 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTREND: Tri-teaching for Robust Preference-based Reinforcement Learning with Demonstrations
May 09, 2025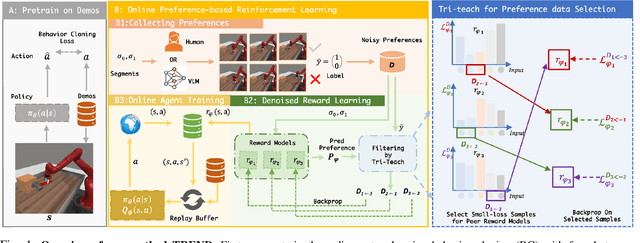
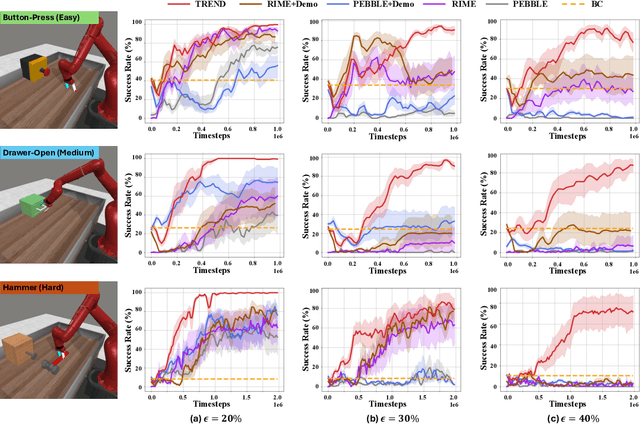
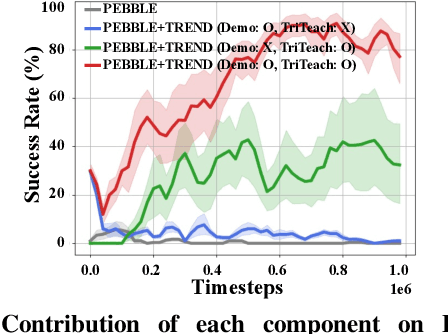
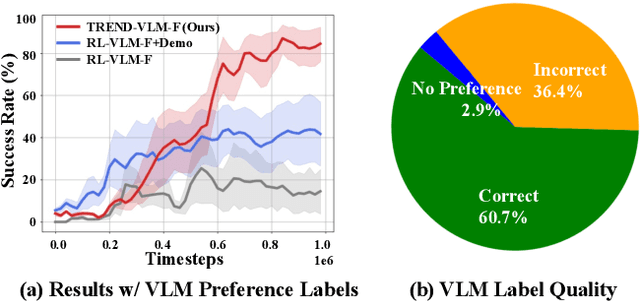
Preference feedback collected by human or VLM annotators is often noisy, presenting a significant challenge for preference-based reinforcement learning that relies on accurate preference labels. To address this challenge, we propose TREND, a novel framework that integrates few-shot expert demonstrations with a tri-teaching strategy for effective noise mitigation. Our method trains three reward models simultaneously, where each model views its small-loss preference pairs as useful knowledge and teaches such useful pairs to its peer network for updating the parameters. Remarkably, our approach requires as few as one to three expert demonstrations to achieve high performance. We evaluate TREND on various robotic manipulation tasks, achieving up to 90% success rates even with noise levels as high as 40%, highlighting its effective robustness in handling noisy preference feedback. Project page: https://shuaiyihuang.github.io/publications/TREND.
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
Dec 13, 2024Although large vision-language-action (VLA) models pretrained on extensive robot datasets offer promising generalist policies for robotic learning, they still struggle with spatial-temporal dynamics in interactive robotics, making them less effective in handling complex tasks, such as manipulation. In this work, we introduce visual trace prompting, a simple yet effective approach to facilitate VLA models' spatial-temporal awareness for action prediction by encoding state-action trajectories visually. We develop a new TraceVLA model by finetuning OpenVLA on our own collected dataset of 150K robot manipulation trajectories using visual trace prompting. Evaluations of TraceVLA across 137 configurations in SimplerEnv and 4 tasks on a physical WidowX robot demonstrate state-of-the-art performance, outperforming OpenVLA by 10% on SimplerEnv and 3.5x on real-robot tasks and exhibiting robust generalization across diverse embodiments and scenarios. To further validate the effectiveness and generality of our method, we present a compact VLA model based on 4B Phi-3-Vision, pretrained on the Open-X-Embodiment and finetuned on our dataset, rivals the 7B OpenVLA baseline while significantly improving inference efficiency.
