 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogPortrait: Fine-Grained Eye-Region Control in Portrait Animation via Hierarchical Agent Planning
May 27, 2026Portrait animation methods have achieved substantial visual quality and lip synchronization, but fine-grained manipulation of the eye region still faces a trade-off between input granularity and motion accuracy. Existing methods using emotion labels or coarse text prompts are insufficient for describing subtle ocular dynamics, whereas approaches based on Action Units or driving videos provide higher fidelity at the cost of a heavier input burden. These limitations are still restrictive for beyond-emotion states (e.g., thinking) and drowsiness. In light of the above, we propose CogPortrait, a two-stage framework that generates portrait animations from high-level labels. In the first stage, three chain-of-thought Multimodal Large Language Models (MLLMs) agents compile high-level labels into facial keypoints through temporal event planning, prototype retrieval, and composition from a real-behavior library, and semantic-physiological constraint enforcement. In the second stage, a DiT-based video generation backbone synthesizes the final animation conditioned on the keypoints, reference portrait, audio, and text prompt, enhanced by a dynamic classifier-free guidance strategy with eye-region-aware reweighting and KTO-based refinement for boundary cases. We further introduce the EMH benchmark covering diverse emotions and beyond-emotion categories with two AU-level metrics for evaluating fine-grained eye-region and head-motion control. Extensive experiments on HDTF and the EMH benchmark demonstrate that CogPortrait achieves more precise eye-region control than existing methods while maintaining supe- rior visual quality and identity consistency
UAVReason: A Unified, Large-Scale Benchmark for Multimodal Aerial Scene Reasoning and Generation
Apr 07, 2026Vision-Language models (VLMs) have demonstrated remarkable capability in ground-view visual understanding but often fracture when deployed on high-altitude Unmanned Aerial Vehicles (UAVs). The failure largely stems from a pronounced domain shift, characterized by tiny and densely packed objects, repetitive textures, and ambiguous top-down orientations. These factors severely disrupt semantic grounding and hinder both spatial reasoning and controllable generation. To bridge this critical gap, we introduce UAVReason, the first unified large-scale multi-modal benchmark dedicated to nadir-view UAV scenarios, derived from a high-fidelity UAV simulation platform. In contrast to existing UAV benchmarks, which are largely siloed and focus on single tasks like object detection or segmentation, UAVReason uniquely consolidates over 273K Visual Question Answering (VQA) pairs, including 23.6K single frames with detailed captions, 68.2K 2-frame temporal sequences, and 188.8K cross-modal generation samples. The benchmark probes 22 diverse reasoning types across spatial and temporal axes while simultaneously evaluating high-fidelity generation across RGB, depth, and segmentation modalities. We further establish a strong, unified baseline model via multi-task learning. Extensive experiments validate the efficacy of our unified approach across diverse metrics, such as EM/F1 for VQA, mIoU for segmentation, and CLIP Score for generation. These results indicate limitations of general-domain vision-language models and show that unified multi-task learning substantially improves UAV-native performance. All data, code, and evaluation tools will be publicly released to advance UAV multimodal research.
ScrollScape: Unlocking 32K Image Generation With Video Diffusion Priors
Mar 25, 2026While diffusion models excel at generating images with conventional dimensions, pushing them to synthesize ultra-high-resolution imagery at extreme aspect ratios (EAR) often triggers catastrophic structural failures, such as object repetition and spatial fragmentation.This limitation fundamentally stems from a lack of robust spatial priors, as static text-to-image models are primarily trained on image distributions with conventional dimensions.To overcome this bottleneck, we present ScrollScape, a novel framework that reformulates EAR image synthesis into a continuous video generation process through two core innovations.By mapping the spatial expansion of a massive canvas to the temporal evolution of video frames, ScrollScape leverages the inherent temporal consistency of video models as a powerful global constraint to ensure long-range structural integrity.Specifically, Scanning Positional Encoding (ScanPE) distributes global coordinates across frames to act as a flexible moving camera, while Scrolling Super-Resolution (ScrollSR) leverages video super-resolution priors to circumvent memory bottlenecks, efficiently scaling outputs to an unprecedented 32K resolution. Fine-tuned on a curated 3K multi-ratio image dataset, ScrollScape effectively aligns pre-trained video priors with the EAR generation task. Extensive evaluations demonstrate that it significantly outperforms existing image-diffusion baselines by eliminating severe localized artifacts. Consequently, our method overcomes inherent structural bottlenecks to ensure exceptional global coherence and visual fidelity across diverse domains at extreme scales.
