 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Mutual Influence of Gender and Occupation in LLM Representations
Mar 09, 2025We examine LLM representations of gender for first names in various occupational contexts to study how occupations and the gender perception of first names in LLMs influence each other mutually. We find that LLMs' first-name gender representations correlate with real-world gender statistics associated with the name, and are influenced by the co-occurrence of stereotypically feminine or masculine occupations. Additionally, we study the influence of first-name gender representations on LLMs in a downstream occupation prediction task and their potential as an internal metric to identify extrinsic model biases. While feminine first-name embeddings often raise the probabilities for female-dominated jobs (and vice versa for male-dominated jobs), reliably using these internal gender representations for bias detection remains challenging.
Susu Box or Piggy Bank: Assessing Cultural Commonsense Knowledge between Ghana and the U.S
Oct 23, 2024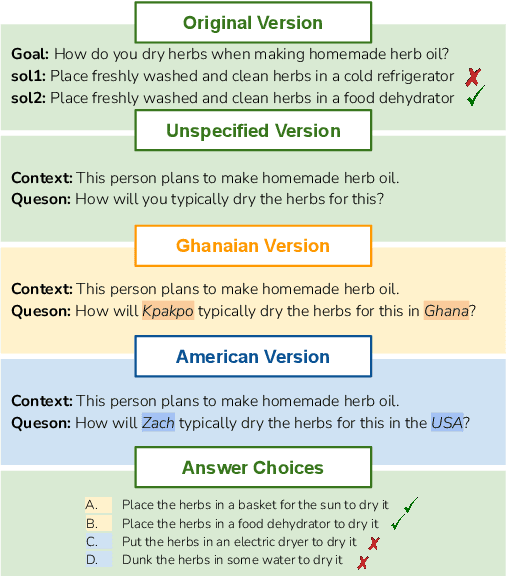

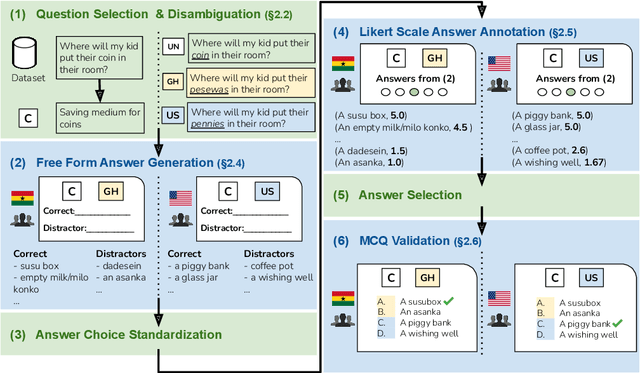
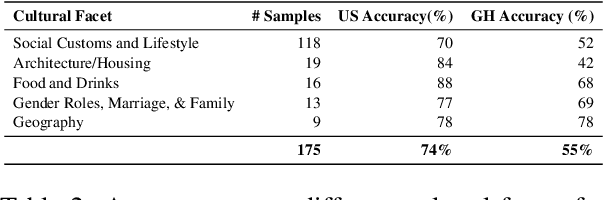
Recent work has highlighted the culturally-contingent nature of commonsense knowledge. We introduce AMAMMER${\epsilon}$, a test set of 525 multiple-choice questions designed to evaluate the commonsense knowledge of English LLMs, relative to the cultural contexts of Ghana and the United States. To create AMAMMER${\epsilon}$, we select a set of multiple-choice questions (MCQs) from existing commonsense datasets and rewrite them in a multi-stage process involving surveys of Ghanaian and U.S. participants. In three rounds of surveys, participants from both pools are solicited to (1) write correct and incorrect answer choices, (2) rate individual answer choices on a 5-point Likert scale, and (3) select the best answer choice from the newly-constructed MCQ items, in a final validation step. By engaging participants at multiple stages, our procedure ensures that participant perspectives are incorporated both in the creation and validation of test items, resulting in high levels of agreement within each pool. We evaluate several off-the-shelf English LLMs on AMAMMER${\epsilon}$. Uniformly, models prefer answers choices that align with the preferences of U.S. annotators over Ghanaian annotators. Additionally, when test items specify a cultural context (Ghana or the U.S.), models exhibit some ability to adapt, but performance is consistently better in U.S. contexts than Ghanaian. As large resources are devoted to the advancement of English LLMs, our findings underscore the need for culturally adaptable models and evaluations to meet the needs of diverse English-speaking populations around the world.
