 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildRayZer: Self-supervised Large View Synthesis in Dynamic Environments
Jan 15, 2026We present WildRayZer, a self-supervised framework for novel view synthesis (NVS) in dynamic environments where both the camera and objects move. Dynamic content breaks the multi-view consistency that static NVS models rely on, leading to ghosting, hallucinated geometry, and unstable pose estimation. WildRayZer addresses this by performing an analysis-by-synthesis test: a camera-only static renderer explains rigid structure, and its residuals reveal transient regions. From these residuals, we construct pseudo motion masks, distill a motion estimator, and use it to mask input tokens and gate loss gradients so supervision focuses on cross-view background completion. To enable large-scale training and evaluation, we curate Dynamic RealEstate10K (D-RE10K), a real-world dataset of 15K casually captured dynamic sequences, and D-RE10K-iPhone, a paired transient and clean benchmark for sparse-view transient-aware NVS. Experiments show that WildRayZer consistently outperforms optimization-based and feed-forward baselines in both transient-region removal and full-frame NVS quality with a single feed-forward pass.
LabelAny3D: Label Any Object 3D in the Wild
Jan 04, 2026Detecting objects in 3D space from monocular input is crucial for applications ranging from robotics to scene understanding. Despite advanced performance in the indoor and autonomous driving domains, existing monocular 3D detection models struggle with in-the-wild images due to the lack of 3D in-the-wild datasets and the challenges of 3D annotation. We introduce LabelAny3D, an \emph{analysis-by-synthesis} framework that reconstructs holistic 3D scenes from 2D images to efficiently produce high-quality 3D bounding box annotations. Built on this pipeline, we present COCO3D, a new benchmark for open-vocabulary monocular 3D detection, derived from the MS-COCO dataset and covering a wide range of object categories absent from existing 3D datasets. Experiments show that annotations generated by LabelAny3D improve monocular 3D detection performance across multiple benchmarks, outperforming prior auto-labeling approaches in quality. These results demonstrate the promise of foundation-model-driven annotation for scaling up 3D recognition in realistic, open-world settings.
