 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHOP: Counterfactual Human Preference Labels Improve Obstacle Avoidance in Visuomotor Navigation Policies
Mar 02, 2026Visuomotor navigation policies have shown strong perception-action coupling for embodied agents, yet they often struggle with safe navigation and dynamic obstacle avoidance in complex real-world environments. We introduce CHOP, a novel approach that leverages Counterfactual Human Preference Labels to align visuomotor navigation policies towards human intuition of safety and obstacle avoidance in navigation. In CHOP, for each visual observation, the robot's executed trajectory is included among a set of counterfactual navigation trajectories: alternative trajectories the robot could have followed under identical conditions. Human annotators provide pairwise preference labels over these trajectories based on anticipated outcomes such as collision risk and path efficiency. These aggregated preferences are then used to fine-tune visuomotor navigation policies, aligning their behavior with human preferences in navigation. Experiments on the SCAND dataset show that visuomotor navigation policies fine-tuned with CHOP reduce near-collision events by 49.7%, decrease deviation from human-preferred trajectories by 45.0%, and increase average obstacle clearance by 19.8% on average across multiple state-of-the-art models, compared to their pretrained baselines. These improvements transfer to real-world deployments on a Ghost Robotics Vision60 quadruped, where CHOP-aligned policies improve average goal success rates by 24.4%, increase minimum obstacle clearance by 6.8%, reduce collision and intervention events by 45.7%, and improve normalized path completion by 38.6% on average across navigation scenarios, compared to their pretrained baselines. Our results highlight the value of counterfactual preference supervision in bridging the gap between large-scale visuomotor policies and human-aligned, safety-aware embodied navigation.
Vi-LAD: Vision-Language Attention Distillation for Socially-Aware Robot Navigation in Dynamic Environments
Mar 12, 2025We introduce Vision-Language Attention Distillation (Vi-LAD), a novel approach for distilling socially compliant navigation knowledge from a large Vision-Language Model (VLM) into a lightweight transformer model for real-time robotic navigation. Unlike traditional methods that rely on expert demonstrations or human-annotated datasets, Vi-LAD performs knowledge distillation and fine-tuning at the intermediate layer representation level (i.e., attention maps) by leveraging the backbone of a pre-trained vision-action model. These attention maps highlight key navigational regions in a given scene, which serve as implicit guidance for socially aware motion planning. Vi-LAD fine-tunes a transformer-based model using intermediate attention maps extracted from the pre-trained vision-action model, combined with attention-like semantic maps constructed from a large VLM. To achieve this, we introduce a novel attention-level distillation loss that fuses knowledge from both sources, generating augmented attention maps with enhanced social awareness. These refined attention maps are then utilized as a traversability costmap within a socially aware model predictive controller (MPC) for navigation. We validate our approach through real-world experiments on a Husky wheeled robot, demonstrating significant improvements over state-of-the-art (SOTA) navigation methods. Our results show up to 14.2% - 50% improvement in success rate, which highlights the effectiveness of Vi-LAD in enabling socially compliant and efficient robot navigation.
Robot Navigation Using Physically Grounded Vision-Language Models in Outdoor Environments
Sep 30, 2024



We present a novel autonomous robot navigation algorithm for outdoor environments that is capable of handling diverse terrain traversability conditions. Our approach, VLM-GroNav, uses vision-language models (VLMs) and integrates them with physical grounding that is used to assess intrinsic terrain properties such as deformability and slipperiness. We use proprioceptive-based sensing, which provides direct measurements of these physical properties, and enhances the overall semantic understanding of the terrains. Our formulation uses in-context learning to ground the VLM's semantic understanding with proprioceptive data to allow dynamic updates of traversability estimates based on the robot's real-time physical interactions with the environment. We use the updated traversability estimations to inform both the local and global planners for real-time trajectory replanning. We validate our method on a legged robot (Ghost Vision 60) and a wheeled robot (Clearpath Husky), in diverse real-world outdoor environments with different deformable and slippery terrains. In practice, we observe significant improvements over state-of-the-art methods by up to 50% increase in navigation success rate.
CROSS-GAiT: Cross-Attention-Based Multimodal Representation Fusion for Parametric Gait Adaptation in Complex Terrains
Sep 25, 2024



