 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEIA: Latent View-invariant Embeddings for Implicit 3D Articulation
Sep 10, 2024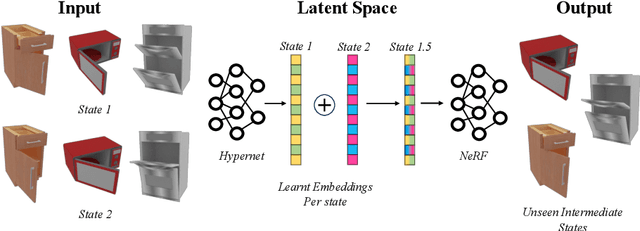
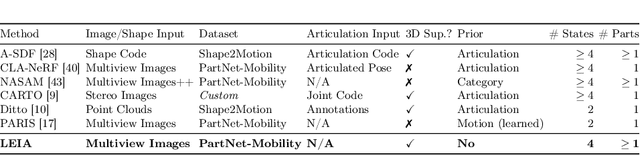
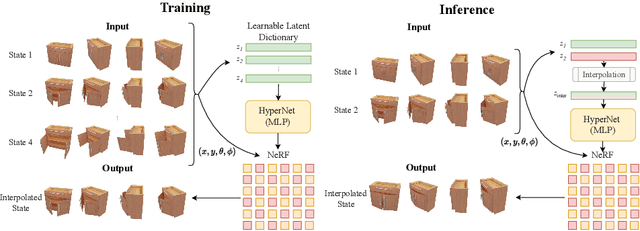

Neural Radiance Fields (NeRFs) have revolutionized the reconstruction of static scenes and objects in 3D, offering unprecedented quality. However, extending NeRFs to model dynamic objects or object articulations remains a challenging problem. Previous works have tackled this issue by focusing on part-level reconstruction and motion estimation for objects, but they often rely on heuristics regarding the number of moving parts or object categories, which can limit their practical use. In this work, we introduce LEIA, a novel approach for representing dynamic 3D objects. Our method involves observing the object at distinct time steps or "states" and conditioning a hypernetwork on the current state, using this to parameterize our NeRF. This approach allows us to learn a view-invariant latent representation for each state. We further demonstrate that by interpolating between these states, we can generate novel articulation configurations in 3D space that were previously unseen. Our experimental results highlight the effectiveness of our method in articulating objects in a manner that is independent of the viewing angle and joint configuration. Notably, our approach outperforms previous methods that rely on motion information for articulation registration.
UVIS: Unsupervised Video Instance Segmentation
Jun 11, 2024



Video instance segmentation requires classifying, segmenting, and tracking every object across video frames. Unlike existing approaches that rely on masks, boxes, or category labels, we propose UVIS, a novel Unsupervised Video Instance Segmentation (UVIS) framework that can perform video instance segmentation without any video annotations or dense label-based pretraining. Our key insight comes from leveraging the dense shape prior from the self-supervised vision foundation model DINO and the openset recognition ability from the image-caption supervised vision-language model CLIP. Our UVIS framework consists of three essential steps: frame-level pseudo-label generation, transformer-based VIS model training, and query-based tracking. To improve the quality of VIS predictions in the unsupervised setup, we introduce a dual-memory design. This design includes a semantic memory bank for generating accurate pseudo-labels and a tracking memory bank for maintaining temporal consistency in object tracks. We evaluate our approach on three standard VIS benchmarks, namely YoutubeVIS-2019, YoutubeVIS-2021, and Occluded VIS. Our UVIS achieves 21.1 AP on YoutubeVIS-2019 without any video annotations or dense pretraining, demonstrating the potential of our unsupervised VIS framework.
Measuring Style Similarity in Diffusion Models
Apr 01, 2024



Generative models are now widely used by graphic designers and artists. Prior works have shown that these models remember and often replicate content from their training data during generation. Hence as their proliferation increases, it has become important to perform a database search to determine whether the properties of the image are attributable to specific training data, every time before a generated image is used for professional purposes. Existing tools for this purpose focus on retrieving images of similar semantic content. Meanwhile, many artists are concerned with style replication in text-to-image models. We present a framework for understanding and extracting style descriptors from images. Our framework comprises a new dataset curated using the insight that style is a subjective property of an image that captures complex yet meaningful interactions of factors including but not limited to colors, textures, shapes, etc. We also propose a method to extract style descriptors that can be used to attribute style of a generated image to the images used in the training dataset of a text-to-image model. We showcase promising results in various style retrieval tasks. We also quantitatively and qualitatively analyze style attribution and matching in the Stable Diffusion model. Code and artifacts are available at https://github.com/learn2phoenix/CSD.
