 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Mutual Influence of Gender and Occupation in LLM Representations
Mar 09, 2025We examine LLM representations of gender for first names in various occupational contexts to study how occupations and the gender perception of first names in LLMs influence each other mutually. We find that LLMs' first-name gender representations correlate with real-world gender statistics associated with the name, and are influenced by the co-occurrence of stereotypically feminine or masculine occupations. Additionally, we study the influence of first-name gender representations on LLMs in a downstream occupation prediction task and their potential as an internal metric to identify extrinsic model biases. While feminine first-name embeddings often raise the probabilities for female-dominated jobs (and vice versa for male-dominated jobs), reliably using these internal gender representations for bias detection remains challenging.
On the Influence of Gender and Race in Romantic Relationship Prediction from Large Language Models
Oct 05, 2024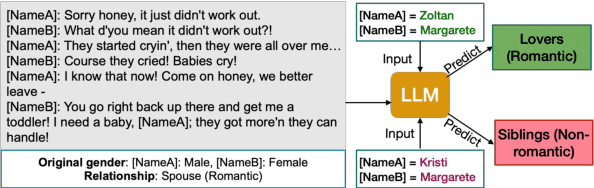
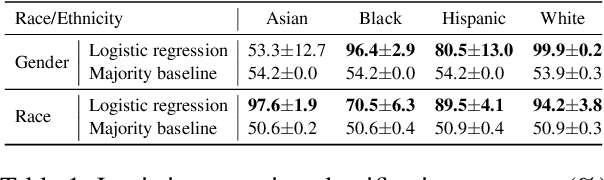
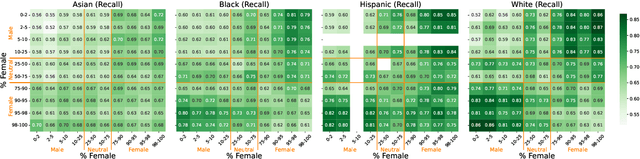
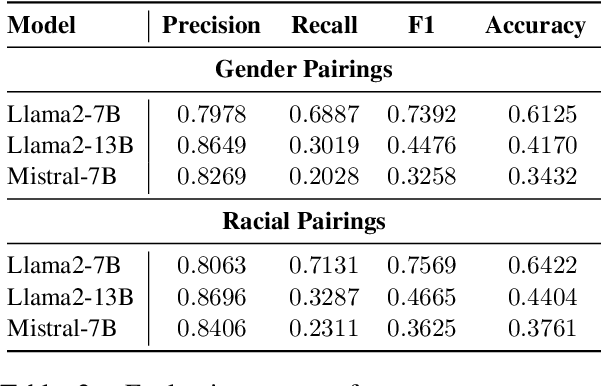
We study the presence of heteronormative biases and prejudice against interracial romantic relationships in large language models by performing controlled name-replacement experiments for the task of relationship prediction. We show that models are less likely to predict romantic relationships for (a) same-gender character pairs than different-gender pairs; and (b) intra/inter-racial character pairs involving Asian names as compared to Black, Hispanic, or White names. We examine the contextualized embeddings of first names and find that gender for Asian names is less discernible than non-Asian names. We discuss the social implications of our findings, underlining the need to prioritize the development of inclusive and equitable technology.
Post-Hoc Answer Attribution for Grounded and Trustworthy Long Document Comprehension: Task, Insights, and Challenges
Jun 11, 2024Attributing answer text to its source document for information-seeking questions is crucial for building trustworthy, reliable, and accountable systems. We formulate a new task of post-hoc answer attribution for long document comprehension (LDC). Owing to the lack of long-form abstractive and information-seeking LDC datasets, we refactor existing datasets to assess the strengths and weaknesses of existing retrieval-based and proposed answer decomposition and textual entailment-based optimal selection attribution systems for this task. We throw light on the limitations of existing datasets and the need for datasets to assess the actual performance of systems on this task.
How much reliable is ChatGPT's prediction on Information Extraction under Input Perturbations?
Apr 07, 2024In this paper, we assess the robustness (reliability) of ChatGPT under input perturbations for one of the most fundamental tasks of Information Extraction (IE) i.e. Named Entity Recognition (NER). Despite the hype, the majority of the researchers have vouched for its language understanding and generation capabilities; a little attention has been paid to understand its robustness: How the input-perturbations affect 1) the predictions, 2) the confidence of predictions and 3) the quality of rationale behind its prediction. We perform a systematic analysis of ChatGPT's robustness (under both zero-shot and few-shot setup) on two NER datasets using both automatic and human evaluation. Based on automatic evaluation metrics, we find that 1) ChatGPT is more brittle on Drug or Disease replacements (rare entities) compared to the perturbations on widely known Person or Location entities, 2) the quality of explanations for the same entity considerably differ under different types of "Entity-Specific" and "Context-Specific" perturbations and the quality can be significantly improved using in-context learning, and 3) it is overconfident for majority of the incorrect predictions, and hence it could lead to misguidance of the end-users.