We present CROSS-GAiT, a novel algorithm for quadruped robots that uses Cross Attention to fuse terrain representations derived from visual and time-series inputs, including linear accelerations, angular velocities, and joint efforts. These fused representations are used to adjust the robot's step height and hip splay, enabling adaptive gaits that respond dynamically to varying terrain conditions. We generate these terrain representations by processing visual inputs through a masked Vision Transformer (ViT) encoder and time-series data through a dilated causal convolutional encoder. The cross-attention mechanism then selects and integrates the most relevant features from each modality, combining terrain characteristics with robot dynamics for better-informed gait adjustments. CROSS-GAiT uses the combined representation to dynamically adjust gait parameters in response to varying and unpredictable terrains. We train CROSS-GAiT on data from diverse terrains, including asphalt, concrete, brick pavements, grass, dense vegetation, pebbles, gravel, and sand. Our algorithm generalizes well and adapts to unseen environmental conditions, enhancing real-time navigation performance. CROSS-GAiT was implemented on a Ghost Robotics Vision 60 robot and extensively tested in complex terrains with high vegetation density, uneven/unstable surfaces, sand banks, deformable substrates, etc. We observe at least a 7.04% reduction in IMU energy density and a 27.3% reduction in total joint effort, which directly correlates with increased stability and reduced energy usage when compared to state-of-the-art methods. Furthermore, CROSS-GAiT demonstrates at least a 64.5% increase in success rate and a 4.91% reduction in time to reach the goal in four complex scenarios. Additionally, the learned representations perform 4.48% better than the state-of-the-art on a terrain classification task.
BehAV: Behavioral Rule Guided Autonomy Using VLMs for Robot Navigation in Outdoor Scenes
Sep 24, 2024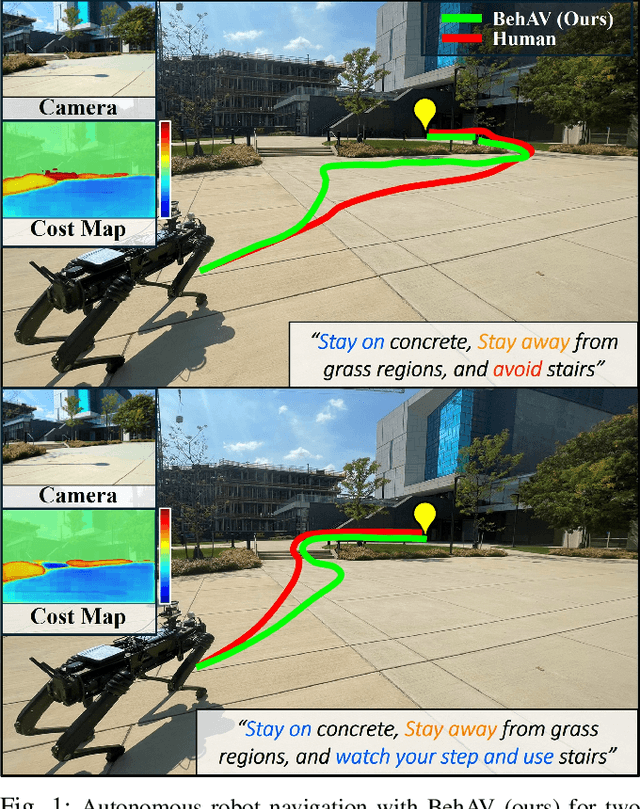
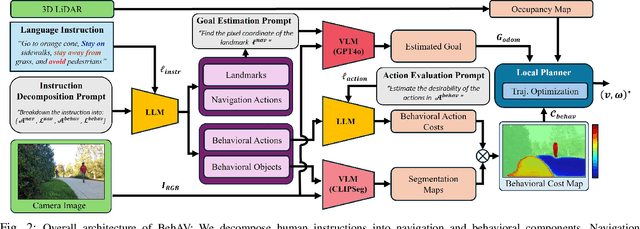

