 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Dynamic Urban Navigation with Stereo and Mid-Level Vision
Dec 11, 2025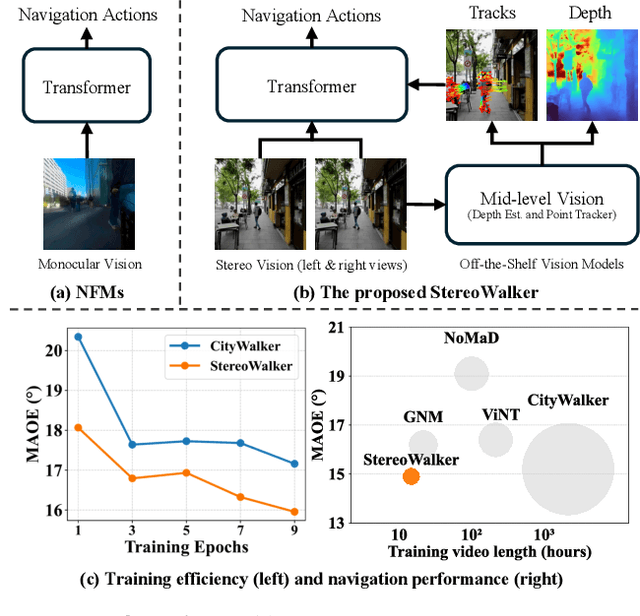
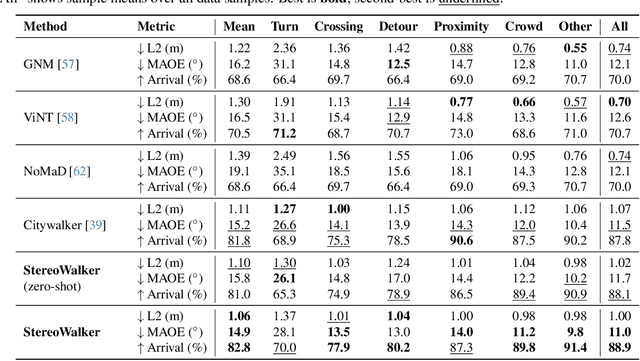
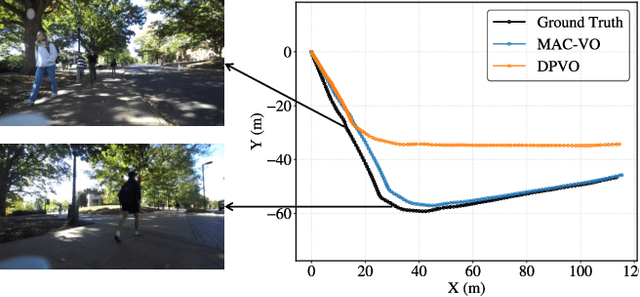
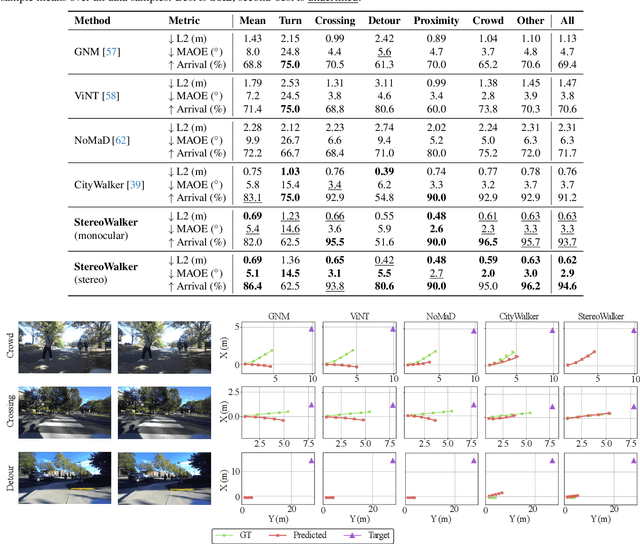
The success of foundation models in language and vision motivated research in fully end-to-end robot navigation foundation models (NFMs). NFMs directly map monocular visual input to control actions and ignore mid-level vision modules (tracking, depth estimation, etc) entirely. While the assumption that vision capabilities will emerge implicitly is compelling, it requires large amounts of pixel-to-action supervision that are difficult to obtain. The challenge is especially pronounced in dynamic and unstructured settings, where robust navigation requires precise geometric and dynamic understanding, while the depth-scale ambiguity in monocular views further limits accurate spatial reasoning. In this paper, we show that relying on monocular vision and ignoring mid-level vision priors is inefficient. We present StereoWalker, which augments NFMs with stereo inputs and explicit mid-level vision such as depth estimation and dense pixel tracking. Our intuition is straightforward: stereo inputs resolve the depth-scale ambiguity, and modern mid-level vision models provide reliable geometric and motion structure in dynamic scenes. We also curate a large stereo navigation dataset with automatic action annotation from Internet stereo videos to support training of StereoWalker and to facilitate future research. Through our experiments, we find that mid-level vision enables StereoWalker to achieve a comparable performance as the state-of-the-art using only 1.5% of the training data, and surpasses the state-of-the-art using the full data. We also observe that stereo vision yields higher navigation performance than monocular input.