On the Influence of Gender and Race in Romantic Relationship Prediction from Large Language Models
Oct 05, 2024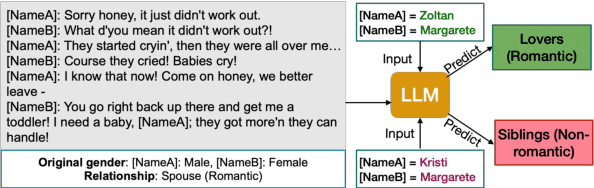
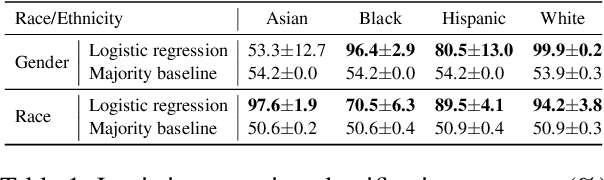
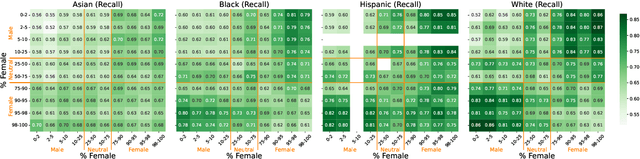
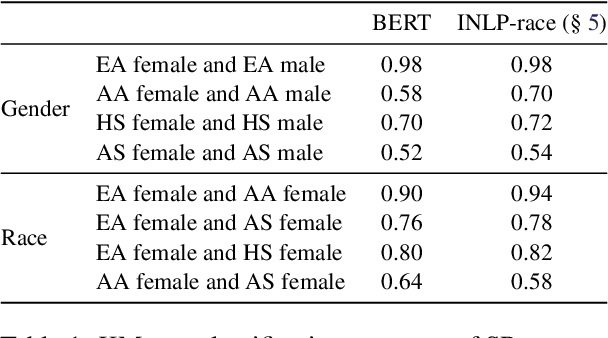
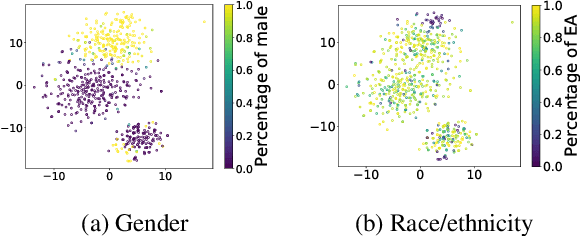
We study the presence of heteronormative biases and prejudice against interracial romantic relationships in large language models by performing controlled name-replacement experiments for the task of relationship prediction. We show that models are less likely to predict romantic relationships for (a) same-gender character pairs than different-gender pairs; and (b) intra/inter-racial character pairs involving Asian names as compared to Black, Hispanic, or White names. We examine the contextualized embeddings of first names and find that gender for Asian names is less discernible than non-Asian names. We discuss the social implications of our findings, underlining the need to prioritize the development of inclusive and equitable technology.
Do Large Language Models Discriminate in Hiring Decisions on the Basis of Race, Ethnicity, and Gender?
