 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAVE: Diverse Atomic Visual Elements Dataset with High Representation of Vulnerable Road Users in Complex and Unpredictable Environments
Dec 28, 2024



Most existing traffic video datasets including Waymo are structured, focusing predominantly on Western traffic, which hinders global applicability. Specifically, most Asian scenarios are far more complex, involving numerous objects with distinct motions and behaviors. Addressing this gap, we present a new dataset, DAVE, designed for evaluating perception methods with high representation of Vulnerable Road Users (VRUs: e.g. pedestrians, animals, motorbikes, and bicycles) in complex and unpredictable environments. DAVE is a manually annotated dataset encompassing 16 diverse actor categories (spanning animals, humans, vehicles, etc.) and 16 action types (complex and rare cases like cut-ins, zigzag movement, U-turn, etc.), which require high reasoning ability. DAVE densely annotates over 13 million bounding boxes (bboxes) actors with identification, and more than 1.6 million boxes are annotated with both actor identification and action/behavior details. The videos within DAVE are collected based on a broad spectrum of factors, such as weather conditions, the time of day, road scenarios, and traffic density. DAVE can benchmark video tasks like Tracking, Detection, Spatiotemporal Action Localization, Language-Visual Moment retrieval, and Multi-label Video Action Recognition. Given the critical importance of accurately identifying VRUs to prevent accidents and ensure road safety, in DAVE, vulnerable road users constitute 41.13% of instances, compared to 23.71% in Waymo. DAVE provides an invaluable resource for the development of more sensitive and accurate visual perception algorithms in the complex real world. Our experiments show that existing methods suffer degradation in performance when evaluated on DAVE, highlighting its benefit for future video recognition research.
Robot Navigation Using Physically Grounded Vision-Language Models in Outdoor Environments
Sep 30, 2024



We present a novel autonomous robot navigation algorithm for outdoor environments that is capable of handling diverse terrain traversability conditions. Our approach, VLM-GroNav, uses vision-language models (VLMs) and integrates them with physical grounding that is used to assess intrinsic terrain properties such as deformability and slipperiness. We use proprioceptive-based sensing, which provides direct measurements of these physical properties, and enhances the overall semantic understanding of the terrains. Our formulation uses in-context learning to ground the VLM's semantic understanding with proprioceptive data to allow dynamic updates of traversability estimates based on the robot's real-time physical interactions with the environment. We use the updated traversability estimations to inform both the local and global planners for real-time trajectory replanning. We validate our method on a legged robot (Ghost Vision 60) and a wheeled robot (Clearpath Husky), in diverse real-world outdoor environments with different deformable and slippery terrains. In practice, we observe significant improvements over state-of-the-art methods by up to 50% increase in navigation success rate.
SOAR: Self-supervision Optimized UAV Action Recognition with Efficient Object-Aware Pretraining
Sep 26, 2024
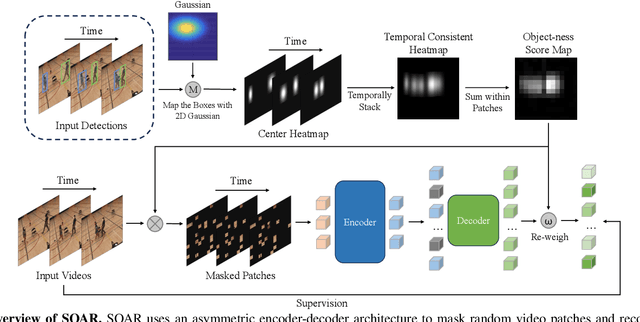
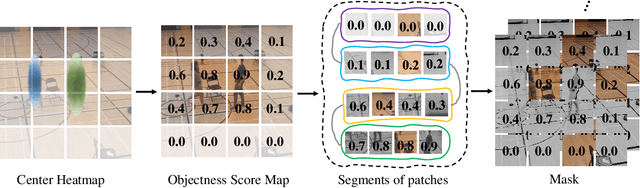
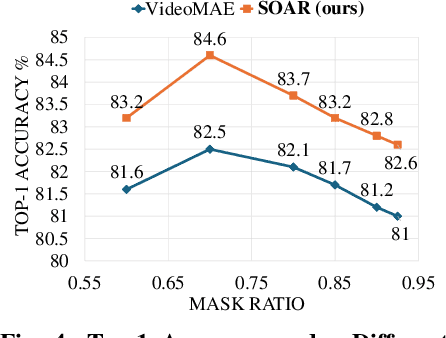
We introduce SOAR, a novel Self-supervised pretraining algorithm for aerial footage captured by Unmanned Aerial Vehicles (UAVs). We incorporate human object knowledge throughout the pretraining process to enhance UAV video pretraining efficiency and downstream action recognition performance. This is in contrast to prior works that primarily incorporate object information during the fine-tuning stage. Specifically, we first propose a novel object-aware masking strategy designed to retain the visibility of certain patches related to objects throughout the pretraining phase. Second, we introduce an object-aware loss function that utilizes object information to adjust the reconstruction loss, preventing bias towards less informative background patches. In practice, SOAR with a vanilla ViT backbone, outperforms best UAV action recognition models, recording a 9.7% and 21.4% boost in top-1 accuracy on the NEC-Drone and UAV-Human datasets, while delivering an inference speed of 18.7ms per video, making it 2x to 5x faster. Additionally, SOAR obtains comparable accuracy to prior self-supervised learning (SSL) methods while requiring 87.5% less pretraining time and 25% less memory usage
AUTOHALLUSION: Automatic Generation of Hallucination Benchmarks for Vision-Language Models
Jun 16, 2024