DR. Nav: Semantic-Geometric Representations for Proactive Dead-End Recovery and Navigation
Nov 16, 2025We present DR. Nav (Dead-End Recovery-aware Navigation), a novel approach to autonomous navigation in scenarios where dead-end detection and recovery are critical, particularly in unstructured environments where robots must handle corners, vegetation occlusions, and blocked junctions. DR. Nav introduces a proactive strategy for navigation in unmapped environments without prior assumptions. Our method unifies dead-end prediction and recovery by generating a single, continuous, real-time semantic cost map. Specifically, DR. Nav leverages cross-modal RGB-LiDAR fusion with attention-based filtering to estimate per-cell dead-end likelihoods and recovery points, which are continuously updated through Bayesian inference to enhance robustness. Unlike prior mapping methods that only encode traversability, DR. Nav explicitly incorporates recovery-aware risk into the navigation cost map, enabling robots to anticipate unsafe regions and plan safer alternative trajectories. We evaluate DR. Nav across multiple dense indoor and outdoor scenarios and demonstrate an increase of 83.33% in accuracy in detection, a 52.4% reduction in time-to-goal (path efficiency), compared to state-of-the-art planners such as DWA, MPPI, and Nav2 DWB. Furthermore, the dead-end classifier functions
Vi-LAD: Vision-Language Attention Distillation for Socially-Aware Robot Navigation in Dynamic Environments
Mar 12, 2025We introduce Vision-Language Attention Distillation (Vi-LAD), a novel approach for distilling socially compliant navigation knowledge from a large Vision-Language Model (VLM) into a lightweight transformer model for real-time robotic navigation. Unlike traditional methods that rely on expert demonstrations or human-annotated datasets, Vi-LAD performs knowledge distillation and fine-tuning at the intermediate layer representation level (i.e., attention maps) by leveraging the backbone of a pre-trained vision-action model. These attention maps highlight key navigational regions in a given scene, which serve as implicit guidance for socially aware motion planning. Vi-LAD fine-tunes a transformer-based model using intermediate attention maps extracted from the pre-trained vision-action model, combined with attention-like semantic maps constructed from a large VLM. To achieve this, we introduce a novel attention-level distillation loss that fuses knowledge from both sources, generating augmented attention maps with enhanced social awareness. These refined attention maps are then utilized as a traversability costmap within a socially aware model predictive controller (MPC) for navigation. We validate our approach through real-world experiments on a Husky wheeled robot, demonstrating significant improvements over state-of-the-art (SOTA) navigation methods. Our results show up to 14.2% - 50% improvement in success rate, which highlights the effectiveness of Vi-LAD in enabling socially compliant and efficient robot navigation.
Robot Navigation Using Physically Grounded Vision-Language Models in Outdoor Environments
Sep 30, 2024



We present a novel autonomous robot navigation algorithm for outdoor environments that is capable of handling diverse terrain traversability conditions. Our approach, VLM-GroNav, uses vision-language models (VLMs) and integrates them with physical grounding that is used to assess intrinsic terrain properties such as deformability and slipperiness. We use proprioceptive-based sensing, which provides direct measurements of these physical properties, and enhances the overall semantic understanding of the terrains. Our formulation uses in-context learning to ground the VLM's semantic understanding with proprioceptive data to allow dynamic updates of traversability estimates based on the robot's real-time physical interactions with the environment. We use the updated traversability estimations to inform both the local and global planners for real-time trajectory replanning. We validate our method on a legged robot (Ghost Vision 60) and a wheeled robot (Clearpath Husky), in diverse real-world outdoor environments with different deformable and slippery terrains. In practice, we observe significant improvements over state-of-the-art methods by up to 50% increase in navigation success rate.
