 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOPGN: Real-time Transparent Obstacle Detection using Lidar Point Cloud Intensity for Autonomous Robot Navigation
Aug 10, 2024



We present TOPGN, a novel method for real-time transparent obstacle detection for robot navigation in unknown environments. We use a multi-layer 2D grid map representation obtained by summing the intensities of lidar point clouds that lie in multiple non-overlapping height intervals. We isolate a neighborhood of points reflected from transparent obstacles by comparing the intensities in the different 2D grid map layers. Using the neighborhood, we linearly extrapolate the transparent obstacle by computing a tangential line segment and use it to perform safe, real-time collision avoidance. Finally, we also demonstrate our transparent object isolation's applicability to mapping an environment. We demonstrate that our approach detects transparent objects made of various materials (glass, acrylic, PVC), arbitrary shapes, colors, and textures in a variety of real-world indoor and outdoor scenarios with varying lighting conditions. We compare our method with other glass/transparent object detection methods that use RGB images, 2D laser scans, etc. in these benchmark scenarios. We demonstrate superior detection accuracy in terms of F-score improvement at least by 12.74% and 38.46% decrease in mean absolute error (MAE), improved navigation success rates (at least two times better than the second-best), and a real-time inference rate (~50Hz on a mobile CPU). We will release our code and challenging benchmarks for future evaluations upon publication.
CoNVOI: Context-aware Navigation using Vision Language Models in Outdoor and Indoor Environments
Mar 22, 2024



We present ConVOI, a novel method for autonomous robot navigation in real-world indoor and outdoor environments using Vision Language Models (VLMs). We employ VLMs in two ways: first, we leverage their zero-shot image classification capability to identify the context or scenario (e.g., indoor corridor, outdoor terrain, crosswalk, etc) of the robot's surroundings, and formulate context-based navigation behaviors as simple text prompts (e.g. ``stay on the pavement"). Second, we utilize their state-of-the-art semantic understanding and logical reasoning capabilities to compute a suitable trajectory given the identified context. To this end, we propose a novel multi-modal visual marking approach to annotate the obstacle-free regions in the RGB image used as input to the VLM with numbers, by correlating it with a local occupancy map of the environment. The marked numbers ground image locations in the real-world, direct the VLM's attention solely to navigable locations, and elucidate the spatial relationships between them and terrains depicted in the image to the VLM. Next, we query the VLM to select numbers on the marked image that satisfy the context-based behavior text prompt, and construct a reference path using the selected numbers. Finally, we propose a method to extrapolate the reference trajectory when the robot's environmental context has not changed to prevent unnecessary VLM queries. We use the reference trajectory to guide a motion planner, and demonstrate that it leads to human-like behaviors (e.g. not cutting through a group of people, using crosswalks, etc.) in various real-world indoor and outdoor scenarios.
AMCO: Adaptive Multimodal Coupling of Vision and Proprioception for Quadruped Robot Navigation in Outdoor Environments
Mar 20, 2024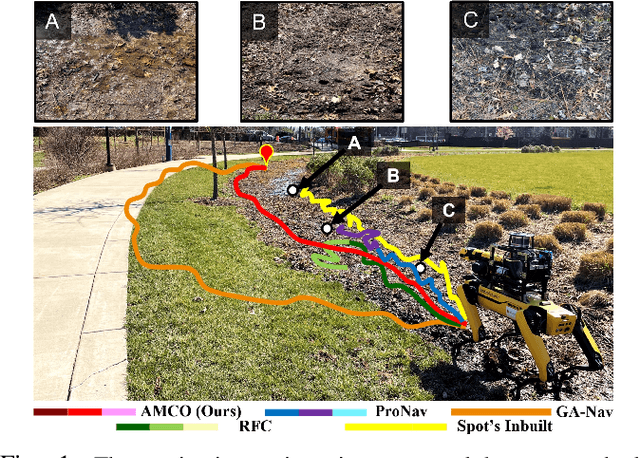
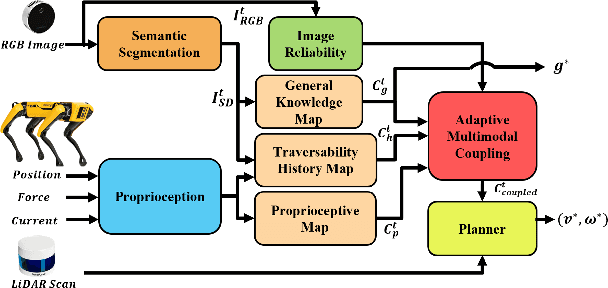

We present AMCO, a novel navigation method for quadruped robots that adaptively combines vision-based and proprioception-based perception capabilities. Our approach uses three cost maps: general knowledge map; traversability history map; and current proprioception map; which are derived from a robot's vision and proprioception data, and couples them to obtain a coupled traversability cost map for navigation. The general knowledge map encodes terrains semantically segmented from visual sensing, and represents a terrain's typically expected traversability. The traversability history map encodes the robot's recent proprioceptive measurements on a terrain and its semantic segmentation as a cost map. Further, the robot's present proprioceptive measurement is encoded as a cost map in the current proprioception map. As the general knowledge map and traversability history map rely on semantic segmentation, we evaluate the reliability of the visual sensory data by estimating the brightness and motion blur of input RGB images and accordingly combine the three cost maps to obtain the coupled traversability cost map used for navigation. Leveraging this adaptive coupling, the robot can depend on the most reliable input modality available. Finally, we present a novel planner that selects appropriate gaits and velocities for traversing challenging outdoor environments using the coupled traversability cost map. We demonstrate AMCO's navigation performance in different real-world outdoor environments and observe 10.8%-34.9% reduction w.r.t. two stability metrics, and up to 50% improvement in terms of success rate compared to current navigation methods.
