 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniShotCut: Holistic Relational Shot Boundary Detection with Shot-Query Transformer
Apr 27, 2026Shot Boundary Detection (SBD) aims to automatically identify shot changes and divide a video into coherent shots. While SBD was widely studied in the literature, existing state-of-the-art methods often produce non-interpretable boundaries on transitions, miss subtle yet harmful discontinuities, and rely on noisy, low-diversity annotations and outdated benchmarks. To alleviate these limitations, we propose OmniShotCut to formulate SBD as structured relational prediction, jointly estimating shot ranges with intra-shot relations and inter-shot relations, by a shot query-based dense video Transformer. To avoid imprecise manual labeling, we adopt a fully synthetic transition synthesis pipeline that automatically reproduces major transition families with precise boundaries and parameterized variants. We also introduce OmniShotCutBench, a modern wide-domain benchmark enabling holistic and diagnostic evaluation.
X-Cache: Cross-Chunk Block Caching for Few-Step Autoregressive World Models Inference
Apr 22, 2026Real-time world simulation is becoming a key infrastructure for scalable evaluation and online reinforcement learning of autonomous driving systems. Recent driving world models built on autoregressive video diffusion achieve high-fidelity, controllable multi-camera generation, but their inference cost remains a bottleneck for interactive deployment. However, existing diffusion caching methods are designed for offline video generation with multiple denoising steps, and do not transfer to this scenario. Few-step distilled models have no inter-step redundancy left for these methods to reuse, and sequence-level parallelization techniques require future conditioning that closed-loop interactive generation does not provide. We present X-Cache, a training-free acceleration method that caches along a different axis: across consecutive generation chunks rather than across denoising steps. X-Cache maintains per-block residual caches that persist across chunks, and applies a dual-metric gating mechanism over a structure- and action-aware block-input fingerprint to independently decide whether each block should recompute or reuse its cached residual. To prevent approximation errors from permanently contaminating the autoregressive KV cache, X-Cache identifies KV update chunks (the forward passes that write clean keys and values into the persistent cache) and unconditionally forces full computation on these chunks, cutting off error propagation. We implement X-Cache on X-world, a production multi-camera action-conditioned driving world model built on multi-block causal DiT with few-step denoising and rolling KV cache. X-Cache achieves 71% block skip rate with 2.6x wall-clock speedup while maintaining minimum degradation.
PilotBench: A Benchmark for General Aviation Agents with Safety Constraints
Apr 10, 2026As Large Language Models (LLMs) advance toward embodied AI agents operating in physical environments, a fundamental question emerges: can models trained on text corpora reliably reason about complex physics while adhering to safety constraints? We address this through PilotBench, a benchmark evaluating LLMs on safety-critical flight trajectory and attitude prediction. Built from 708 real-world general aviation trajectories spanning nine operationally distinct flight phases with synchronized 34-channel telemetry, PilotBench systematically probes the intersection of semantic understanding and physics-governed prediction through comparative analysis of LLMs and traditional forecasters. We introduce Pilot-Score, a composite metric balancing 60% regression accuracy with 40% instruction adherence and safety compliance. Comparative evaluation across 41 models uncovers a Precision-Controllability Dichotomy: traditional forecasters achieve superior MAE of 7.01 but lack semantic reasoning capabilities, while LLMs gain controllability with 86--89% instruction-following at the cost of 11--14 MAE precision. Phase-stratified analysis further exposes a Dynamic Complexity Gap-LLM performance degrades sharply in high-workload phases such as Climb and Approach, suggesting brittle implicit physics models. These empirical discoveries motivate hybrid architectures combining LLMs' symbolic reasoning with specialized forecasters' numerical precision. PilotBench provides a rigorous foundation for advancing embodied AI in safety-constrained domains.