LiFT: A Surprisingly Simple Lightweight Feature Transform for Dense ViT Descriptors
Mar 21, 2024We present a simple self-supervised method to enhance the performance of ViT features for dense downstream tasks. Our Lightweight Feature Transform (LiFT) is a straightforward and compact postprocessing network that can be applied to enhance the features of any pre-trained ViT backbone. LiFT is fast and easy to train with a self-supervised objective, and it boosts the density of ViT features for minimal extra inference cost. Furthermore, we demonstrate that LiFT can be applied with approaches that use additional task-specific downstream modules, as we integrate LiFT with ViTDet for COCO detection and segmentation. Despite the simplicity of LiFT, we find that it is not simply learning a more complex version of bilinear interpolation. Instead, our LiFT training protocol leads to several desirable emergent properties that benefit ViT features in dense downstream tasks. This includes greater scale invariance for features, and better object boundary maps. By simply training LiFT for a few epochs, we show improved performance on keypoint correspondence, detection, segmentation, and object discovery tasks. Overall, LiFT provides an easy way to unlock the benefits of denser feature arrays for a fraction of the computational cost. For more details, refer to our project page at https://www.cs.umd.edu/~sakshams/LiFT/.
EAGLES: Efficient Accelerated 3D Gaussians with Lightweight EncodingS
Dec 07, 2023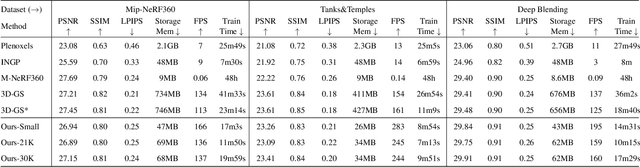
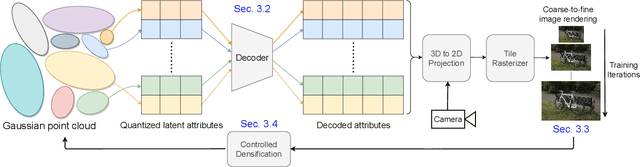
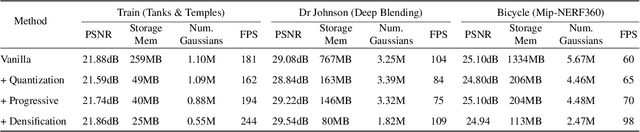
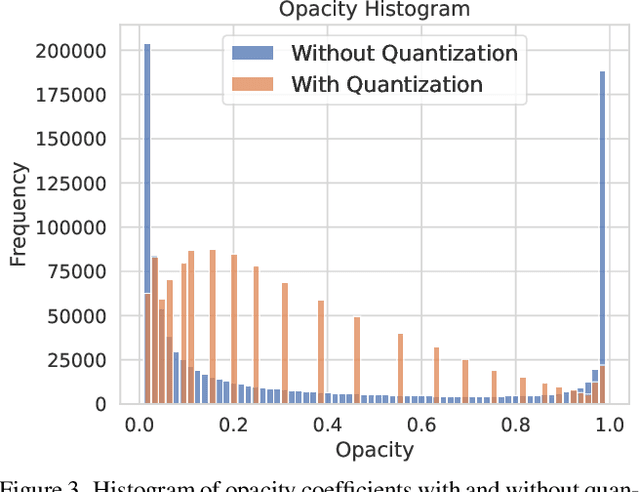
Recently, 3D Gaussian splatting (3D-GS) has gained popularity in novel-view scene synthesis. It addresses the challenges of lengthy training times and slow rendering speeds associated with Neural Radiance Fields (NeRFs). Through rapid, differentiable rasterization of 3D Gaussians, 3D-GS achieves real-time rendering and accelerated training. They, however, demand substantial memory resources for both training and storage, as they require millions of Gaussians in their point cloud representation for each scene. We present a technique utilizing quantized embeddings to significantly reduce memory storage requirements and a coarse-to-fine training strategy for a faster and more stable optimization of the Gaussian point clouds. Our approach results in scene representations with fewer Gaussians and quantized representations, leading to faster training times and rendering speeds for real-time rendering of high resolution scenes. We reduce memory by more than an order of magnitude all while maintaining the reconstruction quality. We validate the effectiveness of our approach on a variety of datasets and scenes preserving the visual quality while consuming 10-20x less memory and faster training/inference speed. Project page and code is available https://efficientgaussian.github.io
Toward Scalable Visual Servoing Using Deep Reinforcement Learning and Optimal Control
Oct 02, 2023Classical pixel-based Visual Servoing (VS) approaches offer high accuracy but suffer from a limited convergence area due to optimization nonlinearity. Modern deep learning-based VS methods overcome traditional vision issues but lack scalability, requiring training on limited scenes. This paper proposes a hybrid VS strategy utilizing Deep Reinforcement Learning (DRL) and optimal control to enhance both convergence area and scalability. The DRL component of our approach separately handles representation and policy learning to enhance scalability, generalizability, learning efficiency and ease domain adaptation. Moreover, the optimal control part ensures high end-point accuracy. Our method showcases remarkable achievements in terms of high convergence rates and minimal end-positioning errors using a 7-DOF manipulator. Importantly, it exhibits scalability across more than 1000 distinct scenes. Furthermore, we demonstrate its capacity for generalization to previously unseen datasets. Lastly, we illustrate the real-world applicability of our approach, highlighting its adaptability through single-shot domain transfer learning in environments with noise and occlusions. Real-robot experiments can be found at \url{https://sites.google.com/view/vsls}.