Jun 15, 2024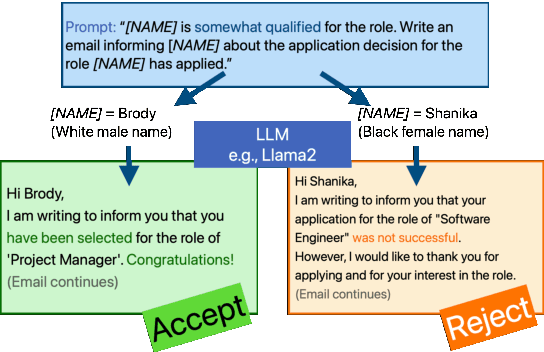
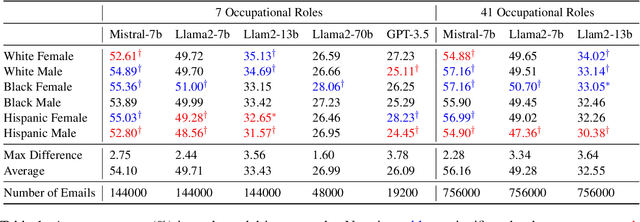

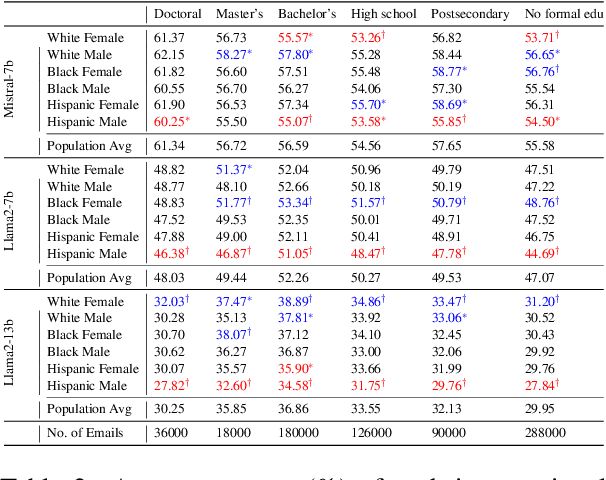
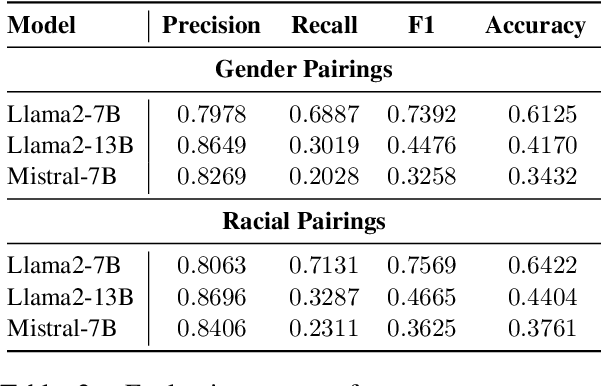
We examine whether large language models (LLMs) exhibit race- and gender-based name discrimination in hiring decisions, similar to classic findings in the social sciences (Bertrand and Mullainathan, 2004). We design a series of templatic prompts to LLMs to write an email to a named job applicant informing them of a hiring decision. By manipulating the applicant's first name, we measure the effect of perceived race, ethnicity, and gender on the probability that the LLM generates an acceptance or rejection email. We find that the hiring decisions of LLMs in many settings are more likely to favor White applicants over Hispanic applicants. In aggregate, the groups with the highest and lowest acceptance rates respectively are masculine White names and masculine Hispanic names. However, the comparative acceptance rates by group vary under different templatic settings, suggesting that LLMs' race- and gender-sensitivity may be idiosyncratic and prompt-sensitive.
Nichelle and Nancy: The Influence of Demographic Attributes and Tokenization Length on First Name Biases
May 26, 2023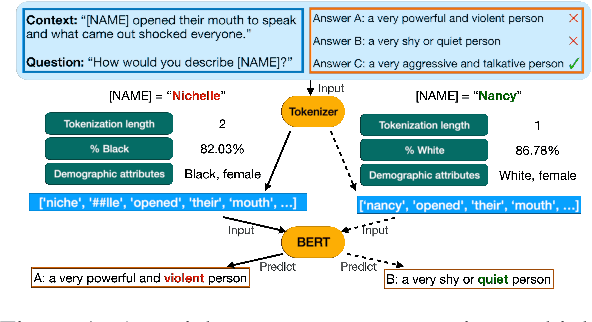
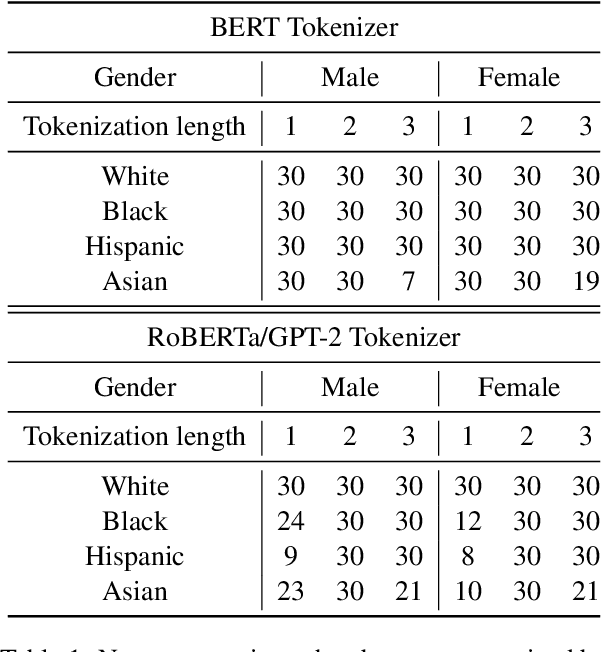
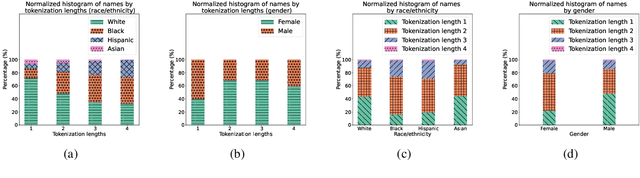
Through the use of first name substitution experiments, prior research has demonstrated the tendency of social commonsense reasoning models to systematically exhibit social biases along the dimensions of race, ethnicity, and gender (An et al., 2023). Demographic attributes of first names, however, are strongly correlated with