AdVENTR: Autonomous Robot Navigation in Complex Outdoor Environments
Nov 15, 2023We present a novel system, AdVENTR for autonomous robot navigation in unstructured outdoor environments that consist of uneven and vegetated terrains. Our approach is general and can enable both wheeled and legged robots to handle outdoor terrain complexity including unevenness, surface properties like poor traction, granularity, obstacle stiffness, etc. We use data from sensors including RGB cameras, 3D Lidar, IMU, robot odometry, and pose information with efficient learning-based perception and planning algorithms that can execute on edge computing hardware. Our system uses a scene-aware switching method to perceive the environment for navigation at any time instant and dynamically switches between multiple perception algorithms. We test our system in a variety of sloped, rocky, muddy, and densely vegetated terrains and demonstrate its performance on Husky and Spot robots.
Using Lidar Intensity for Robot Navigation
Sep 28, 2023We present Multi-Layer Intensity Map, a novel 3D object representation for robot perception and autonomous navigation. Intensity maps consist of multiple stacked layers of 2D grid maps each derived from reflected point cloud intensities corresponding to a certain height interval. The different layers of intensity maps can be used to simultaneously estimate obstacles' height, solidity/density, and opacity. We demonstrate that intensity maps' can help accurately differentiate obstacles that are safe to navigate through (e.g. beaded/string curtains, pliable tall grass), from ones that must be avoided (e.g. transparent surfaces such as glass walls, bushes, trees, etc.) in indoor and outdoor environments. Further, to handle narrow passages, and navigate through non-solid obstacles in dense environments, we propose an approach to adaptively inflate or enlarge the obstacles detected on intensity maps based on their solidity, and the robot's preferred velocity direction. We demonstrate these improved navigation capabilities in real-world narrow, dense environments using a real Turtlebot and Boston Dynamics Spot robots. We observe significant increases in success rates to more than 50%, up to a 9.5% decrease in normalized trajectory length, and up to a 22.6% increase in the F-score compared to current navigation methods using other sensor modalities.
MTG: Mapless Trajectory Generator with Traversability Coverage for Outdoor Navigation
Sep 27, 2023



We present a novel learning-based trajectory generation algorithm for outdoor robot navigation. Our goal is to compute collision-free paths that also satisfy the environment-specific traversability constraints. Our approach is designed for global planning using limited onboard robot perception in mapless environments, while ensuring comprehensive coverage of all traversable directions. Our formulation uses a Conditional Variational Autoencoder (CVAE) generative model that is enhanced with traversability constraints and an optimization formulation used for the coverage. We highlight the benefits of our approach over state-of-the-art trajectory generation approaches and demonstrate its performance in challenging and large outdoor environments, including around buildings, across intersections, along trails, and off-road terrain, using a Clearpath Husky and a Boston Dynamics Spot robot. In practice, our approach results in a 6% improvement in coverage of traversable areas and an 89% reduction in trajectory portions residing in non-traversable regions. Our video is here: https: //youtu.be/OT0q4ccGHts
VAPOR: Legged Robot Navigation in Outdoor Vegetation Using Offline Reinforcement Learning
Sep 19, 2023We present VAPOR, a novel method for autonomous legged robot navigation in unstructured, densely vegetated outdoor environments using offline Reinforcement Learning (RL). Our method trains a novel RL policy using an actor-critic network and arbitrary data collected in real outdoor vegetation. Our policy uses height and intensity-based cost maps derived from 3D LiDAR point clouds, a goal cost map, and processed proprioception data as state inputs, and learns the physical and geometric properties of the surrounding obstacles such as height, density, and solidity/stiffness. The fully-trained policy's critic network is then used to evaluate the quality of dynamically feasible velocities generated from a novel context-aware planner. Our planner adapts the robot's velocity space based on the presence of entrapment inducing vegetation, and narrow passages in dense environments. We demonstrate our method's capabilities on a Spot robot in complex real-world outdoor scenes, including dense vegetation. We observe that VAPOR's actions improve success rates by up to 40%, decrease the average current consumption by up to 2.9%, and decrease the normalized trajectory length by up to 11.2% compared to existing end-to-end offline RL and other outdoor navigation methods.