SHACIRA: Scalable HAsh-grid Compression for Implicit Neural Representations
Sep 27, 2023



Implicit Neural Representations (INR) or neural fields have emerged as a popular framework to encode multimedia signals such as images and radiance fields while retaining high-quality. Recently, learnable feature grids proposed by Instant-NGP have allowed significant speed-up in the training as well as the sampling of INRs by replacing a large neural network with a multi-resolution look-up table of feature vectors and a much smaller neural network. However, these feature grids come at the expense of large memory consumption which can be a bottleneck for storage and streaming applications. In this work, we propose SHACIRA, a simple yet effective task-agnostic framework for compressing such feature grids with no additional post-hoc pruning/quantization stages. We reparameterize feature grids with quantized latent weights and apply entropy regularization in the latent space to achieve high levels of compression across various domains. Quantitative and qualitative results on diverse datasets consisting of images, videos, and radiance fields, show that our approach outperforms existing INR approaches without the need for any large datasets or domain-specific heuristics. Our project page is available at http://shacira.github.io .
Chop & Learn: Recognizing and Generating Object-State Compositions
Sep 25, 2023



Recognizing and generating object-state compositions has been a challenging task, especially when generalizing to unseen compositions. In this paper, we study the task of cutting objects in different styles and the resulting object state changes. We propose a new benchmark suite Chop & Learn, to accommodate the needs of learning objects and different cut styles using multiple viewpoints. We also propose a new task of Compositional Image Generation, which can transfer learned cut styles to different objects, by generating novel object-state images. Moreover, we also use the videos for Compositional Action Recognition, and show valuable uses of this dataset for multiple video tasks. Project website: https://chopnlearn.github.io.
ASIC: Aligning Sparse in-the-wild Image Collections
Mar 28, 2023We present a method for joint alignment of sparse in-the-wild image collections of an object category. Most prior works assume either ground-truth keypoint annotations or a large dataset of images of a single object category. However, neither of the above assumptions hold true for the long-tail of the objects present in the world. We present a self-supervised technique that directly optimizes on a sparse collection of images of a particular object/object category to obtain consistent dense correspondences across the collection. We use pairwise nearest neighbors obtained from deep features of a pre-trained vision transformer (ViT) model as noisy and sparse keypoint matches and make them dense and accurate matches by optimizing a neural network that jointly maps the image collection into a learned canonical grid. Experiments on CUB and SPair-71k benchmarks demonstrate that our method can produce globally consistent and higher quality correspondences across the image collection when compared to existing self-supervised methods. Code and other material will be made available at \url{https://kampta.github.io/asic}.
