 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrionBench: A Benchmark for Chart and Human-Recognizable Object Detection in Infographics
May 23, 2025



Given the central role of charts in scientific, business, and communication contexts, enhancing the chart understanding capabilities of vision-language models (VLMs) has become increasingly critical. A key limitation of existing VLMs lies in their inaccurate visual grounding of infographic elements, including charts and human-recognizable objects (HROs) such as icons and images. However, chart understanding often requires identifying relevant elements and reasoning over them. To address this limitation, we introduce OrionBench, a benchmark designed to support the development of accurate object detection models for charts and HROs in infographics. It contains 26,250 real and 78,750 synthetic infographics, with over 6.9 million bounding box annotations. These annotations are created by combining the model-in-the-loop and programmatic methods. We demonstrate the usefulness of OrionBench through three applications: 1) constructing a Thinking-with-Boxes scheme to boost the chart understanding performance of VLMs, 2) comparing existing object detection models, and 3) applying the developed detection model to document layout and UI element detection.
Cluster-Driven Expert Pruning for Mixture-of-Experts Large Language Models
Apr 10, 2025Mixture-of-Experts (MoE) architectures have emerged as a promising paradigm for scaling large language models (LLMs) with sparse activation of task-specific experts. Despite their computational efficiency during inference, the massive overall parameter footprint of MoE models (e.g., GPT-4) introduces critical challenges for practical deployment. Current pruning approaches often fail to address two inherent characteristics of MoE systems: 1).intra-layer expert homogeneity where experts within the same MoE layer exhibit functional redundancy, and 2). inter-layer similarity patterns where deeper layers tend to contain progressively more homogeneous experts. To tackle these issues, we propose Cluster-driven Expert Pruning (C-Prune), a novel two-stage framework for adaptive task-specific compression of MoE LLMs. C-Prune operates through layer-wise expert clustering, which groups functionally similar experts within each MoE layer using parameter similarity metrics, followed by global cluster pruning, which eliminates redundant clusters across all layers through a unified importance scoring mechanism that accounts for cross-layer homogeneity. We validate C-Prune through extensive experiments on multiple MoE models and benchmarks. The results demonstrate that C-Prune effectively reduces model size while outperforming existing MoE pruning methods.
Brain-inspired continual pre-trained learner via silent synaptic consolidation
Oct 08, 2024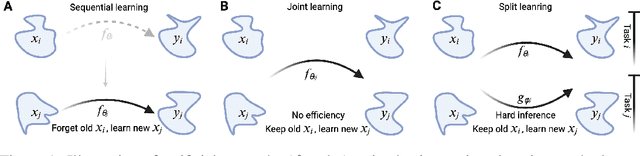
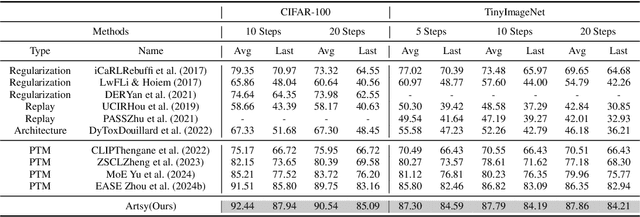
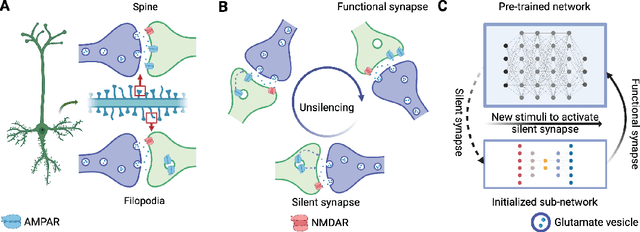
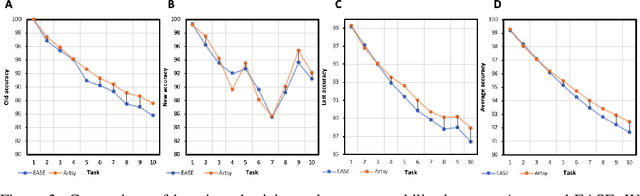
Pre-trained models have demonstrated impressive generalization capabilities, yet they remain vulnerable to catastrophic forgetting when incrementally trained on new tasks. Existing architecture-based strategies encounter two primary challenges: 1) Integrating a pre-trained network with a trainable sub-network complicates the delicate balance between learning plasticity and memory stability across evolving tasks during learning. 2) The absence of robust interconnections between pre-trained networks and various sub-networks limits the effective retrieval of pertinent information during inference. In this study, we introduce the Artsy, inspired by the activation mechanisms of silent synapses via spike-timing-dependent plasticity observed in mature brains, to enhance the continual learning capabilities of pre-trained models. The Artsy integrates two key components: During training, the Artsy mimics mature brain dynamics by maintaining memory stability for previously learned knowledge within the pre-trained network while simultaneously promoting learning plasticity in task-specific sub-networks. During inference, artificial silent and functional synapses are utilized to establish precise connections between the pre-synaptic neurons in the pre-trained network and the post-synaptic neurons in the sub-networks, facilitated through synaptic consolidation, thereby enabling effective extraction of relevant information from test samples. Comprehensive experimental evaluations reveal that our model significantly outperforms conventional methods on class-incremental learning tasks, while also providing enhanced biological interpretability for architecture-based approaches. Moreover, we propose that the Artsy offers a promising avenue for simulating biological synaptic mechanisms, potentially advancing our understanding of neural plasticity in both artificial and biological systems.