X-World: Controllable Ego-Centric Multi-Camera World Models for Scalable End-to-End Driving
Mar 20, 2026Scalable and reliable evaluation is increasingly critical in the end-to-end era of autonomous driving, where vision--language--action (VLA) policies directly map raw sensor streams to driving actions. Yet, current evaluation pipelines still rely heavily on real-world road testing, which is costly, biased toward limited scenario coverage, and difficult to reproduce. These challenges motivate a real-world simulator that can generate realistic future observations under proposed actions, while remaining controllable and stable over long horizons. We present X-World, an action-conditioned multi-camera generative world model that simulates future observations directly in video space. Given synchronized multi-view camera history and a future action sequence, X-World generates future multi-camera video streams that follow the commanded actions. To ensure reproducible and editable scene rollouts, X-World further supports optional controls over dynamic traffic agents and static road elements, and retains a text-prompt interface for appearance-level control (e.g., weather and time of day). Beyond world simulation, X-World also enables video style transfer by conditioning on appearance prompts while preserving the underlying action and scene dynamics. At the core of X-World is a multi-view latent video generator designed to explicitly encourage cross-view geometric consistency and temporal coherence under diverse control signals. Experiments show that X-World achieves high-quality multi-view video generation with (i) strong view consistency across cameras, (ii) stable temporal dynamics over long rollouts, and (iii) high controllability with strict action following and faithful adherence to optional scene controls. These properties make X-World a practical foundation for scalable and reproducible evaluation.
DiffPlace: Street View Generation via Place-Controllable Diffusion Model Enhancing Place Recognition
Feb 12, 2026Generative models have advanced significantly in realistic image synthesis, with diffusion models excelling in quality and stability. Recent multi-view diffusion models improve 3D-aware street view generation, but they struggle to produce place-aware and background-consistent urban scenes from text, BEV maps, and object bounding boxes. This limits their effectiveness in generating realistic samples for place recognition tasks. To address these challenges, we propose DiffPlace, a novel framework that introduces a place-ID controller to enable place-controllable multi-view image generation. The place-ID controller employs linear projection, perceiver transformer, and contrastive learning to map place-ID embeddings into a fixed CLIP space, allowing the model to synthesize images with consistent background buildings while flexibly modifying foreground objects and weather conditions. Extensive experiments, including quantitative comparisons and augmented training evaluations, demonstrate that DiffPlace outperforms existing methods in both generation quality and training support for visual place recognition. Our results highlight the potential of generative models in enhancing scene-level and place-aware synthesis, providing a valuable approach for improving place recognition in autonomous driving
CASL: Concept-Aligned Sparse Latents for Interpreting Diffusion Models
Jan 21, 2026Internal activations of diffusion models encode rich semantic information, but interpreting such representations remains challenging. While Sparse Autoencoders (SAEs) have shown promise in disentangling latent representations, existing SAE-based methods for diffusion model understanding rely on unsupervised approaches that fail to align sparse features with human-understandable concepts. This limits their ability to provide reliable semantic control over generated images. We introduce CASL (Concept-Aligned Sparse Latents), a supervised framework that aligns sparse latent dimensions of diffusion models with semantic concepts. CASL first trains an SAE on frozen U-Net activations to obtain disentangled latent representations, and then learns a lightweight linear mapping that associates each concept with a small set of relevant latent dimensions. To validate the semantic meaning of these aligned directions, we propose CASL-Steer, a controlled latent intervention that shifts activations along the learned concept axis. Unlike editing methods, CASL-Steer is used solely as a causal probe to reveal how concept-aligned latents influence generated content. We further introduce the Editing Precision Ratio (EPR), a metric that jointly measures concept specificity and the preservation of unrelated attributes. Experiments show that our method achieves superior editing precision and interpretability compared to existing approaches. To the best of our knowledge, this is the first work to achieve supervised alignment between latent representations and semantic concepts in diffusion models.