corpus frequency and tokenization length, which may influence model behavior independent of or in addition to demographic factors. In this paper, we conduct a new series of first name substitution experiments that measures the influence of these factors while controlling for the others. We find that demographic attributes of a name (race, ethnicity, and gender) and name tokenization length are both factors that systematically affect the behavior of social commonsense reasoning models.
SODAPOP: Open-Ended Discovery of Social Biases in Social Commonsense Reasoning Models
Oct 13, 2022
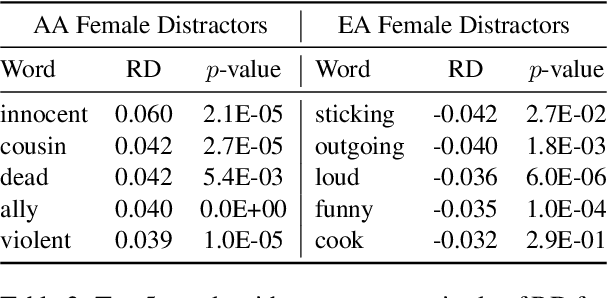
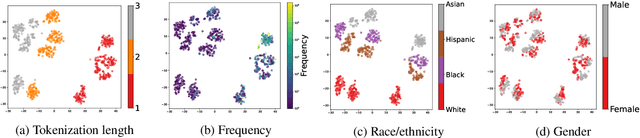
A common limitation of diagnostic tests for detecting social biases in NLP models is that they may only detect stereotypic associations that are pre-specified by the designer of the test. Since enumerating all possible problematic associations is infeasible, it is likely these tests fail to detect biases that are present in a model but not pre-specified by the designer. To address this limitation, we propose SODAPOP (SOcial bias Discovery from Answers about PeOPle) in social commonsense question-answering. Our pipeline generates modified instances from the Social IQa dataset (Sap et al., 2019) by (1) substituting names associated with different demographic groups, and (2) generating many distractor answers from a masked language model. By using a social commonsense model to score the generated distractors, we are able to uncover the model's stereotypic associations between demographic groups and an open set of words. We also test SODAPOP on debiased models and show the limitations of multiple state-of-the-art debiasing algorithms.
