 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaking the Right Language: The Impact of Expertise Alignment in User-AI Interactions
Feb 25, 2025



Using a sample of 25,000 Bing Copilot conversations, we study how the agent responds to users of varying levels of domain expertise and the resulting impact on user experience along multiple dimensions. Our findings show that across a variety of topical domains, the agent largely responds at proficient or expert levels of expertise (77% of conversations) which correlates with positive user experience regardless of the user's level of expertise. Misalignment, such that the agent responds at a level of expertise below that of the user, has a negative impact on overall user experience, with the impact more profound for more complex tasks. We also show that users engage more, as measured by the number of words in the conversation, when the agent responds at a level of expertise commensurate with that of the user. Our findings underscore the importance of alignment between user and AI when designing human-centered AI systems, to ensure satisfactory and productive interactions.
Plausibly Problematic Questions in Multiple-Choice Benchmarks for Commonsense Reasoning
Oct 06, 2024Questions involving commonsense reasoning about everyday situations often admit many $\textit{possible}$ or $\textit{plausible}$ answers. In contrast, multiple-choice question (MCQ) benchmarks for commonsense reasoning require a hard selection of a single correct answer, which, in principle, should represent the $\textit{most}$ plausible answer choice. On $250$ MCQ items sampled from two commonsense reasoning benchmarks, we collect $5,000$ independent plausibility judgments on answer choices. We find that for over 20% of the sampled MCQs, the answer choice rated most plausible does not match the benchmark gold answers; upon manual inspection, we confirm that this subset exhibits higher rates of problems like ambiguity or semantic mismatch between question and answer choices. Experiments with LLMs reveal low accuracy and high variation in performance on the subset, suggesting our plausibility criterion may be helpful in identifying more reliable benchmark items for commonsense evaluation.
Measuring Style Similarity in Diffusion Models
Apr 01, 2024



Generative models are now widely used by graphic designers and artists. Prior works have shown that these models remember and often replicate content from their training data during generation. Hence as their proliferation increases, it has become important to perform a database search to determine whether the properties of the image are attributable to specific training data, every time before a generated image is used for professional purposes. Existing tools for this purpose focus on retrieving images of similar semantic content. Meanwhile, many artists are concerned with style replication in text-to-image models. We present a framework for understanding and extracting style descriptors from images. Our framework comprises a new dataset curated using the insight that style is a subjective property of an image that captures complex yet meaningful interactions of factors including but not limited to colors, textures, shapes, etc. We also propose a method to extract style descriptors that can be used to attribute style of a generated image to the images used in the training dataset of a text-to-image model. We showcase promising results in various style retrieval tasks. We also quantitatively and qualitatively analyze style attribution and matching in the Stable Diffusion model. Code and artifacts are available at https://github.com/learn2phoenix/CSD.
It's Not Easy Being Wrong: Evaluating Process of Elimination Reasoning in Large Language Models
Nov 13, 2023



Chain-of-thought (COT) prompting can help large language models (LLMs) reason toward correct answers, but its efficacy in reasoning toward incorrect answers is unexplored. This strategy of process of elimination (PoE), when used with COT, has the potential to enhance interpretability in tasks like medical diagnoses of exclusion. Thus, we propose PoE with COT, a new task where LLMs must reason toward incorrect options on multiple-choice questions. We evaluate the ability of GPT-3.5, LLaMA-2, and Falcon to perform PoE with COT on 2-choice commonsense and scientific reasoning datasets. We show that PoE consistently underperforms directly choosing the correct answer. The agreement of these strategies is also lower than the self-consistency of each strategy. To study these issues further, we conduct an error analysis and give suggestions for future work.
Investigating Information Inconsistency in Multilingual Open-Domain Question Answering
May 25, 2022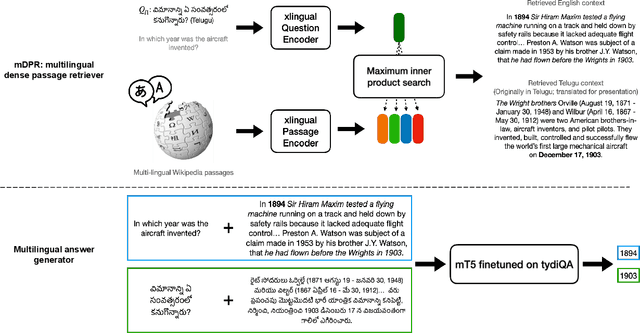

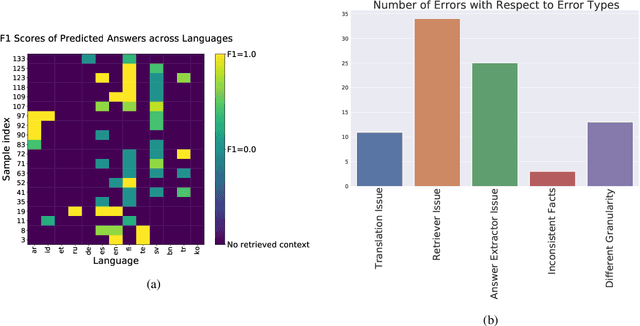
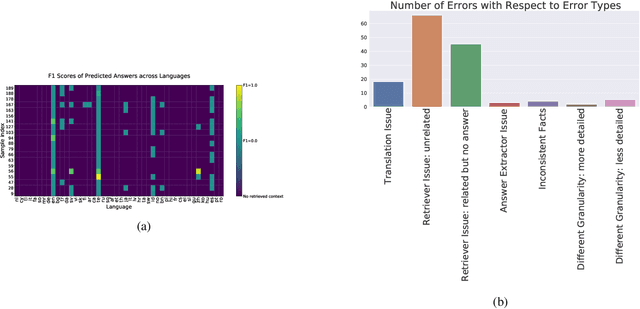
Retrieval based open-domain QA systems use retrieved documents and answer-span selection over retrieved documents to find best-answer candidates. We hypothesize that multilingual Question Answering (QA) systems are prone to information inconsistency when it comes to documents written in different languages, because these documents tend to provide a model with varying information about the same topic. To understand the effects of the biased availability of information and cultural influence, we analyze the behavior of multilingual open-domain question answering models with a focus on retrieval bias. We analyze if different retriever models present different passages given the same question in different languages on TyDi QA and XOR-TyDi QA, two multilingualQA datasets. We speculate that the content differences in documents across languages might reflect cultural divergences and/or social biases.