What to Read in a Contract? Party-Specific Summarization of Important Obligations, Entitlements, and Prohibitions in Legal Documents
Dec 19, 2022Legal contracts, such as employment or lease agreements, are important documents as they govern the obligations and entitlements of the various contracting parties. However, these documents are typically long and written in legalese resulting in lots of manual hours spent in understanding them. In this paper, we address the task of summarizing legal contracts for each of the contracting parties, to enable faster reviewing and improved understanding of them. Specifically, we collect a dataset consisting of pairwise importance comparison annotations by legal experts for ~293K sentence pairs from lease agreements. We propose a novel extractive summarization system to automatically produce a summary consisting of the most important obligations, entitlements, and prohibitions in a contract. It consists of two modules: (1) a content categorize to identify sentences containing each of the categories (i.e., obligation, entitlement, and prohibition) for a party, and (2) an importance ranker to compare the importance among sentences of each category for a party to obtain a ranked list. The final summary is produced by selecting the most important sentences of a category for each of the parties. We demonstrate the effectiveness of our proposed system by comparing it against several text ranking baselines via automatic and human evaluation.
Agent-Specific Deontic Modality Detection in Legal Language
Nov 23, 2022Legal documents are typically long and written in legalese, which makes it particularly difficult for laypeople to understand their rights and duties. While natural language understanding technologies can be valuable in supporting such understanding in the legal domain, the limited availability of datasets annotated for deontic modalities in the legal domain, due to the cost of hiring experts and privacy issues, is a bottleneck. To this end, we introduce, LEXDEMOD, a corpus of English contracts annotated with deontic modality expressed with respect to a contracting party or agent along with the modal triggers. We benchmark this dataset on two tasks: (i) agent-specific multi-label deontic modality classification, and (ii) agent-specific deontic modality and trigger span detection using Transformer-based (Vaswani et al., 2017) language models. Transfer learning experiments show that the linguistic diversity of modal expressions in LEXDEMOD generalizes reasonably from lease to employment and rental agreements. A small case study indicates that a model trained on LEXDEMOD can detect red flags with high recall. We believe our work offers a new research direction for deontic modality detection in the legal domain.
DistillAdapt: Source-Free Active Visual Domain Adaptation
May 24, 2022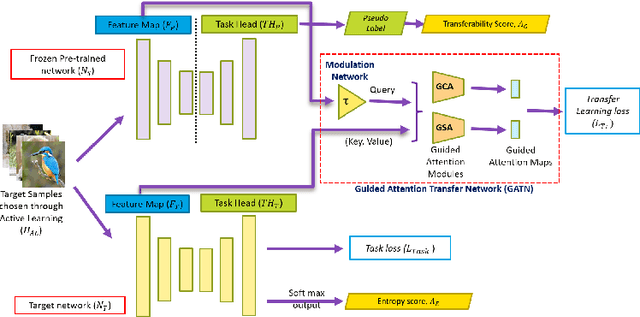

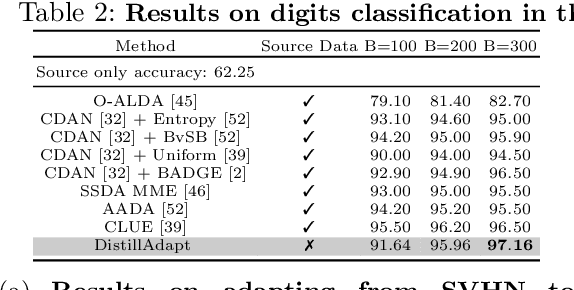
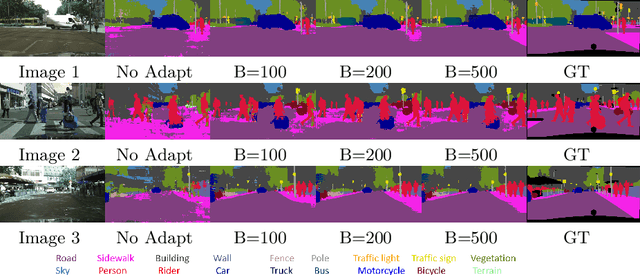
We present a novel method, DistillAdapt, for the challenging problem of Source-Free Active Domain Adaptation (SF-ADA). The problem requires adapting a pretrained source domain network to a target domain, within a provided budget for acquiring labels in the target domain, while assuming that the source data is not available for adaptation due to privacy concerns or otherwise. DistillAdapt is one of the first approaches for SF-ADA, and holistically addresses the challenges of SF-ADA via a novel Guided Attention Transfer Network (GATN) and an active learning heuristic, H_AL. The GATN enables selective distillation of features from the pre-trained network to the target network using a small subset of annotated target samples mined by H_AL. H_AL acquires samples at batch-level and balances transfer-ability from the pre-trained network and uncertainty of the target network. DistillAdapt is task-agnostic, and can be applied across visual tasks such as classification, segmentation and detection. Moreover, DistillAdapt can handle shifts in output label space. We conduct experiments and extensive ablation studies across 3 visual tasks, viz. digits classification (MNIST, SVHN), synthetic (GTA5) to real (CityScapes) image segmentation, and document layout detection (PubLayNet to DSSE). We show that our source-free approach, DistillAdapt, results in an improvement of 0.5% - 31.3% (across datasets and tasks) over prior adaptation methods that assume access to large amounts of annotated source data for adaptation.
