 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildRayZer: Self-supervised Large View Synthesis in Dynamic Environments
Jan 15, 2026We present WildRayZer, a self-supervised framework for novel view synthesis (NVS) in dynamic environments where both the camera and objects move. Dynamic content breaks the multi-view consistency that static NVS models rely on, leading to ghosting, hallucinated geometry, and unstable pose estimation. WildRayZer addresses this by performing an analysis-by-synthesis test: a camera-only static renderer explains rigid structure, and its residuals reveal transient regions. From these residuals, we construct pseudo motion masks, distill a motion estimator, and use it to mask input tokens and gate loss gradients so supervision focuses on cross-view background completion. To enable large-scale training and evaluation, we curate Dynamic RealEstate10K (D-RE10K), a real-world dataset of 15K casually captured dynamic sequences, and D-RE10K-iPhone, a paired transient and clean benchmark for sparse-view transient-aware NVS. Experiments show that WildRayZer consistently outperforms optimization-based and feed-forward baselines in both transient-region removal and full-frame NVS quality with a single feed-forward pass.
Empowering Dynamic Urban Navigation with Stereo and Mid-Level Vision
Dec 11, 2025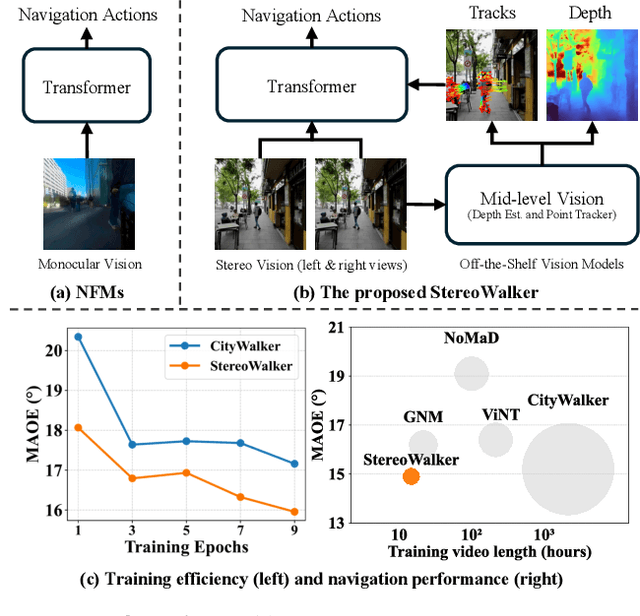
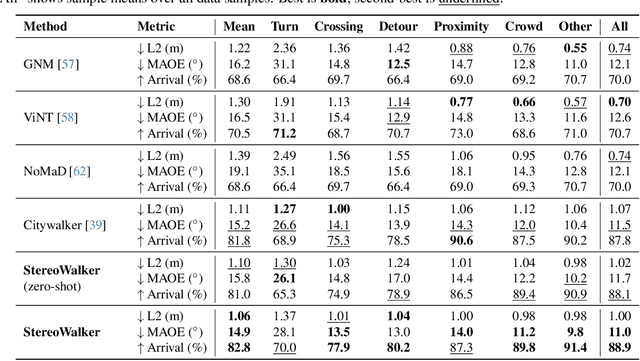
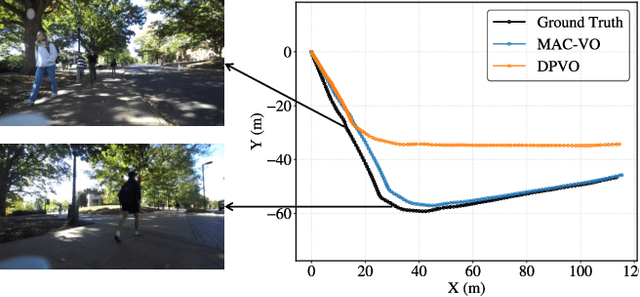
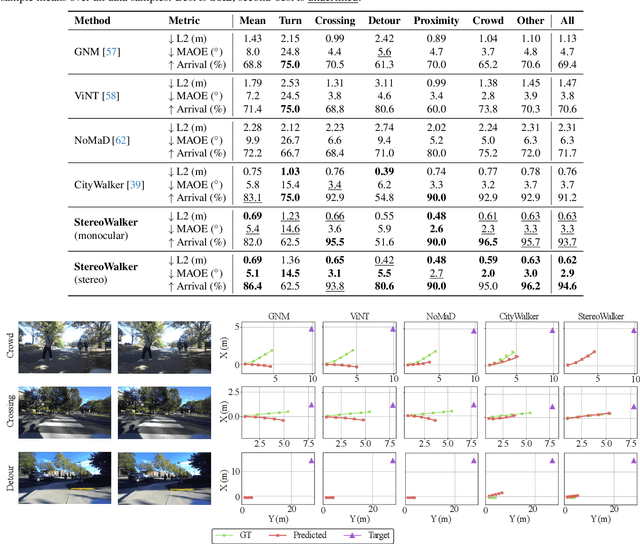
The success of foundation models in language and vision motivated research in fully end-to-end robot navigation foundation models (NFMs). NFMs directly map monocular visual input to control actions and ignore mid-level vision modules (tracking, depth estimation, etc) entirely. While the assumption that vision capabilities will emerge implicitly is compelling, it requires large amounts of pixel-to-action supervision that are difficult to obtain. The challenge is especially pronounced in dynamic and unstructured settings, where robust navigation requires precise geometric and dynamic understanding, while the depth-scale ambiguity in monocular views further limits accurate spatial reasoning. In this paper, we show that relying on monocular vision and ignoring mid-level vision priors is inefficient. We present StereoWalker, which augments NFMs with stereo inputs and explicit mid-level vision such as depth estimation and dense pixel tracking. Our intuition is straightforward: stereo inputs resolve the depth-scale ambiguity, and modern mid-level vision models provide reliable geometric and motion structure in dynamic scenes. We also curate a large stereo navigation dataset with automatic action annotation from Internet stereo videos to support training of StereoWalker and to facilitate future research. Through our experiments, we find that mid-level vision enables StereoWalker to achieve a comparable performance as the state-of-the-art using only 1.5% of the training data, and surpasses the state-of-the-art using the full data. We also observe that stereo vision yields higher navigation performance than monocular input.
On the Convergence of Large Language Model Optimizer for Black-Box Network Management