Large vision-language models (LVLMs) hallucinate: certain context cues in an image may trigger the language module's overconfident and incorrect reasoning on abnormal or hypothetical objects. Though a few benchmarks have been developed to investigate LVLM hallucinations, they mainly rely on hand-crafted corner cases whose fail patterns may hardly generalize, and finetuning on them could undermine their validity. These motivate us to develop the first automatic benchmark generation approach, AUTOHALLUSION, that harnesses a few principal strategies to create diverse hallucination examples. It probes the language modules in LVLMs for context cues and uses them to synthesize images by: (1) adding objects abnormal to the context cues; (2) for two co-occurring objects, keeping one and excluding the other; or (3) removing objects closely tied to the context cues. It then generates image-based questions whose ground-truth answers contradict the language module's prior. A model has to overcome contextual biases and distractions to reach correct answers, while incorrect or inconsistent answers indicate hallucinations. AUTOHALLUSION enables us to create new benchmarks at the minimum cost and thus overcomes the fragility of hand-crafted benchmarks. It also reveals common failure patterns and reasons, providing key insights to detect, avoid, or control hallucinations. Comprehensive evaluations of top-tier LVLMs, e.g., GPT-4V(ision), Gemini Pro Vision, Claude 3, and LLaVA-1.5, show a 97.7% and 98.7% success rate of hallucination induction on synthetic and real-world datasets of AUTOHALLUSION, paving the way for a long battle against hallucinations.
AGL-NET: Aerial-Ground Cross-Modal Global Localization with Varying Scales
Apr 04, 2024



We present AGL-NET, a novel learning-based method for global localization using LiDAR point clouds and satellite maps. AGL-NET tackles two critical challenges: bridging the representation gap between image and points modalities for robust feature matching, and handling inherent scale discrepancies between global view and local view. To address these challenges, AGL-NET leverages a unified network architecture with a novel two-stage matching design. The first stage extracts informative neural features directly from raw sensor data and performs initial feature matching. The second stage refines this matching process by extracting informative skeleton features and incorporating a novel scale alignment step to rectify scale variations between LiDAR and map data. Furthermore, a novel scale and skeleton loss function guides the network toward learning scale-invariant feature representations, eliminating the need for pre-processing satellite maps. This significantly improves real-world applicability in scenarios with unknown map scales. To facilitate rigorous performance evaluation, we introduce a meticulously designed dataset within the CARLA simulator specifically tailored for metric localization training and assessment. The code and dataset will be made publicly available.
On the Safety Concerns of Deploying LLMs/VLMs in Robotics: Highlighting the Risks and Vulnerabilities
Feb 24, 2024



In this paper, we highlight the critical issues of robustness and safety associated with integrating large language models (LLMs) and vision-language models (VLMs) into robotics applications. Recent works have focused on using LLMs and VLMs to improve the performance of robotics tasks, such as manipulation, navigation, etc. However, such integration can introduce significant vulnerabilities, in terms of their susceptibility to adversarial attacks due to the language models, potentially leading to catastrophic consequences. By examining recent works at the interface of LLMs/VLMs and robotics, we show that it is easy to manipulate or misguide the robot's actions, leading to safety hazards. We define and provide examples of several plausible adversarial attacks, and conduct experiments on three prominent robot frameworks integrated with a language model, including KnowNo VIMA, and Instruct2Act, to assess their susceptibility to these attacks. Our empirical findings reveal a striking vulnerability of LLM/VLM-robot integrated systems: simple adversarial attacks can significantly undermine the effectiveness of LLM/VLM-robot integrated systems. Specifically, our data demonstrate an average performance deterioration of 21.2% under prompt attacks and a more alarming 30.2% under perception attacks. These results underscore the critical need for robust countermeasures to ensure the safe and reliable deployment of the advanced LLM/VLM-based robotic systems.
Prompt Learning for Action Recognition
May 21, 2023