BehAV: Behavioral Rule Guided Autonomy Using VLMs for Robot Navigation in Outdoor Scenes
Sep 24, 2024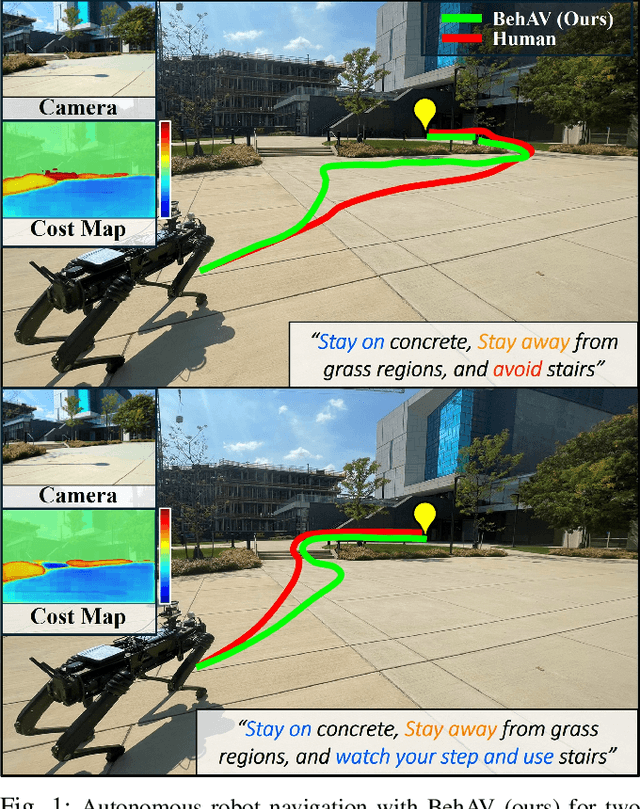
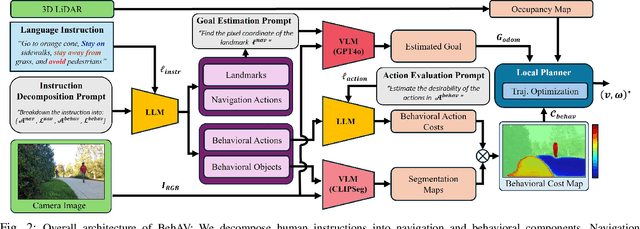

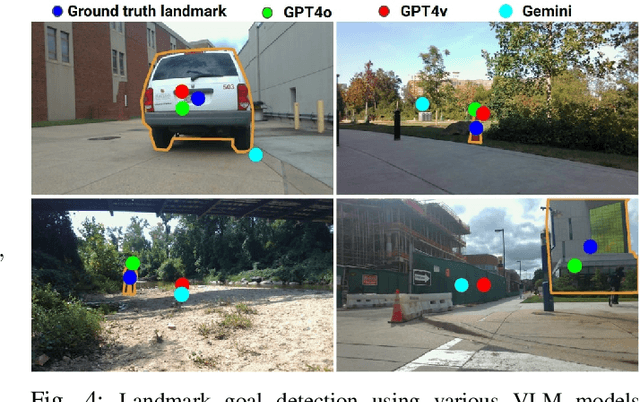
We present BehAV, a novel approach for autonomous robot navigation in outdoor scenes guided by human instructions and leveraging Vision Language Models (VLMs). Our method interprets human commands using a Large Language Model (LLM) and categorizes the instructions into navigation and behavioral guidelines. Navigation guidelines consist of directional commands (e.g., "move forward until") and associated landmarks (e.g., "the building with blue windows"), while behavioral guidelines encompass regulatory actions (e.g., "stay on") and their corresponding objects (e.g., "pavements"). We use VLMs for their zero-shot scene understanding capabilities to estimate landmark locations from RGB images for robot navigation. Further, we introduce a novel scene representation that utilizes VLMs to ground behavioral rules into a behavioral cost map. This cost map encodes the presence of behavioral objects within the scene and assigns costs based on their regulatory actions. The behavioral cost map is integrated with a LiDAR-based occupancy map for navigation. To navigate outdoor scenes while adhering to the instructed behaviors, we present an unconstrained Model Predictive Control (MPC)-based planner that prioritizes both reaching landmarks and following behavioral guidelines. We evaluate the performance of BehAV on a quadruped robot across diverse real-world scenarios, demonstrating a 22.49% improvement in alignment with human-teleoperated actions, as measured by Frechet distance, and achieving a 40% higher navigation success rate compared to state-of-the-art methods.