ARDuP: Active Region Video Diffusion for Universal Policies
Jun 19, 2024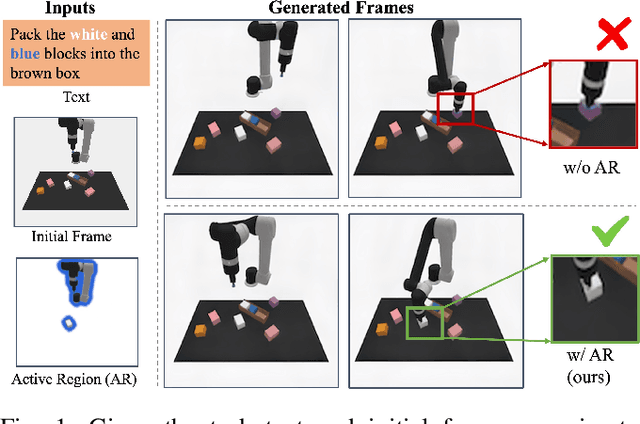
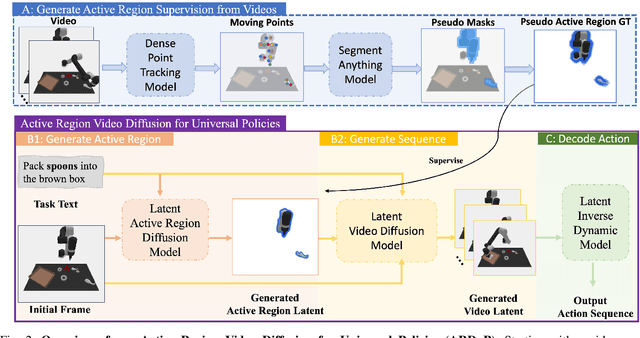
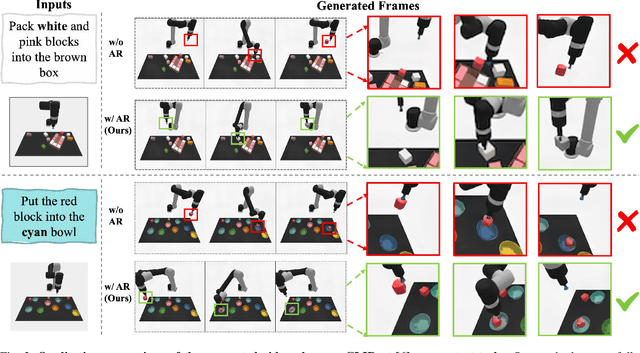
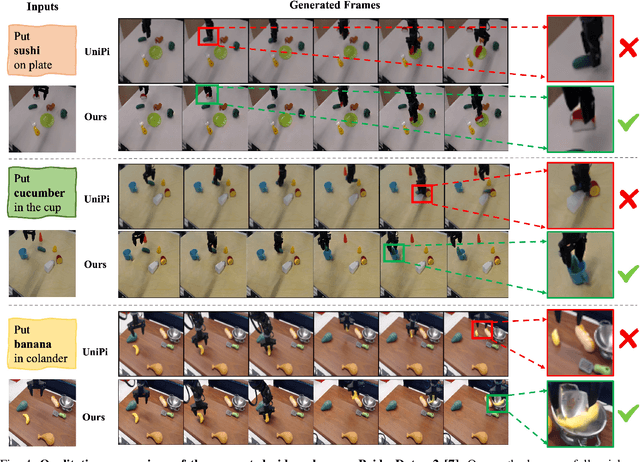
Sequential decision-making can be formulated as a text-conditioned video generation problem, where a video planner, guided by a text-defined goal, generates future frames visualizing planned actions, from which control actions are subsequently derived. In this work, we introduce Active Region Video Diffusion for Universal Policies (ARDuP), a novel framework for video-based policy learning that emphasizes the generation of active regions, i.e. potential interaction areas, enhancing the conditional policy's focus on interactive areas critical for task execution. This innovative framework integrates active region conditioning with latent diffusion models for video planning and employs latent representations for direct action decoding during inverse dynamic modeling. By utilizing motion cues in videos for automatic active region discovery, our method eliminates the need for manual annotations of active regions. We validate ARDuP's efficacy via extensive experiments on simulator CLIPort and the real-world dataset BridgeData v2, achieving notable improvements in success rates and generating convincingly realistic video plans.