MoRe: Motion-aware Feed-forward 4D Reconstruction Transformer
Mar 05, 2026Reconstructing dynamic 4D scenes remains challenging due to the presence of moving objects that corrupt camera pose estimation. Existing optimization methods alleviate this issue with additional supervision, but they are mostly computationally expensive and impractical in real-time applications. To address these limitations, we propose MoRe, a feedforward 4D reconstruction network that efficiently recovers dynamic 3D scenes from monocular videos. Built upon a strong static reconstruction backbone, MoRe employs an attention-forcing strategy to disentangle dynamic motion from static structure. To further enhance robustness, we fine-tune the model on large-scale, diverse datasets encompassing both dynamic and static scenes. Moreover, our grouped causal attention captures temporal dependencies and adapts to varying token lengths across frames, ensuring temporally coherent geometry reconstruction. Extensive experiments on multiple benchmarks demonstrate that MoRe achieves high-quality dynamic reconstructions with exceptional efficiency.
Chain of World: World Model Thinking in Latent Motion
Mar 03, 2026Vision-Language-Action (VLA) models are a promising path toward embodied intelligence, yet they often overlook the predictive and temporal-causal structure underlying visual dynamics. World-model VLAs address this by predicting future frames, but waste capacity reconstructing redundant backgrounds. Latent-action VLAs encode frame-to-frame transitions compactly, but lack temporally continuous dynamic modeling and world knowledge. To overcome these limitations, we introduce CoWVLA (Chain-of-World VLA), a new "Chain of World" paradigm that unifies world-model temporal reasoning with a disentangled latent motion representation. First, a pretrained video VAE serves as a latent motion extractor, explicitly factorizing video segments into structure and motion latents. Then, during pre-training, the VLA learns from an instruction and an initial frame to infer a continuous latent motion chain and predict the segment's terminal frame. Finally, during co-fine-tuning, this latent dynamic is aligned with discrete action prediction by jointly modeling sparse keyframes and action sequences in a unified autoregressive decoder. This design preserves the world-model benefits of temporal reasoning and world knowledge while retaining the compactness and interpretability of latent actions, enabling efficient visuomotor learning. Extensive experiments on robotic simulation benchmarks show that CoWVLA outperforms existing world-model and latent-action approaches and achieves moderate computational efficiency, highlighting its potential as a more effective VLA pretraining paradigm. The project website can be found at https://fx-hit.github.io/cowvla-io.
GeoDiff4D: Geometry-Aware Diffusion for 4D Head Avatar Reconstruction
Feb 27, 2026Reconstructing photorealistic and animatable 4D head avatars from a single portrait image remains a fundamental challenge in computer vision. While diffusion models have enabled remarkable progress in image and video generation for avatar reconstruction, existing methods primarily rely on 2D priors and struggle to achieve consistent 3D geometry. We propose a novel framework that leverages geometry-aware diffusion to learn strong geometry priors for high-fidelity head avatar reconstruction. Our approach jointly synthesizes portrait images and corresponding surface normals, while a pose-free expression encoder captures implicit expression representations. Both synthesized images and expression latents are incorporated into 3D Gaussian-based avatars, enabling photorealistic rendering with accurate geometry. Extensive experiments demonstrate that our method substantially outperforms state-of-the-art approaches in visual quality, expression fidelity, and cross-identity generalization, while supporting real-time rendering.
MetricAnything: Scaling Metric Depth Pretraining with Noisy Heterogeneous Sources
Jan 29, 2026Scaling has powered recent advances in vision foundation models, yet extending this paradigm to metric depth estimation remains challenging due to heterogeneous sensor noise, camera-dependent biases, and metric ambiguity in noisy cross-source 3D data. We introduce Metric Anything, a simple and scalable pretraining framework that learns metric depth from noisy, diverse 3D sources without manually engineered prompts, camera-specific modeling, or task-specific architectures. Central to our approach is the Sparse Metric Prompt, created by randomly masking depth maps, which serves as a universal interface that decouples spatial reasoning from sensor and camera biases. Using about 20M image-depth pairs spanning reconstructed, captured, and rendered 3D data across 10000 camera models, we demonstrate-for the first time-a clear scaling trend in the metric depth track. The pretrained model excels at prompt-driven tasks such as depth completion, super-resolution and Radar-camera fusion, while its distilled prompt-free student achieves state-of-the-art results on monocular depth estimation, camera intrinsics recovery, single/multi-view metric 3D reconstruction, and VLA planning. We also show that using pretrained ViT of Metric Anything as a visual encoder significantly boosts Multimodal Large Language Model capabilities in spatial intelligence. These results show that metric depth estimation can benefit from the same scaling laws that drive modern foundation models, establishing a new path toward scalable and efficient real-world metric perception. We open-source MetricAnything at http://metric-anything.github.io/metric-anything-io/ to support community research.