Empowering Dynamic Urban Navigation with Stereo and Mid-Level Vision
Dec 11, 2025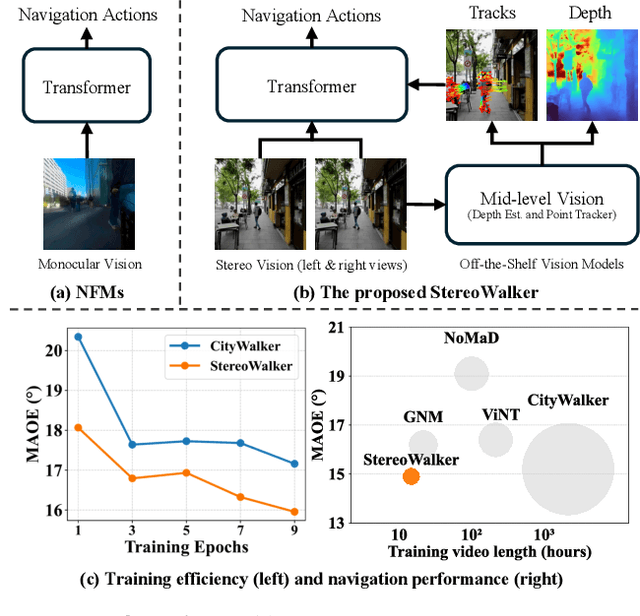
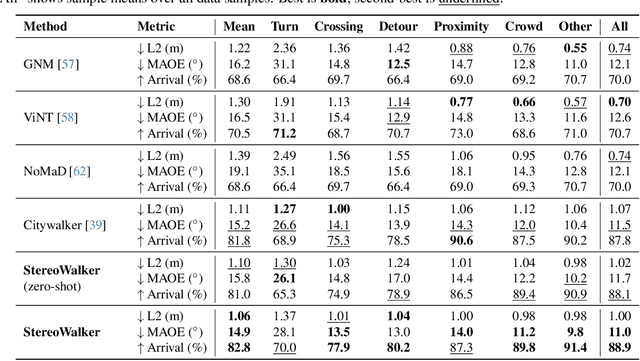
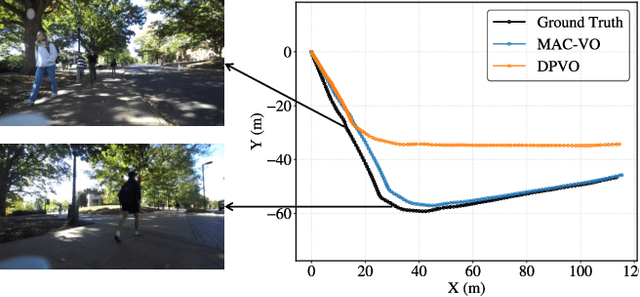
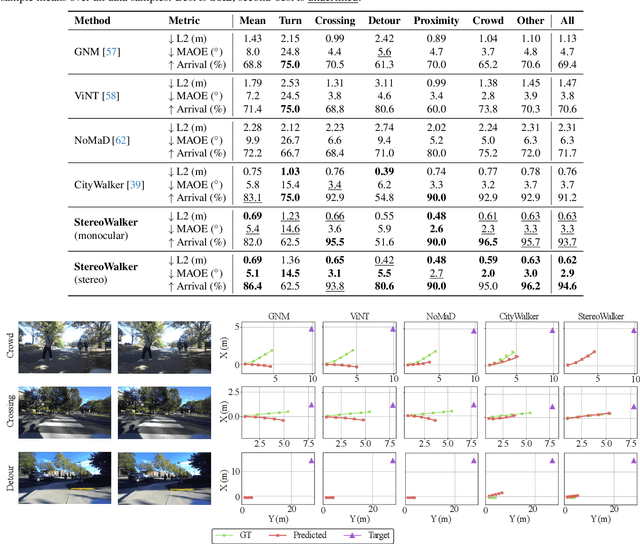
The success of foundation models in language and vision motivated research in fully end-to-end robot navigation foundation models (NFMs). NFMs directly map monocular visual input to control actions and ignore mid-level vision modules (tracking, depth estimation, etc) entirely. While the assumption that vision capabilities will emerge implicitly is compelling, it requires large amounts of pixel-to-action supervision that are difficult to obtain. The challenge is especially pronounced in dynamic and unstructured settings, where robust navigation requires precise geometric and dynamic understanding, while the depth-scale ambiguity in monocular views further limits accurate spatial reasoning. In this paper, we show that relying on monocular vision and ignoring mid-level vision priors is inefficient. We present StereoWalker, which augments NFMs with stereo inputs and explicit mid-level vision such as depth estimation and dense pixel tracking. Our intuition is straightforward: stereo inputs resolve the depth-scale ambiguity, and modern mid-level vision models provide reliable geometric and motion structure in dynamic scenes. We also curate a large stereo navigation dataset with automatic action annotation from Internet stereo videos to support training of StereoWalker and to facilitate future research. Through our experiments, we find that mid-level vision enables StereoWalker to achieve a comparable performance as the state-of-the-art using only 1.5% of the training data, and surpasses the state-of-the-art using the full data. We also observe that stereo vision yields higher navigation performance than monocular input.