AUTOHALLUSION: Automatic Generation of Hallucination Benchmarks for Vision-Language Models
Jun 16, 2024



Large vision-language models (LVLMs) hallucinate: certain context cues in an image may trigger the language module's overconfident and incorrect reasoning on abnormal or hypothetical objects. Though a few benchmarks have been developed to investigate LVLM hallucinations, they mainly rely on hand-crafted corner cases whose fail patterns may hardly generalize, and finetuning on them could undermine their validity. These motivate us to develop the first automatic benchmark generation approach, AUTOHALLUSION, that harnesses a few principal strategies to create diverse hallucination examples. It probes the language modules in LVLMs for context cues and uses them to synthesize images by: (1) adding objects abnormal to the context cues; (2) for two co-occurring objects, keeping one and excluding the other; or (3) removing objects closely tied to the context cues. It then generates image-based questions whose ground-truth answers contradict the language module's prior. A model has to overcome contextual biases and distractions to reach correct answers, while incorrect or inconsistent answers indicate hallucinations. AUTOHALLUSION enables us to create new benchmarks at the minimum cost and thus overcomes the fragility of hand-crafted benchmarks. It also reveals common failure patterns and reasons, providing key insights to detect, avoid, or control hallucinations. Comprehensive evaluations of top-tier LVLMs, e.g., GPT-4V(ision), Gemini Pro Vision, Claude 3, and LLaVA-1.5, show a 97.7% and 98.7% success rate of hallucination induction on synthetic and real-world datasets of AUTOHALLUSION, paving the way for a long battle against hallucinations.
UVIS: Unsupervised Video Instance Segmentation
Jun 11, 2024



Video instance segmentation requires classifying, segmenting, and tracking every object across video frames. Unlike existing approaches that rely on masks, boxes, or category labels, we propose UVIS, a novel Unsupervised Video Instance Segmentation (UVIS) framework that can perform video instance segmentation without any video annotations or dense label-based pretraining. Our key insight comes from leveraging the dense shape prior from the self-supervised vision foundation model DINO and the openset recognition ability from the image-caption supervised vision-language model CLIP. Our UVIS framework consists of three essential steps: frame-level pseudo-label generation, transformer-based VIS model training, and query-based tracking. To improve the quality of VIS predictions in the unsupervised setup, we introduce a dual-memory design. This design includes a semantic memory bank for generating accurate pseudo-labels and a tracking memory bank for maintaining temporal consistency in object tracks. We evaluate our approach on three standard VIS benchmarks, namely YoutubeVIS-2019, YoutubeVIS-2021, and Occluded VIS. Our UVIS achieves 21.1 AP on YoutubeVIS-2019 without any video annotations or dense pretraining, demonstrating the potential of our unsupervised VIS framework.
What is Point Supervision Worth in Video Instance Segmentation?
Apr 01, 2024



Video instance segmentation (VIS) is a challenging vision task that aims to detect, segment, and track objects in videos. Conventional VIS methods rely on densely-annotated object masks which are expensive. We reduce the human annotations to only one point for each object in a video frame during training, and obtain high-quality mask predictions close to fully supervised models. Our proposed training method consists of a class-agnostic proposal generation module to provide rich negative samples and a spatio-temporal point-based matcher to match the object queries with the provided point annotations. Comprehensive experiments on three VIS benchmarks demonstrate competitive performance of the proposed framework, nearly matching fully supervised methods.