Visual Prompt-Agnostic Evolution
Jan 28, 2026Visual Prompt Tuning (VPT) adapts a frozen Vision Transformer (ViT) to downstream tasks by inserting a small number of learnable prompt tokens into the token sequence at each layer. However, we observe that existing VPT variants often suffer from unstable training dynamics, characterized by gradient oscillations. A layer-wise analysis reveals that shallow-layer prompts tend to stagnate early, while deeper-layer prompts exhibit high-variance oscillations, leading to cross-layer mismatch. These issues slow convergence and degrade final performance. To address these challenges, we propose Prompt-Agnostic Evolution ($\mathtt{PAE}$), which strengthens vision prompt tuning by explicitly modeling prompt dynamics. From a frequency-domain perspective, we initialize prompts in a task-aware direction by uncovering and propagating frequency shortcut patterns that the backbone inherently exploits for recognition. To ensure coherent evolution across layers, we employ a shared Koopman operator that imposes a global linear transformation instead of uncoordinated, layer-specific updates. Finally, inspired by Lyapunov stability theory, we introduce a regularizer that constrains error amplification during evolution. Extensive experiments show that $\mathtt{PAE}$ accelerates convergence with an average $1.41\times$ speedup and improves accuracy by 1--3% on 25 datasets across multiple downstream tasks. Beyond performance, $\mathtt{PAE}$ is prompt-agnostic and lightweight, and it integrates seamlessly with diverse VPT variants without backbone modification or inference-time changes.
EverybodyDance: Bipartite Graph-Based Identity Correspondence for Multi-Character Animation
Dec 18, 2025
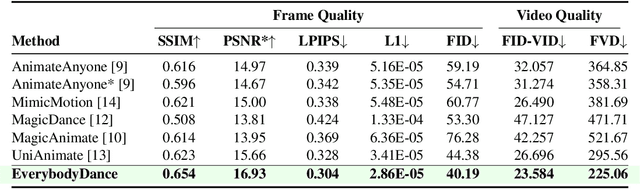

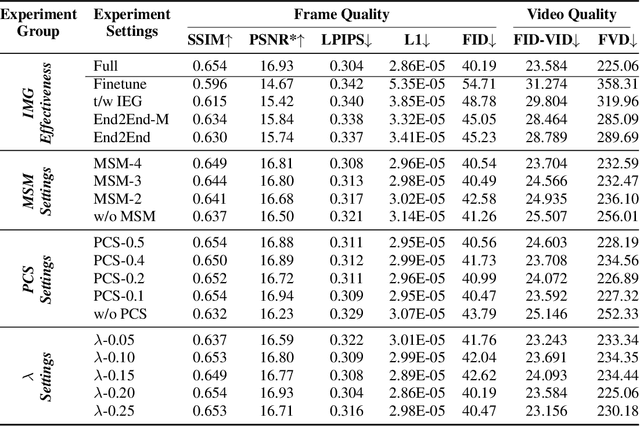
Consistent pose-driven character animation has achieved remarkable progress in single-character scenarios. However, extending these advances to multi-character settings is non-trivial, especially when position swap is involved. Beyond mere scaling, the core challenge lies in enforcing correct Identity Correspondence (IC) between characters in reference and generated frames. To address this, we introduce EverybodyDance, a systematic solution targeting IC correctness in multi-character animation. EverybodyDance is built around the Identity Matching Graph (IMG), which models characters in the generated and reference frames as two node sets in a weighted complete bipartite graph. Edge weights, computed via our proposed Mask-Query Attention (MQA), quantify the affinity between each pair of characters. Our key insight is to formalize IC correctness as a graph structural metric and to optimize it during training. We also propose a series of targeted strategies tailored for multi-character animation, including identity-embedded guidance, a multi-scale matching strategy, and pre-classified sampling, which work synergistically. Finally, to evaluate IC performance, we curate the Identity Correspondence Evaluation benchmark, dedicated to multi-character IC correctness. Extensive experiments demonstrate that EverybodyDance substantially outperforms state-of-the-art baselines in both IC and visual fidelity.
MoCo: Motion-Consistent Human Video Generation via Structure-Appearance Decoupling
Aug 24, 2025Generating human videos with consistent motion from text prompts remains a significant challenge, particularly for whole-body or long-range motion. Existing video generation models prioritize appearance fidelity, resulting in unrealistic or physically implausible human movements with poor structural coherence. Additionally, most existing human video datasets primarily focus on facial or upper-body motions, or consist of vertically oriented dance videos, limiting the scope of corresponding generation methods to simple movements. To overcome these challenges, we propose MoCo, which decouples the process of human video generation into two components: structure generation and appearance generation. Specifically, our method first employs an efficient 3D structure generator to produce a human motion sequence from a text prompt. The remaining video appearance is then synthesized under the guidance of the generated structural sequence. To improve fine-grained control over sparse human structures, we introduce Human-Aware Dynamic Control modules and integrate dense tracking constraints during training. Furthermore, recognizing the limitations of existing datasets, we construct a large-scale whole-body human video dataset featuring complex and diverse motions. Extensive experiments demonstrate that MoCo outperforms existing approaches in generating realistic and structurally coherent human videos.