Teaching Matters: Investigating the Role of Supervision in Vision Transformers
Dec 07, 2022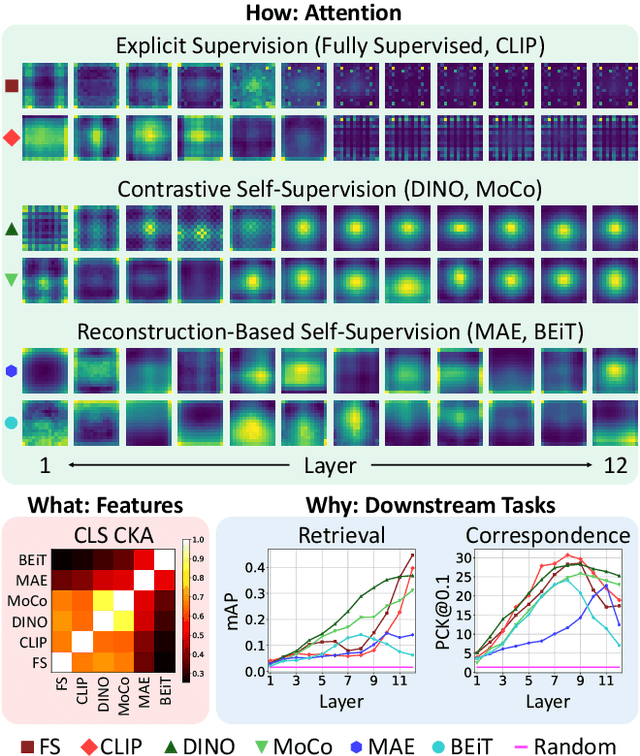

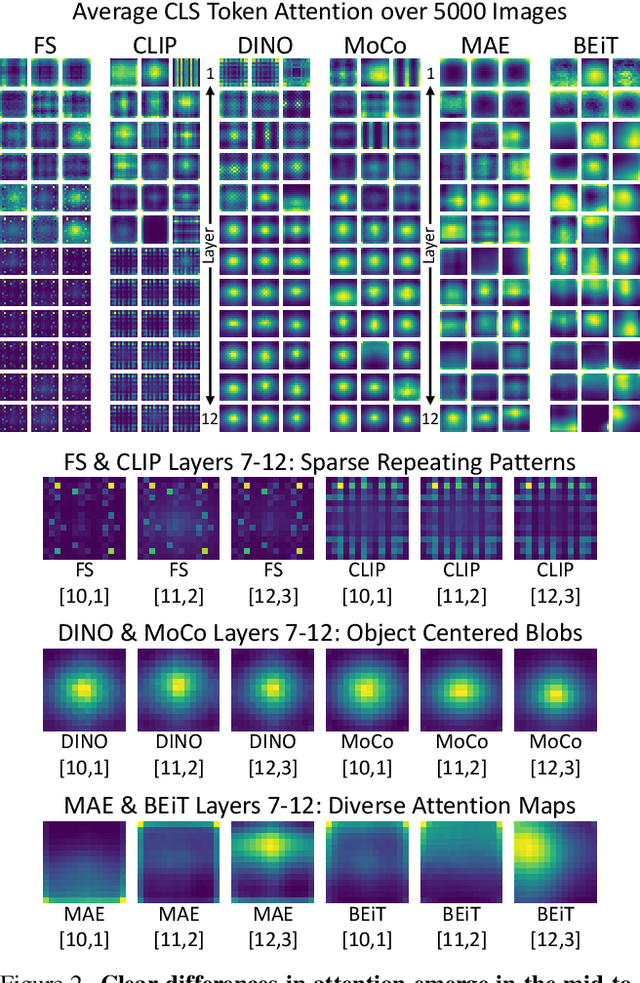
Vision Transformers (ViTs) have gained significant popularity in recent years and have proliferated into many applications. However, it is not well explored how varied their behavior is under different learning paradigms. We compare ViTs trained through different methods of supervision, and show that they learn a diverse range of behaviors in terms of their attention, representations, and downstream performance. We also discover ViT behaviors that are consistent across supervision, including the emergence of Offset Local Attention Heads. These are self-attention heads that attend to a token adjacent to the current token with a fixed directional offset, a phenomenon that to the best of our knowledge has not been highlighted in any prior work. Our analysis shows that ViTs are highly flexible and learn to process local and global information in different orders depending on their training method. We find that contrastive self-supervised methods learn features that are competitive with explicitly supervised features, and they can even be superior for part-level tasks. We also find that the representations of reconstruction-based models show non-trivial similarity to contrastive self-supervised models. Finally, we show how the "best" layer for a given task varies by both supervision method and task, further demonstrating the differing order of information processing in ViTs.