Towards Scalable Neural Representation for Diverse Videos
Mar 24, 2023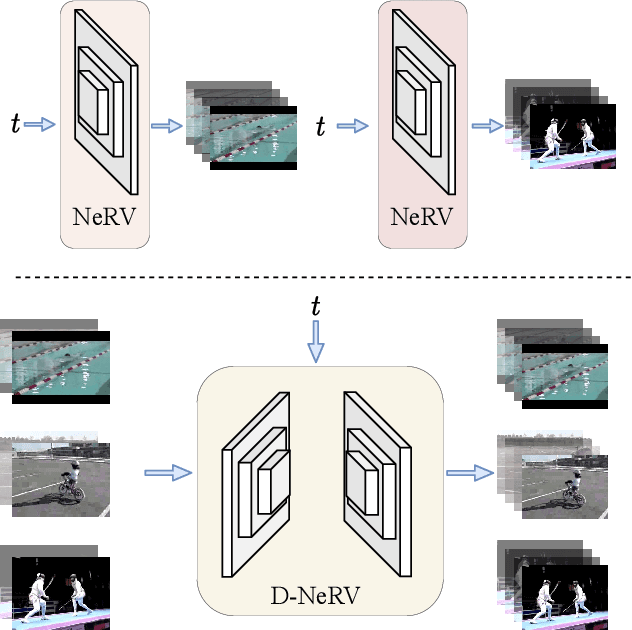
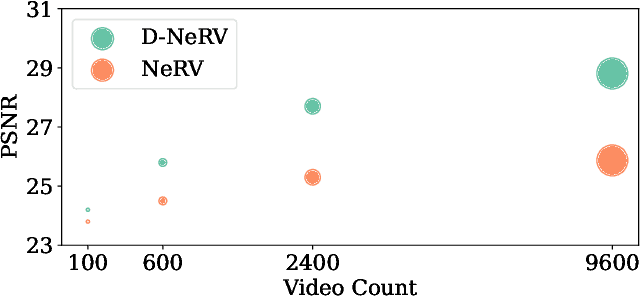
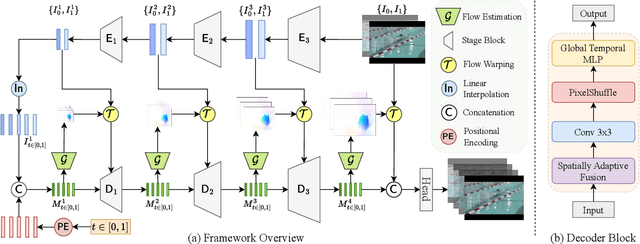
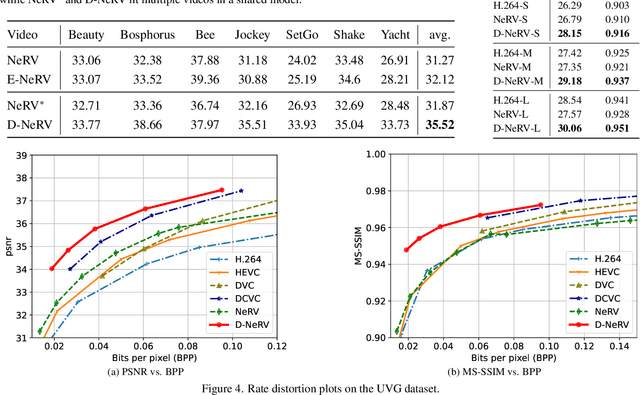
Implicit neural representations (INR) have gained increasing attention in representing 3D scenes and images, and have been recently applied to encode videos (e.g., NeRV, E-NeRV). While achieving promising results, existing INR-based methods are limited to encoding a handful of short videos (e.g., seven 5-second videos in the UVG dataset) with redundant visual content, leading to a model design that fits individual video frames independently and is not efficiently scalable to a large number of diverse videos. This paper focuses on developing neural representations for a more practical setup -- encoding long and/or a large number of videos with diverse visual content. We first show that instead of dividing videos into small subsets and encoding them with separate models, encoding long and diverse videos jointly with a unified model achieves better compression results. Based on this observation, we propose D-NeRV, a novel neural representation framework designed to encode diverse videos by (i) decoupling clip-specific visual content from motion information, (ii) introducing temporal reasoning into the implicit neural network, and (iii) employing the task-oriented flow as intermediate output to reduce spatial redundancies. Our new model largely surpasses NeRV and traditional video compression techniques on UCF101 and UVG datasets on the video compression task. Moreover, when used as an efficient data-loader, D-NeRV achieves 3%-10% higher accuracy than NeRV on action recognition tasks on the UCF101 dataset under the same compression ratios.
