Detection
Oct 20, 2022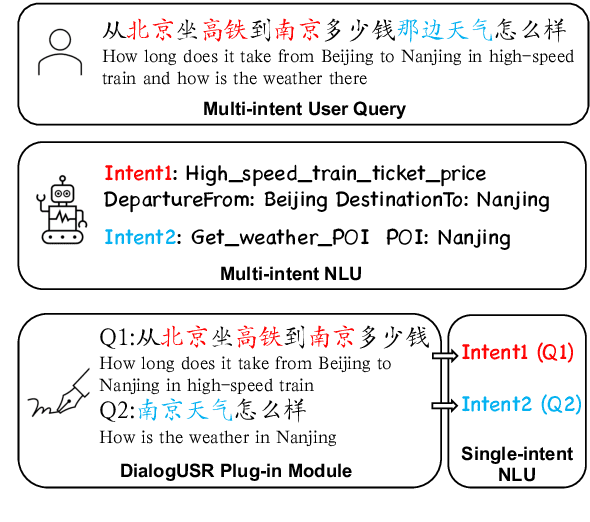
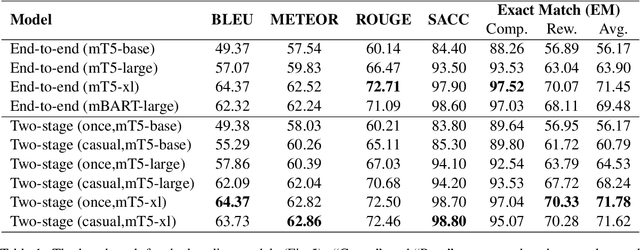

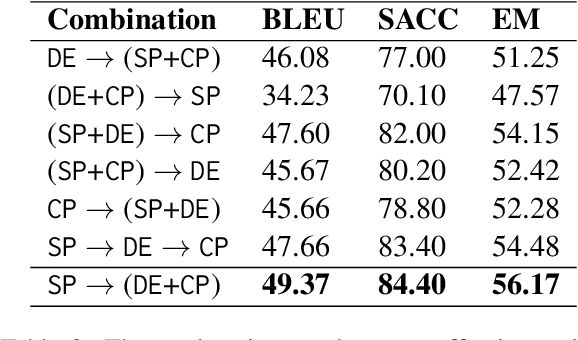
While interacting with chatbots, users may elicit multiple intents in a single dialogue utterance. Instead of training a dedicated multi-intent detection model, we propose DialogUSR, a dialogue utterance splitting and reformulation task that first splits multi-intent user query into several single-intent sub-queries and then recovers all the coreferred and omitted information in the sub-queries. DialogUSR can serve as a plug-in and domain-agnostic module that empowers the multi-intent detection for the deployed chatbots with minimal efforts. We collect a high-quality naturally occurring dataset that covers 23 domains with a multi-step crowd-souring procedure. To benchmark the proposed dataset, we propose multiple action-based generative models that involve end-to-end and two-stage training, and conduct in-depth analyses on the pros and cons of the proposed baselines.