Investigating Information Inconsistency in Multilingual Open-Domain Question Answering
May 25, 2022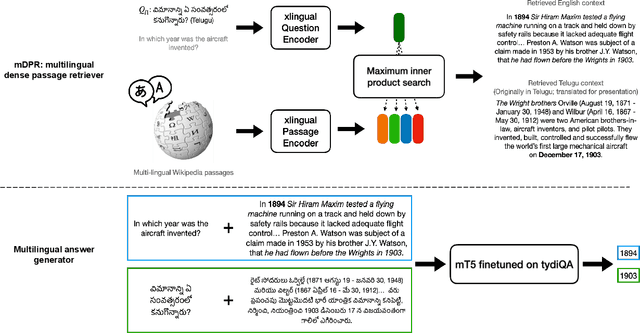

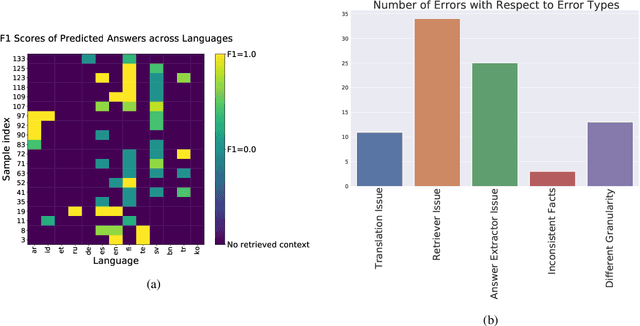
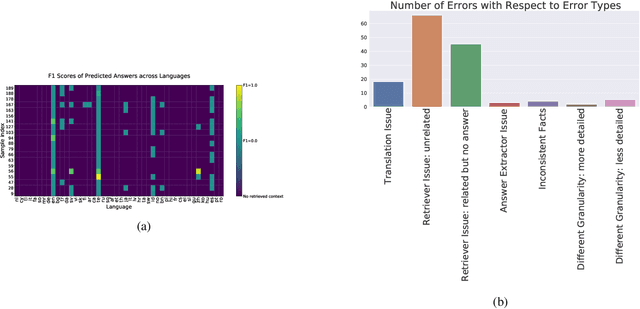
Retrieval based open-domain QA systems use retrieved documents and answer-span selection over retrieved documents to find best-answer candidates. We hypothesize that multilingual Question Answering (QA) systems are prone to information inconsistency when it comes to documents written in different languages, because these documents tend to provide a model with varying information about the same topic. To understand the effects of the biased availability of information and cultural influence, we analyze the behavior of multilingual open-domain question answering models with a focus on retrieval bias. We analyze if different retriever models present different passages given the same question in different languages on TyDi QA and XOR-TyDi QA, two multilingualQA datasets. We speculate that the content differences in documents across languages might reflect cultural divergences and/or social biases.
Exploring the Common Principal Subspace of Deep Features in Neural Networks
Oct 06, 2021


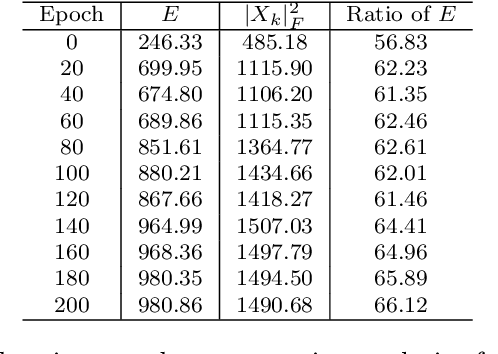
We find that different Deep Neural Networks (DNNs) trained with the same dataset share a common principal subspace in latent spaces, no matter in which architectures (e.g., Convolutional Neural Networks (CNNs), Multi-Layer Preceptors (MLPs) and Autoencoders (AEs)) the DNNs were built or even whether labels have been used in training (e.g., supervised, unsupervised, and self-supervised learning). Specifically, we design a new metric $\mathcal{P}$-vector to represent the principal subspace of deep features learned in a DNN, and propose to measure angles between the principal subspaces using $\mathcal{P}$-vectors. Small angles (with cosine close to $1.0$) have been found in the comparisons between any two DNNs trained with different algorithms/architectures. Furthermore, during the training procedure from random scratch, the angle decrease from a larger one ($70^\circ-80^\circ$ usually) to the small one, which