FutureX: Enhance End-to-End Autonomous Driving via Latent Chain-of-Thought World Model
Dec 12, 2025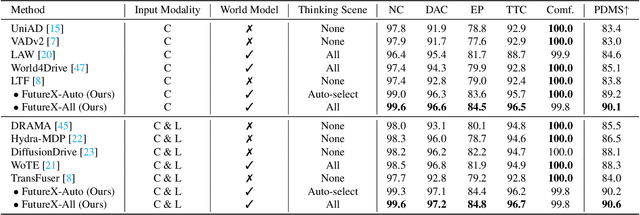
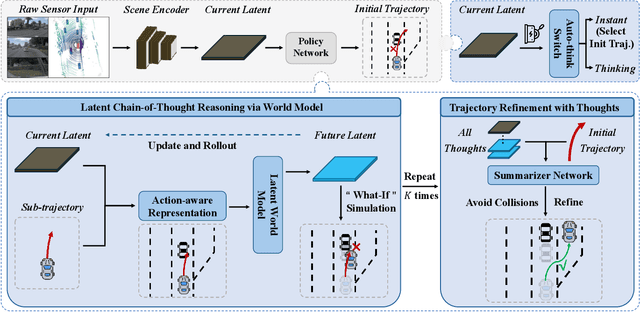

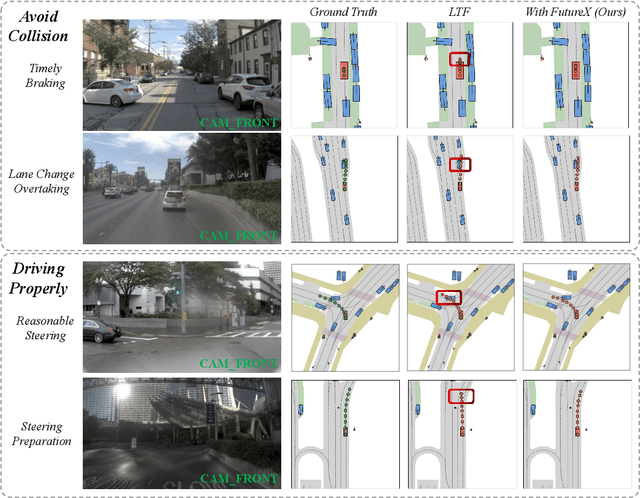
In autonomous driving, end-to-end planners learn scene representations from raw sensor data and utilize them to generate a motion plan or control actions. However, exclusive reliance on the current scene for motion planning may result in suboptimal responses in highly dynamic traffic environments where ego actions further alter the future scene. To model the evolution of future scenes, we leverage the World Model to represent how the ego vehicle and its environment interact and change over time, which entails complex reasoning. The Chain of Thought (CoT) offers a promising solution by forecasting a sequence of future thoughts that subsequently guide trajectory refinement. In this paper, we propose FutureX, a CoT-driven pipeline that enhances end-to-end planners to perform complex motion planning via future scene latent reasoning and trajectory refinement. Specifically, the Auto-think Switch examines the current scene and decides whether additional reasoning is required to yield a higher-quality motion plan. Once FutureX enters the Thinking mode, the Latent World Model conducts a CoT-guided rollout to predict future scene representation, enabling the Summarizer Module to further refine the motion plan. Otherwise, FutureX operates in an Instant mode to generate motion plans in a forward pass for relatively simple scenes. Extensive experiments demonstrate that FutureX enhances existing methods by producing more rational motion plans and fewer collisions without compromising efficiency, thereby achieving substantial overall performance gains, e.g., 6.2 PDMS improvement for TransFuser on NAVSIM. Code will be released.
Optimization-Guided Diffusion for Interactive Scene Generation
Dec 11, 2025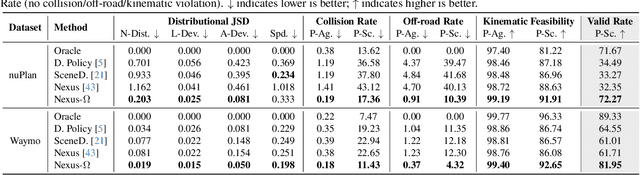
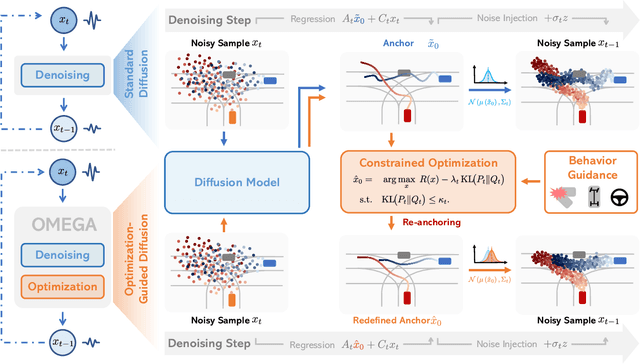
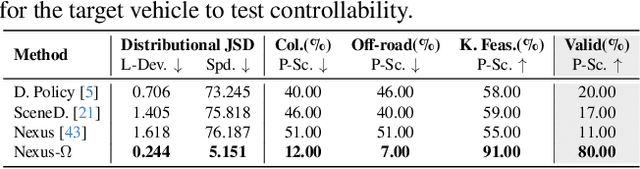
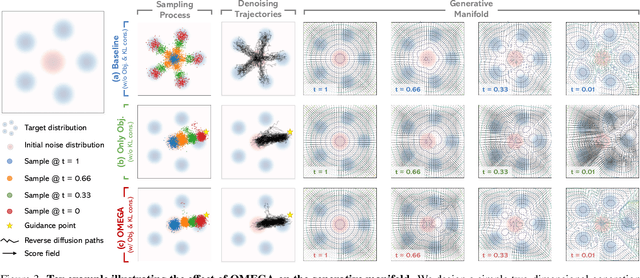
Realistic and diverse multi-agent driving scenes are crucial for evaluating autonomous vehicles, but safety-critical events which are essential for this task are rare and underrepresented in driving datasets. Data-driven scene generation offers a low-cost alternative by synthesizing complex traffic behaviors from existing driving logs. However, existing models often lack controllability or yield samples that violate physical or social constraints, limiting their usability. We present OMEGA, an optimization-guided, training-free framework that enforces structural consistency and interaction awareness during diffusion-based sampling from a scene generation model. OMEGA re-anchors each reverse diffusion step via constrained optimization, steering the generation towards physically plausible and behaviorally coherent trajectories. Building on this framework, we formulate ego-attacker interactions as a game-theoretic optimization in the distribution space, approximating Nash equilibria to generate