We present a new general learning approach for action recognition, Prompt Learning for Action Recognition (PLAR), which leverages the strengths of prompt learning to guide the learning process. Our approach is designed to predict the action label by helping the models focus on the descriptions or instructions associated with actions in the input videos. Our formulation uses various prompts, including optical flow, large vision models, and learnable prompts to improve the recognition performance. Moreover, we propose a learnable prompt method that learns to dynamically generate prompts from a pool of prompt experts under different inputs. By sharing the same objective, our proposed PLAR can optimize prompts that guide the model's predictions while explicitly learning input-invariant (prompt experts pool) and input-specific (data-dependent) prompt knowledge. We evaluate our approach on datasets consisting of both ground camera videos and aerial videos, and scenes with single-agent and multi-agent actions. In practice, we observe a 3.17-10.2% accuracy improvement on the aerial multi-agent dataset, Okutamam and 0.8-2.6% improvement on the ground camera single-agent dataset, Something Something V2. We plan to release our code on the WWW.
PMI Sampler: Patch similarity guided frame selection for Aerial Action Recognition
Apr 14, 2023



We present a new algorithm for selection of informative frames in video action recognition. Our approach is designed for aerial videos captured using a moving camera where human actors occupy a small spatial resolution of video frames. Our algorithm utilizes the motion bias within aerial videos, which enables the selection of motion-salient frames. We introduce the concept of patch mutual information (PMI) score to quantify the motion bias between adjacent frames, by measuring the similarity of patches. We use this score to assess the amount of discriminative motion information contained in one frame relative to another. We present an adaptive frame selection strategy using shifted leaky ReLu and cumulative distribution function, which ensures that the sampled frames comprehensively cover all the essential segments with high motion salience. Our approach can be integrated with any action recognition model to enhance its accuracy. In practice, our method achieves a relative improvement of 2.2 - 13.8% in top-1 accuracy on UAV-Human, 6.8% on NEC Drone, and 9.0% on Diving48 datasets.
MITFAS: Mutual Information based Temporal Feature Alignment and Sampling for Aerial Video Action Recognition
Mar 05, 2023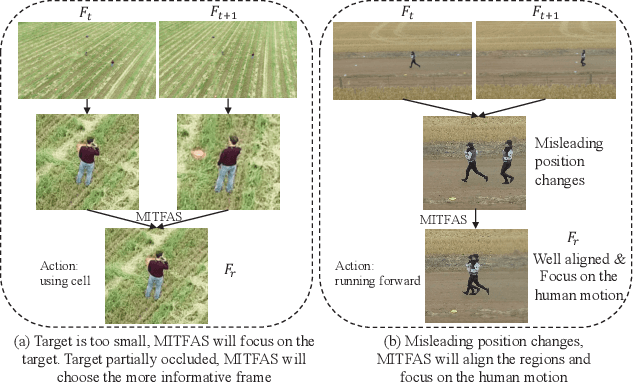



We present a novel approach for action recognition in UAV videos. Our formulation is designed to handle occlusion and viewpoint changes caused by the movement of a UAV. We use the concept of mutual information to compute and align the regions corresponding to human action or motion in the temporal domain. This enables our recognition model to learn from the key features associated with the motion. We also propose a novel frame sampling method that uses joint mutual information to acquire the most informative frame sequence in UAV videos. We have integrated our approach with X3D and evaluated the performance on multiple datasets. In practice, we achieve 18.9% improvement in Top-1 accuracy over current state-of-the-art methods on UAV-Human(Li et al., 2021), 7.3% improvement on Drone-Action(Perera et al., 2019), and 7.16% improvement on NEC Drones(Choi et al., 2020). We will release the code at the time of publication
AZTR: Aerial Video Action Recognition with Auto Zoom and Temporal Reasoning
Mar 02, 2023We propose a novel approach for aerial video action recognition. Our method is designed for videos captured using UAVs and can run on edge or mobile devices. We present a learning-based approach that uses customized auto zoom to automatically identify the human target and scale it appropriately. This makes it easier to extract the key features and reduces the computational overhead. We also present an efficient temporal reasoning algorithm to capture the action information along the spatial and temporal domains within a controllable computational cost. Our approach has been implemented and evaluated both on the desktop with high-end GPUs and on the low power Robotics RB5 Platform for robots and drones. In practice, we achieve 6.1-7.4% improvement over SOTA in Top-1 accuracy on the RoCoG-v2 dataset, 8.3-10.4% improvement on the UAV-Human dataset and 3.2% improvement on the Drone Action dataset.