Learning Semantic Correspondence with Sparse Annotations
Aug 17, 2022
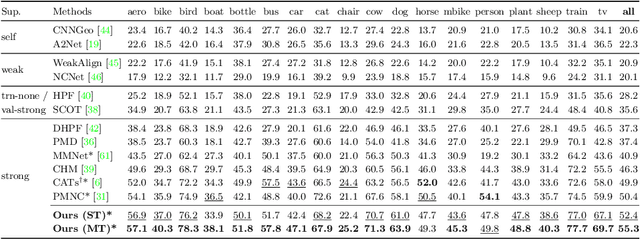
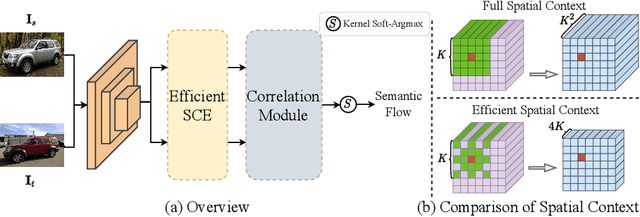
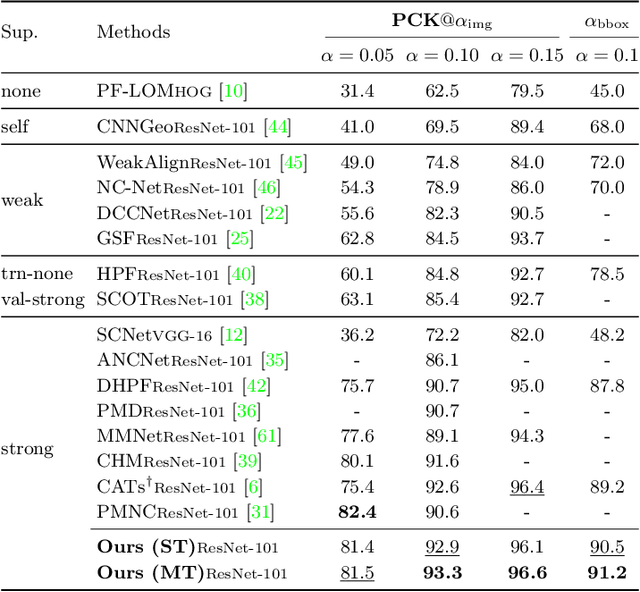
Finding dense semantic correspondence is a fundamental problem in computer vision, which remains challenging in complex scenes due to background clutter, extreme intra-class variation, and a severe lack of ground truth. In this paper, we aim to address the challenge of label sparsity in semantic correspondence by enriching supervision signals from sparse keypoint annotations. To this end, we first propose a teacher-student learning paradigm for generating dense pseudo-labels and then develop two novel strategies for denoising pseudo-labels. In particular, we use spatial priors around the sparse annotations to suppress the noisy pseudo-labels. In addition, we introduce a loss-driven dynamic label selection strategy for label denoising. We instantiate our paradigm with two variants of learning strategies: a single offline teacher setting, and mutual online teachers setting. Our approach achieves notable improvements on three challenging benchmarks for semantic correspondence and establishes the new state-of-the-art. Project page: https://shuaiyihuang.github.io/publications/SCorrSAN.
