 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUVIS: Unsupervised Video Instance Segmentation
Jun 11, 2024



Video instance segmentation requires classifying, segmenting, and tracking every object across video frames. Unlike existing approaches that rely on masks, boxes, or category labels, we propose UVIS, a novel Unsupervised Video Instance Segmentation (UVIS) framework that can perform video instance segmentation without any video annotations or dense label-based pretraining. Our key insight comes from leveraging the dense shape prior from the self-supervised vision foundation model DINO and the openset recognition ability from the image-caption supervised vision-language model CLIP. Our UVIS framework consists of three essential steps: frame-level pseudo-label generation, transformer-based VIS model training, and query-based tracking. To improve the quality of VIS predictions in the unsupervised setup, we introduce a dual-memory design. This design includes a semantic memory bank for generating accurate pseudo-labels and a tracking memory bank for maintaining temporal consistency in object tracks. We evaluate our approach on three standard VIS benchmarks, namely YoutubeVIS-2019, YoutubeVIS-2021, and Occluded VIS. Our UVIS achieves 21.1 AP on YoutubeVIS-2019 without any video annotations or dense pretraining, demonstrating the potential of our unsupervised VIS framework.
Distilling Vision-Language Pretraining for Efficient Cross-Modal Retrieval
May 23, 2024

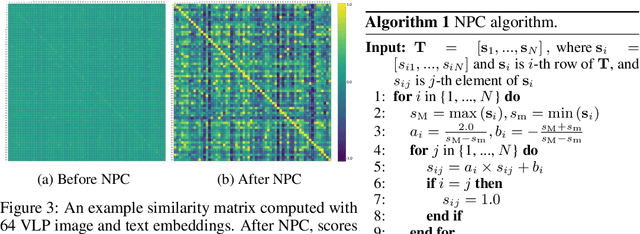
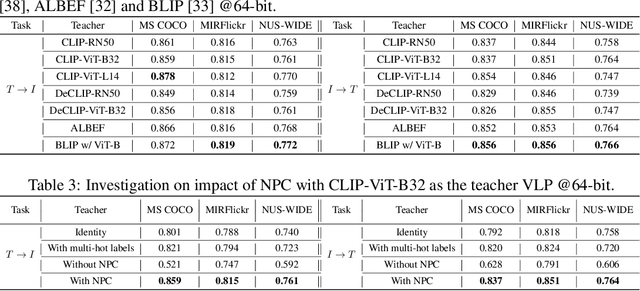
``Learning to hash'' is a practical solution for efficient retrieval, offering fast search speed and low storage cost. It is widely applied in various applications, such as image-text cross-modal search. In this paper, we explore the potential of enhancing the performance of learning to hash with the proliferation of powerful large pre-trained models, such as Vision-Language Pre-training (VLP) models. We introduce a novel method named Distillation for Cross-Modal Quantization (DCMQ), which leverages the rich semantic knowledge of VLP models to improve hash representation learning. Specifically, we use the VLP as a `teacher' to distill knowledge into a `student' hashing model equipped with codebooks. This process involves the replacement of supervised labels, which are composed of multi-hot vectors and lack semantics, with the rich semantics of VLP. In the end, we apply a transformation termed Normalization with Paired Consistency (NPC) to achieve a discriminative target for distillation. Further, we introduce a new quantization method, Product Quantization with Gumbel (PQG) that promotes balanced codebook learning, thereby improving the retrieval performance. Extensive benchmark testing demonstrates that DCMQ consistently outperforms existing supervised cross-modal hashing approaches, showcasing its significant potential.
Towards Cross-modal Backward-compatible Representation Learning for Vision-Language Models
May 23, 2024Modern retrieval systems often struggle with upgrading to new and more powerful models due to the incompatibility of embeddings between the old and new models. This necessitates a costly process known as backfilling, which involves re-computing the embeddings for a large number of data samples. In vision, Backward-compatible Training (BT) has been proposed to ensure that the new model aligns with the old model's embeddings. This paper extends the concept of vision-only BT to the field of cross-modal retrieval, marking the first attempt to address Cross-modal BT (XBT). Our goal is to achieve backward-compatibility between Vision-Language Pretraining (VLP) models, such as CLIP, for the cross-modal retrieval task. To address XBT challenges, we propose an efficient solution: a projection module that maps the new model's embeddings to those of the old model. This module, pretrained solely with text data, significantly reduces the number of image-text pairs required for XBT learning, and, once it is pretrained, it avoids using the old model during training. Furthermore, we utilize parameter-efficient training strategies that improve efficiency and preserve the off-the-shelf new model's knowledge by avoiding any modifications. Experimental results on cross-modal retrieval datasets demonstrate the effectiveness of XBT and its potential to enable backfill-free upgrades when a new VLP model emerges.