AMCO: Adaptive Multimodal Coupling of Vision and Proprioception for Quadruped Robot Navigation in Outdoor Environments
Mar 20, 2024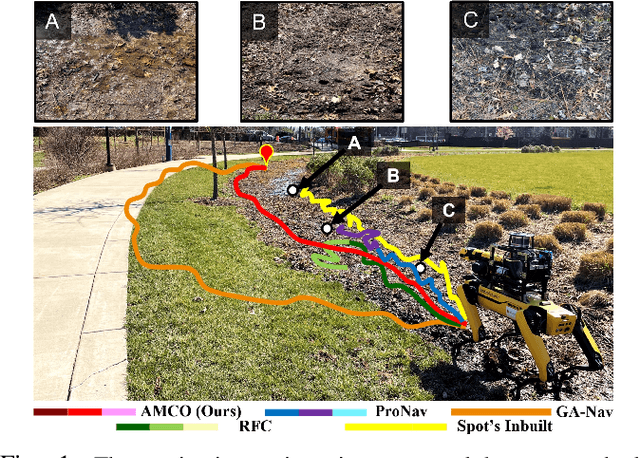
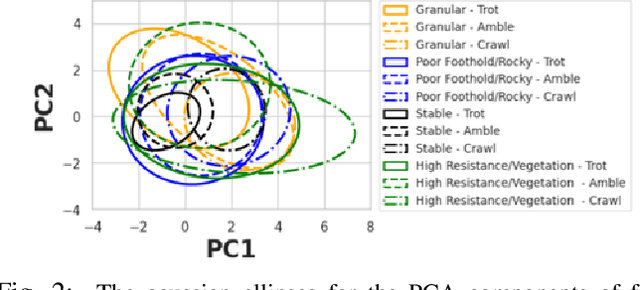
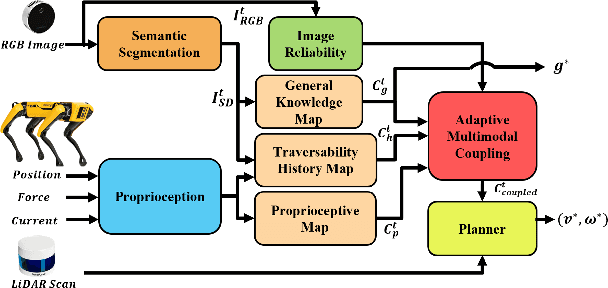

We present AMCO, a novel navigation method for quadruped robots that adaptively combines vision-based and proprioception-based perception capabilities. Our approach uses three cost maps: general knowledge map; traversability history map; and current proprioception map; which are derived from a robot's vision and proprioception data, and couples them to obtain a coupled traversability cost map for navigation. The general knowledge map encodes terrains semantically segmented from visual sensing, and represents a terrain's typically expected traversability. The traversability history map encodes the robot's recent proprioceptive measurements on a terrain and its semantic segmentation as a cost map. Further, the robot's present proprioceptive measurement is encoded as a cost map in the current proprioception map. As the general knowledge map and traversability history map rely on semantic segmentation, we evaluate the reliability of the visual sensory data by estimating the brightness and motion blur of input RGB images and accordingly combine the three cost maps to obtain the coupled traversability cost map used for navigation. Leveraging this adaptive coupling, the robot can depend on the most reliable input modality available. Finally, we present a novel planner that selects appropriate gaits and velocities for traversing challenging outdoor environments using the coupled traversability cost map. We demonstrate AMCO's navigation performance in different real-world outdoor environments and observe 10.8%-34.9% reduction w.r.t. two stability metrics, and up to 50% improvement in terms of success rate compared to current navigation methods.