 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNexus: Taming Throughput-Latency Tradeoff in LLM Serving via Efficient GPU Sharing
Jul 09, 2025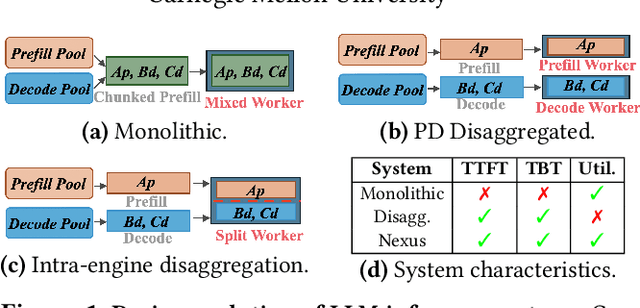
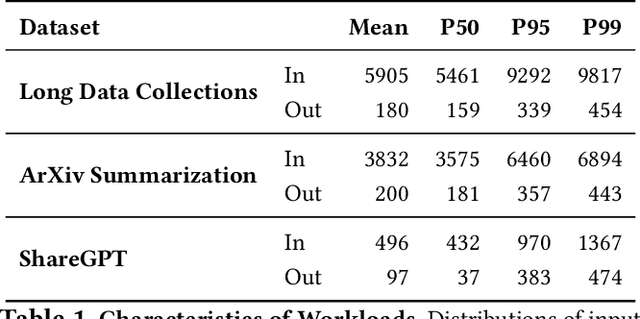
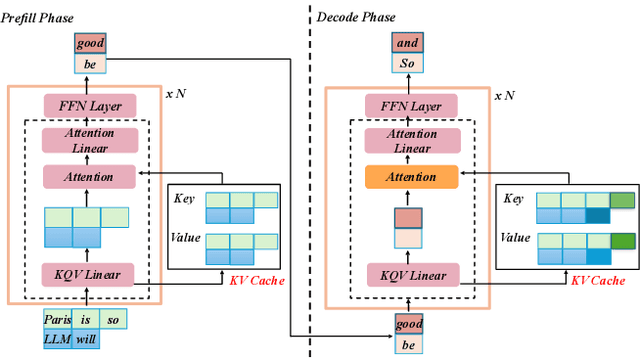
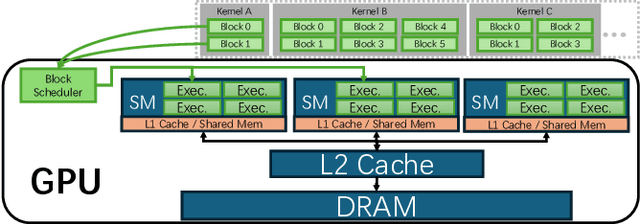
Current prefill-decode (PD) disaggregation is typically deployed at the level of entire serving engines, assigning separate GPUs to handle prefill and decode phases. While effective at reducing latency, this approach demands more hardware. To improve GPU utilization, Chunked Prefill mixes prefill and decode requests within the same batch, but introduces phase interference between prefill and decode. While existing PD disaggregation solutions separate the phases across GPUs, we ask: can the same decoupling be achieved within a single serving engine? The key challenge lies in managing the conflicting resource requirements of prefill and decode when they share the same hardware. In this paper, we first show that chunked prefill requests cause interference with decode requests due to their distinct requirements for GPU resources. Second, we find that GPU resources exhibit diminishing returns. Beyond a saturation point, increasing GPU allocation yields negligible latency improvements. This insight enables us to split a single GPU's resources and dynamically allocate them to prefill and decode on the fly, effectively disaggregating the two phases within the same GPU. Across a range of models and workloads, our system Nexus achieves up to 2.2x higher throughput, 20x lower TTFT, and 2.5x lower TBT than vLLM. It also outperforms SGLang with up to 2x higher throughput, 2x lower TTFT, and 1.7x lower TBT, and achieves 1.4x higher throughput than vLLM-disaggregation using only half the number of GPUs.
Kongzi: A Historical Large Language Model with Fact Enhancement
Apr 13, 2025The capabilities of the latest large language models (LLMs) have been extended from pure natural language understanding to complex reasoning tasks. However, current reasoning models often exhibit factual inaccuracies in longer reasoning chains, which poses challenges for historical reasoning and limits the potential of LLMs in complex, knowledge-intensive tasks. Historical studies require not only the accurate presentation of factual information but also the ability to establish cross-temporal correlations and derive coherent conclusions from fragmentary and often ambiguous sources. To address these challenges, we propose Kongzi, a large language model specifically designed for historical analysis. Through the integration of curated, high-quality historical data and a novel fact-reinforcement learning strategy, Kongzi demonstrates strong factual alignment and sophisticated reasoning depth. Extensive experiments on tasks such as historical question answering and narrative generation demonstrate that Kongzi outperforms existing models in both factual accuracy and reasoning depth. By effectively addressing the unique challenges inherent in historical texts, Kongzi sets a new standard for the development of accurate and reliable LLMs in professional domains.
Cluster-Driven Expert Pruning for Mixture-of-Experts Large Language Models
Apr 10, 2025Mixture-of-Experts (MoE) architectures have emerged as a promising paradigm for scaling large language models (LLMs) with sparse activation of task-specific experts. Despite their computational efficiency during inference, the massive overall parameter footprint of MoE models (e.g., GPT-4) introduces critical challenges for practical deployment. Current pruning approaches often fail to address two inherent characteristics of MoE systems: 1).intra-layer expert homogeneity where experts within the same MoE layer exhibit functional redundancy, and 2). inter-layer similarity patterns where deeper layers tend to contain progressively more homogeneous experts. To tackle these issues, we propose Cluster-driven Expert Pruning (C-Prune), a novel two-stage framework for adaptive task-specific compression of MoE LLMs. C-Prune operates through layer-wise expert clustering, which groups functionally similar experts within each MoE layer using parameter similarity metrics, followed by global cluster pruning, which eliminates redundant clusters across all layers through a unified importance scoring mechanism that accounts for cross-layer homogeneity. We validate C-Prune through extensive experiments on multiple MoE models and benchmarks. The results demonstrate that C-Prune effectively reduces model size while outperforming existing MoE pruning methods.
DependEval: Benchmarking LLMs for Repository Dependency Understanding
Mar 09, 2025While large language models (LLMs) have shown considerable promise in code generation, real-world software development demands advanced repository-level reasoning. This includes understanding dependencies, project structures, and managing multi-file changes. However, the ability of LLMs to effectively comprehend and handle complex code repositories has yet to be fully explored. To address challenges, we introduce a hierarchical benchmark designed to evaluate repository dependency understanding (DependEval). Benchmark is based on 15,576 repositories collected from real-world websites. It evaluates models on three core tasks: Dependency Recognition, Repository Construction, and Multi-file Editing, across 8 programming languages from actual code repositories. Our evaluation of over 25 LLMs reveals substantial performance gaps and provides valuable insights into repository-level code understanding.