Investigating Information Inconsistency in Multilingual Open-Domain Question Answering
May 25, 2022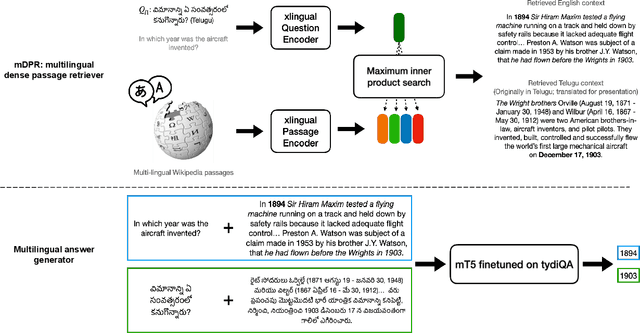

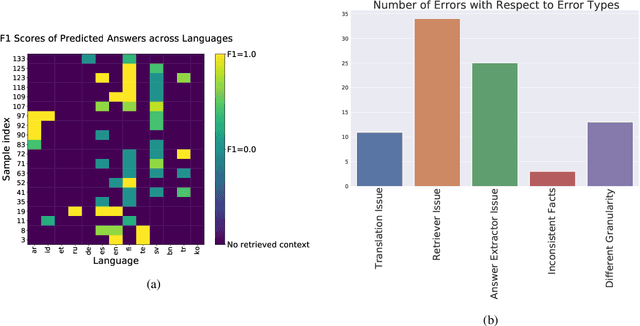
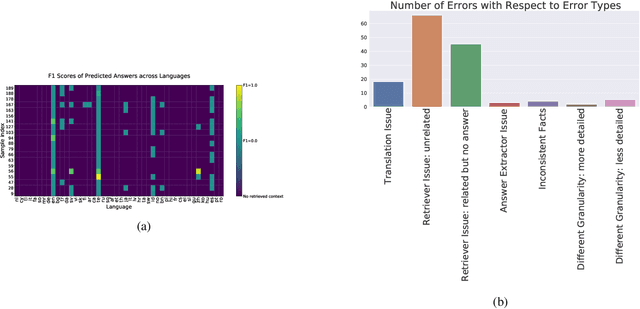
Retrieval based open-domain QA systems use retrieved documents and answer-span selection over retrieved documents to find best-answer candidates. We hypothesize that multilingual Question Answering (QA) systems are prone to information inconsistency when it comes to documents written in different languages, because these documents tend to provide a model with varying information about the same topic. To understand the effects of the biased availability of information and cultural influence, we analyze the behavior of multilingual open-domain question answering models with a focus on retrieval bias. We analyze if different retriever models present different passages given the same question in different languages on TyDi QA and XOR-TyDi QA, two multilingualQA datasets. We speculate that the content differences in documents across languages might reflect cultural divergences and/or social biases.
Confidence-aware Adversarial Learning for Self-supervised Semantic Matching
Aug 25, 2020
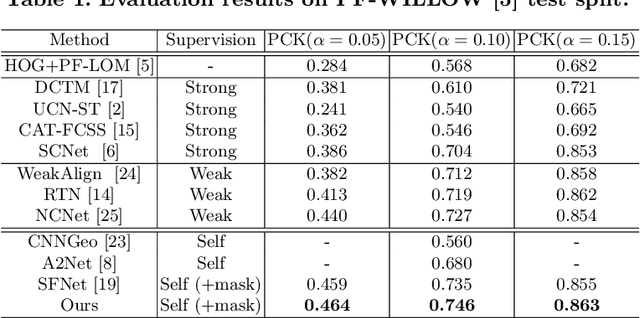
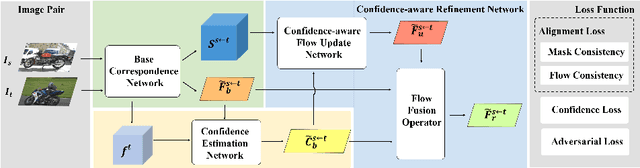
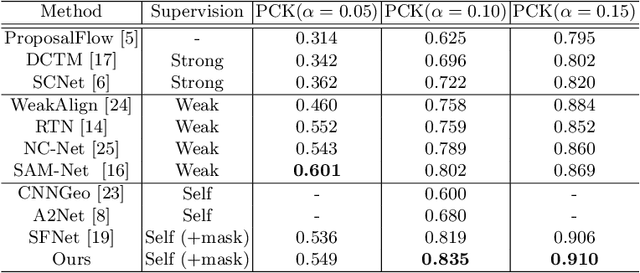
In this paper, we aim to address the challenging task of semantic matching where matching ambiguity is difficult to resolve even with learned deep features. We tackle this problem by taking into account the confidence in predictions and develop a novel refinement strategy to correct partial matching errors. Specifically, we introduce a Confidence-Aware Semantic Matching Network (CAMNet) which instantiates two key ideas of our approach. First, we propose to estimate a dense confidence map for a matching prediction through self-supervised learning. Second, based on the estimated confidence, we refine initial predictions by propagating reliable matching to the rest of locations on the image plane. In addition, we develop a new hybrid loss in which we integrate a semantic alignment loss with a confidence loss, and an adversarial loss that measures the quality of semantic correspondence. We are the first that exploit confidence during refinement to improve semantic matching accuracy and develop an end-to-end self-supervised adversarial learning procedure for the entire matching network. We evaluate our method on two public benchmarks, on which we achieve top performance over the prior state of the art. We will release our source code at https://github.com/ShuaiyiHuang/CAMNet.