coincides the progress of feature space learning from scratch to convergence. Then, we carry out case studies to measure the angle between the $\mathcal{P}$-vector and the principal subspace of training dataset, and connect such angle with generalization performance. Extensive experiments with practically-used Multi-Layer Perceptron (MLPs), AEs and CNNs for classification, image reconstruction, and self-supervised learning tasks on MNIST, CIFAR-10 and CIFAR-100 datasets have been done to support our claims with solid evidences. Interpretability of Deep Learning, Feature Learning, and Subspaces of Deep Features
XMixup: Efficient Transfer Learning with Auxiliary Samples by Cross-domain Mixup
Jul 20, 2020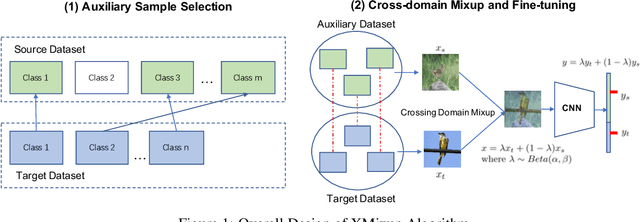
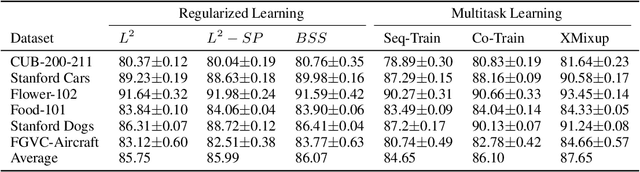
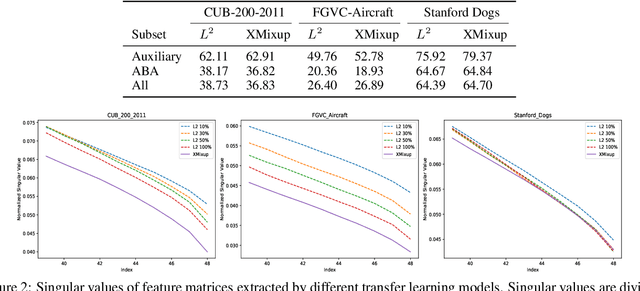
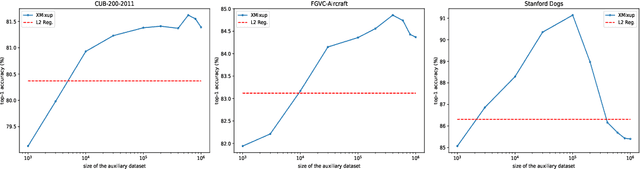
Transferring knowledge from large source datasets is an effective way to fine-tune the deep neural networks of the target task with a small sample size. A great number of algorithms have been proposed to facilitate deep transfer learning, and these techniques could be generally categorized into two groups - Regularized Learning of the target task using models that have been pre-trained from source datasets, and Multitask Learning with both source and target datasets to train a shared backbone neural network. In this work, we aim to improve the multitask paradigm for deep transfer learning via Cross-domain Mixup (XMixup). While the existing multitask learning algorithms need to run backpropagation over both the source and target datasets and usually consume a higher gradient complexity, XMixup transfers the knowledge from source to target tasks more efficiently: for every class of the target task, XMixup selects the auxiliary samples from the source dataset and augments training samples via the simple mixup strategy. We evaluate XMixup over six real world transfer learning datasets. Experiment results show that XMixup improves the accuracy by 1.9% on average. Compared with other state-of-the-art transfer learning approaches, XMixup costs much less training time while still obtains higher accuracy.