Point-MoE: Towards Cross-Domain Generalization in 3D Semantic Segmentation via Mixture-of-Experts
May 29, 2025While scaling laws have transformed natural language processing and computer vision, 3D point cloud understanding has yet to reach that stage. This can be attributed to both the comparatively smaller scale of 3D datasets, as well as the disparate sources of the data itself. Point clouds are captured by diverse sensors (e.g., depth cameras, LiDAR) across varied domains (e.g., indoor, outdoor), each introducing unique scanning patterns, sampling densities, and semantic biases. Such domain heterogeneity poses a major barrier towards training unified models at scale, especially under the realistic constraint that domain labels are typically inaccessible at inference time. In this work, we propose Point-MoE, a Mixture-of-Experts architecture designed to enable large-scale, cross-domain generalization in 3D perception. We show that standard point cloud backbones degrade significantly in performance when trained on mixed-domain data, whereas Point-MoE with a simple top-k routing strategy can automatically specialize experts, even without access to domain labels. Our experiments demonstrate that Point-MoE not only outperforms strong multi-domain baselines but also generalizes better to unseen domains. This work highlights a scalable path forward for 3D understanding: letting the model discover structure in diverse 3D data, rather than imposing it via manual curation or domain supervision.
Frame In-N-Out: Unbounded Controllable Image-to-Video Generation
May 27, 2025Controllability, temporal coherence, and detail synthesis remain the most critical challenges in video generation. In this paper, we focus on a commonly used yet underexplored cinematic technique known as Frame In and Frame Out. Specifically, starting from image-to-video generation, users can control the objects in the image to naturally leave the scene or provide breaking new identity references to enter the scene, guided by user-specified motion trajectory. To support this task, we introduce a new dataset curated semi-automatically, a comprehensive evaluation protocol targeting this setting, and an efficient identity-preserving motion-controllable video Diffusion Transformer architecture. Our evaluation shows that our proposed approach significantly outperforms existing baselines.
Learning 3D Representations from Procedural 3D Programs
Nov 25, 2024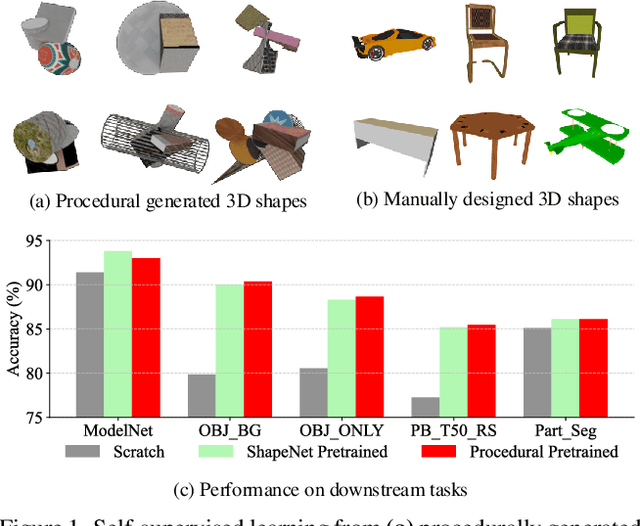
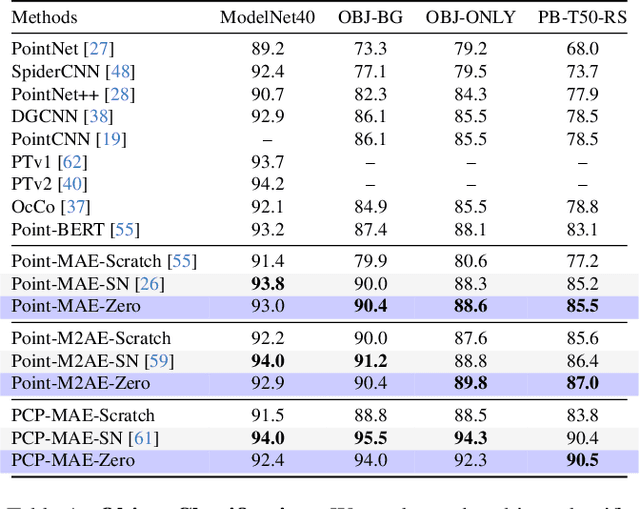
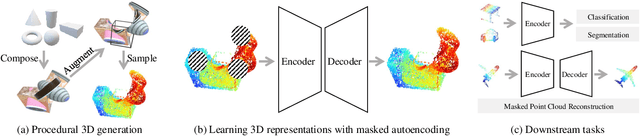
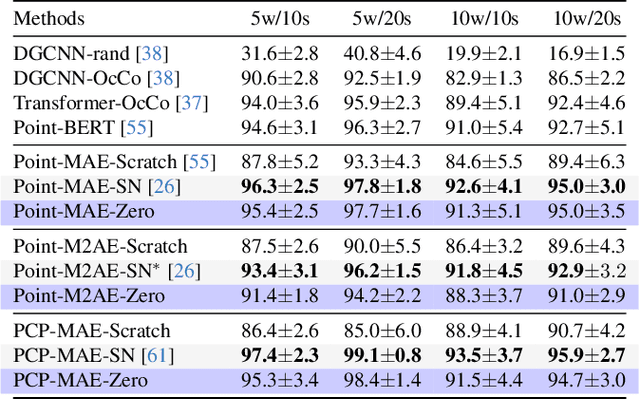
Self-supervised learning has emerged as a promising approach for acquiring transferable 3D representations from unlabeled 3D point clouds. Unlike 2D images, which are widely accessible, acquiring 3D assets requires specialized expertise or professional 3D scanning equipment, making it difficult to scale and raising copyright concerns. To address these challenges, we propose learning 3D representations from procedural 3D programs that automatically generate 3D shapes using simple primitives and augmentations. Remarkably, despite lacking semantic content, the 3D representations learned from this synthesized dataset perform on par with state-of-the-art representations learned from semantically recognizable 3D models (e.g., airplanes) across various downstream 3D tasks, including shape classification, part segmentation, and masked point cloud completion. Our analysis further suggests that current self-supervised learning methods primarily capture geometric structures rather than high-level semantics.