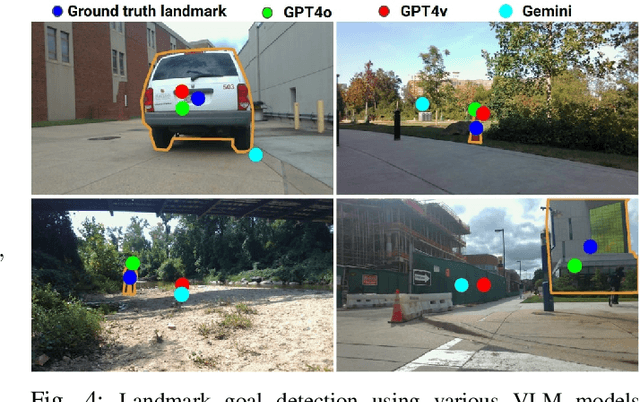
We present BehAV, a novel approach for autonomous robot navigation in outdoor scenes guided by human instructions and leveraging Vision Language Models (VLMs). Our method interprets human commands using a Large Language Model (LLM) and categorizes the instructions into navigation and behavioral guidelines. Navigation guidelines consist of directional commands (e.g., "move forward until") and associated landmarks (e.g., "the building with blue windows"), while behavioral guidelines encompass regulatory actions (e.g., "stay on") and their corresponding objects (e.g., "pavements"). We use VLMs for their zero-shot scene understanding capabilities to estimate landmark locations from RGB images for robot navigation. Further, we introduce a novel scene representation that utilizes VLMs to ground behavioral rules into a behavioral cost map. This cost map encodes the presence of behavioral objects within the scene and assigns costs based on their regulatory actions. The behavioral cost map is integrated with a LiDAR-based occupancy map for navigation. To navigate outdoor scenes while adhering to the instructed behaviors, we present an unconstrained Model Predictive Control (MPC)-based planner that prioritizes both reaching landmarks and following behavioral guidelines. We evaluate the performance of BehAV on a quadruped robot across diverse real-world scenarios, demonstrating a 22.49% improvement in alignment with human-teleoperated actions, as measured by Frechet distance, and achieving a 40% higher navigation success rate compared to state-of-the-art methods.
Anomaly Detection using Deep Reconstruction and Forecasting for Autonomous Systems
Jun 25, 2020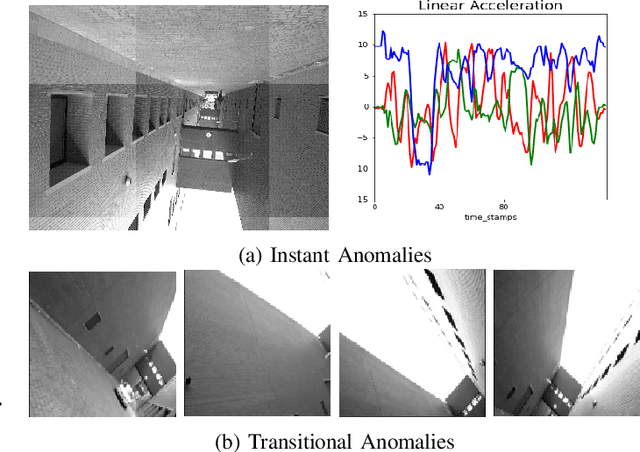

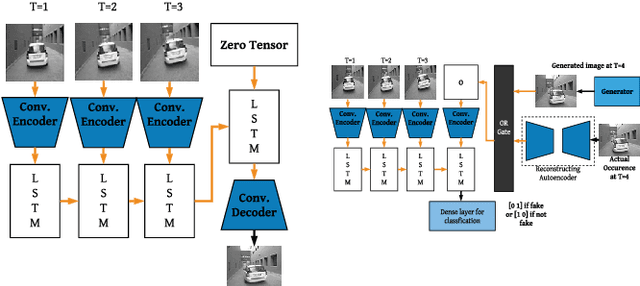

We propose self-supervised deep algorithms to detect anomalies in heterogeneous autonomous systems using frontal camera video and IMU readings. Given that the video and IMU data are not synchronized, each of them are analyzed separately. The vision-based system, which utilizes a conditional GAN, analyzes immediate-past three frames and attempts to predict the next frame. The frame is classified as either an anomalous case or a normal case based on the degree of difference estimated using the prediction error and a threshold. The IMU-based system utilizes two approaches to classify the timestamps; the first being an LSTM autoencoder which reconstructs three consecutive IMU vectors and the second being an LSTM forecaster which is utilized to predict the next vector using the previous three IMU vectors. Based on the reconstruction error, the prediction error, and a threshold, the timestamp is classified as either an anomalous case or a normal case. The composition of algorithms won runners up at the IEEE Signal Processing Cup anomaly detection challenge 2020. In the competition dataset of camera frames consisting of both normal and anomalous cases, we achieve a test accuracy of 94% and an F1-score of 0.95. Furthermore, we achieve an accuracy of 100% on a test set containing normal IMU data, and an F1-score of 0.98 on the test set of abnormal IMU data.