Jul 03, 2025Future wireless networks are expected to incorporate diverse services that often lack general mathematical models. To address such black-box network management tasks, the large language model (LLM) optimizer framework, which leverages pretrained LLMs as optimization agents, has recently been promoted as a promising solution. This framework utilizes natural language prompts describing the given optimization problems along with past solutions generated by LLMs themselves. As a result, LLMs can obtain efficient solutions autonomously without knowing the mathematical models of the objective functions. Although the viability of the LLM optimizer (LLMO) framework has been studied in various black-box scenarios, it has so far been limited to numerical simulations. For the first time, this paper establishes a theoretical foundation for the LLMO framework. With careful investigations of LLM inference steps, we can interpret the LLMO procedure as a finite-state Markov chain, and prove the convergence of the framework. Our results are extended to a more advanced multiple LLM architecture, where the impact of multiple LLMs is rigorously verified in terms of the convergence rate. Comprehensive numerical simulations validate our theoretical results and provide a deeper understanding of the underlying mechanisms of the LLMO framework.
Point-MoE: Towards Cross-Domain Generalization in 3D Semantic Segmentation via Mixture-of-Experts
May 29, 2025While scaling laws have transformed natural language processing and computer vision, 3D point cloud understanding has yet to reach that stage. This can be attributed to both the comparatively smaller scale of 3D datasets, as well as the disparate sources of the data itself. Point clouds are captured by diverse sensors (e.g., depth cameras, LiDAR) across varied domains (e.g., indoor, outdoor), each introducing unique scanning patterns, sampling densities, and semantic biases. Such domain heterogeneity poses a major barrier towards training unified models at scale, especially under the realistic constraint that domain labels are typically inaccessible at inference time. In this work, we propose Point-MoE, a Mixture-of-Experts architecture designed to enable large-scale, cross-domain generalization in 3D perception. We show that standard point cloud backbones degrade significantly in performance when trained on mixed-domain data, whereas Point-MoE with a simple top-k routing strategy can automatically specialize experts, even without access to domain labels. Our experiments demonstrate that Point-MoE not only outperforms strong multi-domain baselines but also generalizes better to unseen domains. This work highlights a scalable path forward for 3D understanding: letting the model discover structure in diverse 3D data, rather than imposing it via manual curation or domain supervision.
Deep Learning Inference on Heterogeneous Mobile Processors: Potentials and Pitfalls
May 03, 2024



There is a growing demand to deploy computation-intensive deep learning (DL) models on resource-constrained mobile devices for real-time intelligent applications. Equipped with a variety of processing units such as CPUs, GPUs, and NPUs, the mobile devices hold potential to accelerate DL inference via parallel execution across heterogeneous processors. Various efficient parallel methods have been explored to optimize computation distribution, achieve load balance, and minimize communication cost across processors. Yet their practical effectiveness in the dynamic and diverse real-world mobile environment is less explored. This paper presents a holistic empirical study to assess the capabilities and challenges associated with parallel DL inference on heterogeneous mobile processors. Through carefully designed experiments covering various DL models, mobile software/hardware environments, workload patterns, and resource availability, we identify limitations of existing techniques and highlight opportunities for cross-level optimization.