Probing the Mid-level Vision Capabilities of Self-Supervised Learning
Nov 25, 2024



Mid-level vision capabilities - such as generic object localization and 3D geometric understanding - are not only fundamental to human vision but are also crucial for many real-world applications of computer vision. These abilities emerge with minimal supervision during the early stages of human visual development. Despite their significance, current self-supervised learning (SSL) approaches are primarily designed and evaluated for high-level recognition tasks, leaving their mid-level vision capabilities largely unexamined. In this study, we introduce a suite of benchmark protocols to systematically assess mid-level vision capabilities and present a comprehensive, controlled evaluation of 22 prominent SSL models across 8 mid-level vision tasks. Our experiments reveal a weak correlation between mid-level and high-level task performance. We also identify several SSL methods with highly imbalanced performance across mid-level and high-level capabilities, as well as some that excel in both. Additionally, we investigate key factors contributing to mid-level vision performance, such as pretraining objectives and network architectures. Our study provides a holistic and timely view of what SSL models have learned, complementing existing research that primarily focuses on high-level vision tasks. We hope our findings guide future SSL research to benchmark models not only on high-level vision tasks but on mid-level as well.
Open Vocabulary Monocular 3D Object Detection
Nov 25, 2024In this work, we pioneer the study of open-vocabulary monocular 3D object detection, a novel task that aims to detect and localize objects in 3D space from a single RGB image without limiting detection to a predefined set of categories. We formalize this problem, establish baseline methods, and introduce a class-agnostic approach that leverages open-vocabulary 2D detectors and lifts 2D bounding boxes into 3D space. Our approach decouples the recognition and localization of objects in 2D from the task of estimating 3D bounding boxes, enabling generalization across unseen categories. Additionally, we propose a target-aware evaluation protocol to address inconsistencies in existing datasets, improving the reliability of model performance assessment. Extensive experiments on the Omni3D dataset demonstrate the effectiveness of the proposed method in zero-shot 3D detection for novel object categories, validating its robust generalization capabilities. Our method and evaluation protocols contribute towards the development of open-vocabulary object detection models that can effectively operate in real-world, category-diverse environments.