realistic, safety-critical adversarial scenarios. Experiments on nuPlan and Waymo show that OMEGA improves generation realism, consistency, and controllability, increasing the ratio of physically and behaviorally valid scenes from 32.35% to 72.27% for free exploration capabilities, and from 11% to 80% for controllability-focused generation. Our approach can also generate $5\times$ more near-collision frames with a time-to-collision under three seconds while maintaining the overall scene realism.
DPC-QA Net: A No-Reference Dual-Stream Perceptual and Cellular Quality Assessment Network for Histopathology Images
Sep 19, 2025Reliable whole slide imaging (WSI) hinges on image quality,yet staining artefacts, defocus, and cellular degradations are common. We present DPC-QA Net, a no-reference dual-stream network that couples wavelet-based global difference perception with cellular quality assessment from nuclear and membrane embeddings via an Aggr-RWKV module. Cross-attention fusion and multi-term losses align perceptual and cellular cues. Across different datasets, our model detects staining, membrane, and nuclear issues with >92% accuracy and aligns well with usability scores; on LIVEC and KonIQ it outperforms state-of-the-art NR-IQA. A downstream study further shows strong positive correlations between predicted quality and cell recognition accuracy (e.g., nuclei PQ/Dice, membrane boundary F-score), enabling practical pre-screening of WSI regions for computational pathology.
DinoCompanion: An Attachment-Theory Informed Multimodal Robot for Emotionally Responsive Child-AI Interaction
Jun 14, 2025Children's emotional development fundamentally relies on secure attachment relationships, yet current AI companions lack the theoretical foundation to provide developmentally appropriate emotional support. We introduce DinoCompanion, the first attachment-theory-grounded multimodal robot for emotionally responsive child-AI interaction. We address three critical challenges in child-AI systems: the absence of developmentally-informed AI architectures, the need to balance engagement with safety, and the lack of standardized evaluation frameworks for attachment-based capabilities. Our contributions include: (i) a multimodal dataset of 128 caregiver-child dyads containing 125,382 annotated clips with paired preference-risk labels, (ii) CARPO (Child-Aware Risk-calibrated Preference Optimization), a novel training objective that maximizes engagement while applying epistemic-uncertainty-weighted risk penalties, and (iii) AttachSecure-Bench, a comprehensive evaluation benchmark covering ten attachment-centric competencies with strong expert consensus (\k{appa}=0.81). DinoCompanion achieves state-of-the-art performance (57.15%), outperforming GPT-4o (50.29%) and Claude-3.7-Sonnet (53.43%), with exceptional secure base behaviors (72.99%, approaching human expert levels of 78.4%) and superior attachment risk detection (69.73%). Ablations validate the critical importance of multimodal fusion, uncertainty-aware risk modeling, and hierarchical memory for coherent, emotionally attuned interactions.