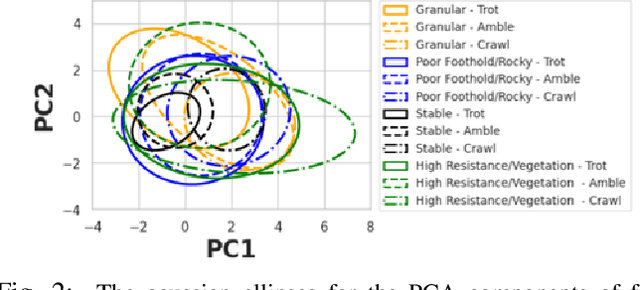
ProNav: Proprioceptive Traversability Estimation for Legged Robot Navigation in Outdoor Environments
Jul 26, 2023We propose a novel method, ProNav, which uses proprioceptive signals for traversability estimation in challenging outdoor terrains for autonomous legged robot navigation. Our approach uses sensor data from a legged robot's joint encoders, force, and current sensors to measure the joint positions, forces, and current consumption respectively to accurately assess a terrain's stability, resistance to the robot's motion, risk of entrapment, and crash. Based on these factors, we compute the appropriate robot trajectories and gait to maximize stability and minimize energy consumption. Our approach can also be used to predict imminent crashes in challenging terrains and execute behaviors to preemptively avoid them. We integrate ProNav with a vision-based method to navigate dense vegetation and demonstrate our method's benefits in real-world terrains with dense bushes, high granularity, negative obstacles, etc. Our method shows an improvement up to 50% in terms of success rate and up to 22.5% reduction in terms of energy consumption compared to exteroceptive based methods.
CrossLoc3D: Aerial-Ground Cross-Source 3D Place Recognition
Mar 31, 2023We present CrossLoc3D, a novel 3D place recognition method that solves a large-scale point matching problem in a cross-source setting. Cross-source point cloud data corresponds to point sets captured by depth sensors with different accuracies or from different distances and perspectives. We address the challenges in terms of developing 3D place recognition methods that account for the representation gap between points captured by different sources. Our method handles cross-source data by utilizing multi-grained features and selecting convolution kernel sizes that correspond to most prominent features. Inspired by the diffusion models, our method uses a novel iterative refinement process that gradually shifts the embedding spaces from different sources to a single canonical space for better metric learning. In addition, we present CS-Campus3D, the first 3D aerial-ground cross-source dataset consisting of point cloud data from both aerial and ground LiDAR scans. The point clouds in CS-Campus3D have representation gaps and other features like different views, point densities, and noise patterns. We show that our CrossLoc3D algorithm can achieve an improvement of 4.74% - 15.37% in terms of the top 1 average recall on our CS-Campus3D benchmark and achieves performance comparable to state-of-the-art 3D place recognition method on the Oxford RobotCar. We will release the code and CS-Campus3D benchmark.
VERN: Vegetation-aware Robot Navigation in Dense Unstructured Outdoor Environments
Mar 25, 2023We propose a novel method for autonomous legged robot navigation in densely vegetated environments with a variety of pliable/traversable and non-pliable/untraversable vegetation. We present a novel few-shot learning classifier that can be trained on a few hundred RGB images to differentiate flora that can be navigated through, from the ones that must be circumvented. Using the vegetation classification and 2D lidar scans, our method constructs a vegetation-aware traversability cost map that accurately represents the pliable and non-pliable obstacles with lower, and higher traversability costs, respectively. Our cost map construction accounts for misclassifications of the vegetation and further lowers the risk of collisions, freezing and entrapment in vegetation during navigation. Furthermore, we propose holonomic recovery behaviors for the robot for scenarios where it freezes, or gets physically entrapped in dense, pliable vegetation. We demonstrate our method on a Boston Dynamics Spot robot in real-world unstructured environments with sparse and dense tall grass, bushes, trees, etc. We observe an increase of 25-90% in success rates, 10-90% decrease in freezing rate, and up to 65% decrease in the false positive rate compared to existing methods.