Machine Unlearning of Pre-trained Large Language Models
Feb 27, 2024This study investigates the concept of the `right to be forgotten' within the context of large language models (LLMs). We explore machine unlearning as a pivotal solution, with a focus on pre-trained models--a notably under-researched area. Our research delineates a comprehensive framework for machine unlearning in pre-trained LLMs, encompassing a critical analysis of seven diverse unlearning methods. Through rigorous evaluation using curated datasets from arXiv, books, and GitHub, we establish a robust benchmark for unlearning performance, demonstrating that these methods are over $10^5$ times more computationally efficient than retraining. Our results show that integrating gradient ascent with gradient descent on in-distribution data improves hyperparameter robustness. We also provide detailed guidelines for efficient hyperparameter tuning in the unlearning process. Our findings advance the discourse on ethical AI practices, offering substantive insights into the mechanics of machine unlearning for pre-trained LLMs and underscoring the potential for responsible AI development.
LU-NeRF: Scene and Pose Estimation by Synchronizing Local Unposed NeRFs
Jun 08, 2023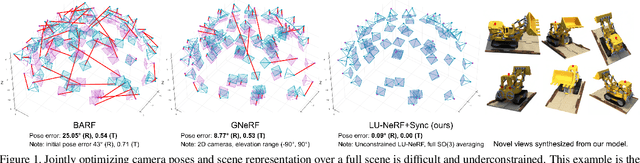
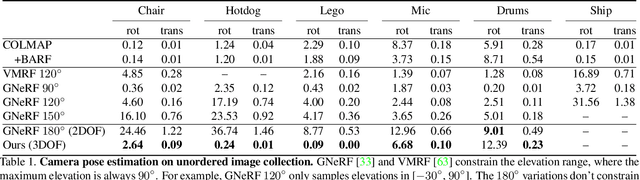
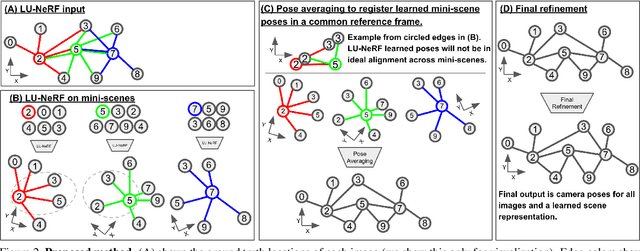
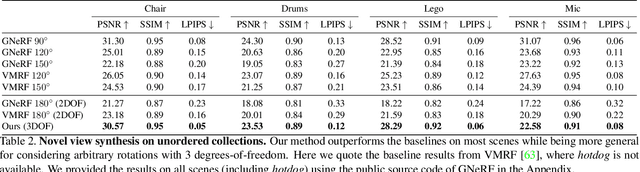
A critical obstacle preventing NeRF models from being deployed broadly in the wild is their reliance on accurate camera poses. Consequently, there is growing interest in extending NeRF models to jointly optimize camera poses and scene representation, which offers an alternative to off-the-shelf SfM pipelines which have well-understood failure modes. Existing approaches for unposed NeRF operate under limited assumptions, such as a prior pose distribution or coarse pose initialization, making them less effective in a general setting. In this work, we propose a novel approach, LU-NeRF, that jointly estimates camera poses and neural radiance fields with relaxed assumptions on pose configuration. Our approach operates in a local-to-global manner, where we first optimize over local subsets of the data, dubbed mini-scenes. LU-NeRF estimates local pose and geometry for this challenging few-shot task. The mini-scene poses are brought into a global reference frame through a robust pose synchronization step, where a final global optimization of pose and scene can be performed. We show our LU-NeRF pipeline outperforms prior attempts at unposed NeRF without making restrictive assumptions on the pose prior. This allows us to operate in the general SE(3) pose setting, unlike the baselines. Our results also indicate our model can be complementary to feature-based SfM pipelines as it compares favorably to COLMAP on low-texture and low-resolution images.