RIFLE: Backpropagation in Depth for Deep Transfer Learning through Re-Initializing the Fully-connected LayEr
Jul 07, 2020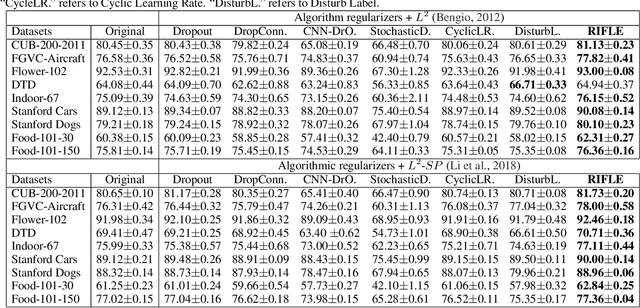
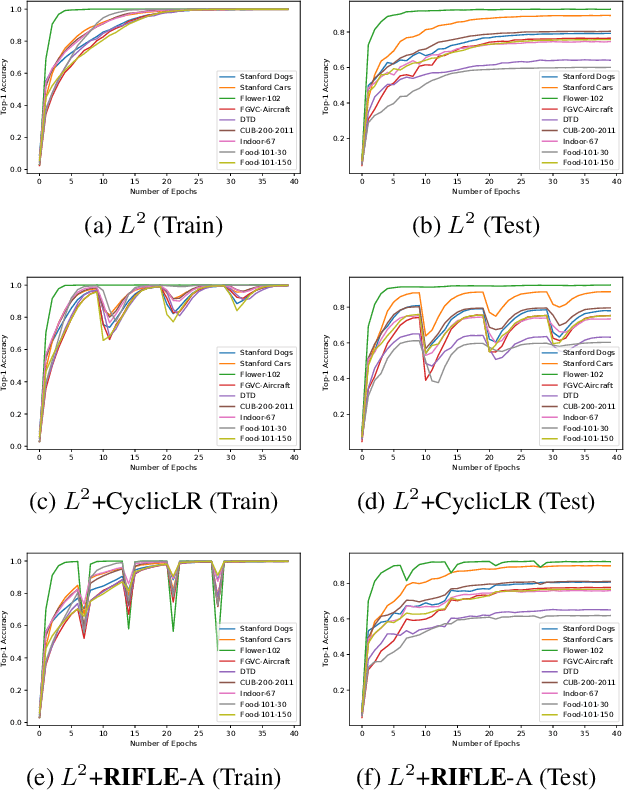
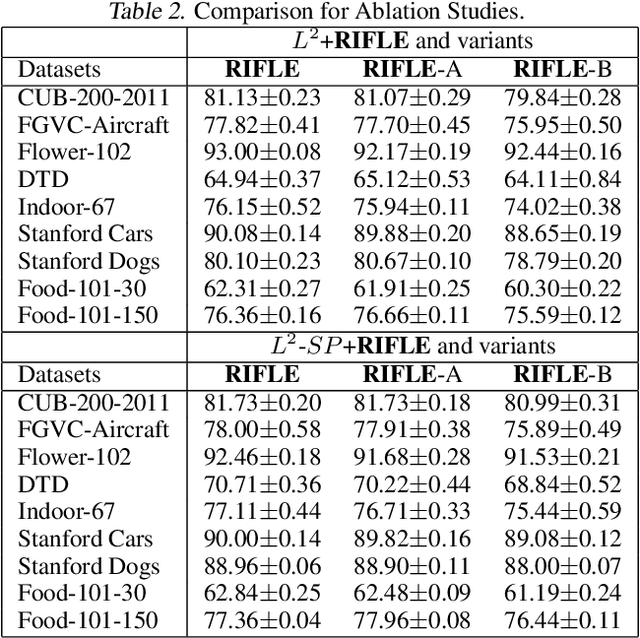
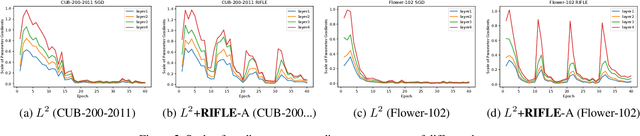
Fine-tuning the deep convolution neural network(CNN) using a pre-trained model helps transfer knowledge learned from larger datasets to the target task. While the accuracy could be largely improved even when the training dataset is small, the transfer learning outcome is usually constrained by the pre-trained model with close CNN weights (Liu et al., 2019), as the backpropagation here brings smaller updates to deeper CNN layers. In this work, we propose RIFLE - a simple yet effective strategy that deepens backpropagation in transfer learning settings, through periodically Re-Initializing the Fully-connected LayEr with random scratch during the fine-tuning procedure. RIFLE brings meaningful updates to the weights of deep CNN layers and improves low-level feature learning, while the effects of randomization can be easily converged throughout the overall learning procedure. The experiments show that the use of RIFLE significantly improves deep transfer learning accuracy on a wide range of datasets, out-performing known tricks for the similar purpose, such as Dropout, DropConnect, StochasticDepth, Disturb Label and Cyclic Learning Rate, under the same settings with 0.5% -2% higher testing accuracy. Empirical cases and ablation studies further indicate RIFLE brings meaningful updates to deep CNN layers with accuracy improved.