Entailment Relation Aware Paraphrase Generation
Mar 20, 2022


We introduce a new task of entailment relation aware paraphrase generation which aims at generating a paraphrase conforming to a given entailment relation (e.g. equivalent, forward entailing, or reverse entailing) with respect to a given input. We propose a reinforcement learning-based weakly-supervised paraphrasing system, ERAP, that can be trained using existing paraphrase and natural language inference (NLI) corpora without an explicit task-specific corpus. A combination of automated and human evaluations show that ERAP generates paraphrases conforming to the specified entailment relation and are of good quality as compared to the baselines and uncontrolled paraphrasing systems. Using ERAP for augmenting training data for downstream textual entailment task improves performance over an uncontrolled paraphrasing system, and introduces fewer training artifacts, indicating the benefit of explicit control during paraphrasing.
What do Large Language Models Learn about Scripts?
Dec 27, 2021

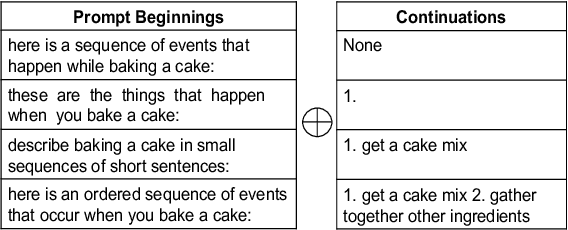
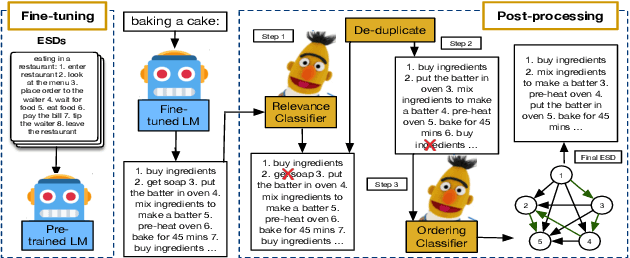
Script Knowledge (Schank and Abelson, 1975) has long been recognized as crucial for language understanding as it can help in filling in unstated information in a narrative. However, such knowledge is expensive to produce manually and difficult to induce from text due to reporting bias (Gordon and Van Durme, 2013). In this work, we are interested in the scientific question of whether explicit script knowledge is present and accessible through pre-trained generative language models (LMs). To this end, we introduce the task of generating full event sequence descriptions (ESDs) given a scenario in the form of natural language prompts. In zero-shot probing experiments, we find that generative LMs produce poor ESDs with mostly omitted, irrelevant, repeated or misordered events. To address this, we propose a pipeline-based script induction framework (SIF) which can generate good quality ESDs for unseen scenarios (e.g., bake a cake). SIF is a two-staged framework that fine-tunes LM on a small set of ESD examples in the first stage. In the second stage, ESD generated for an unseen scenario is post-processed using RoBERTa-based models to filter irrelevant events, remove repetitions, and reorder the temporally misordered events. Through automatic and manual evaluations, we demonstrate that SIF yields substantial improvements ($1$-$3$ BLUE points) over a fine-tuned LM. However, manual analysis shows that there is great room for improvement, offering a new research direction for inducing script knowledge.
Goal-driven Command Recommendations for Analysts
Nov 12, 2020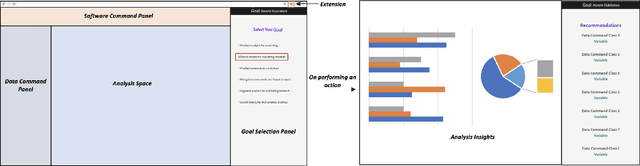
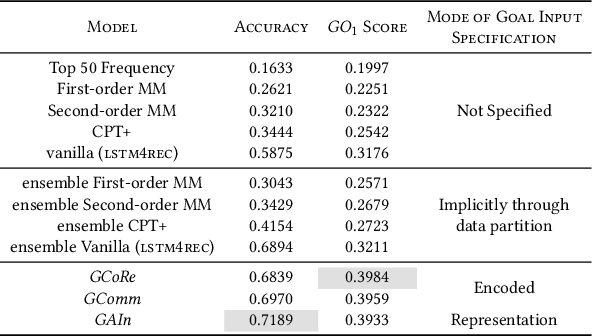
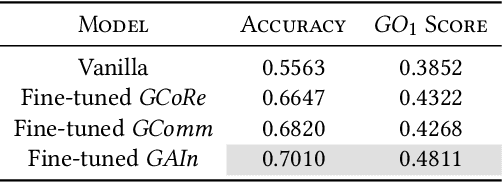
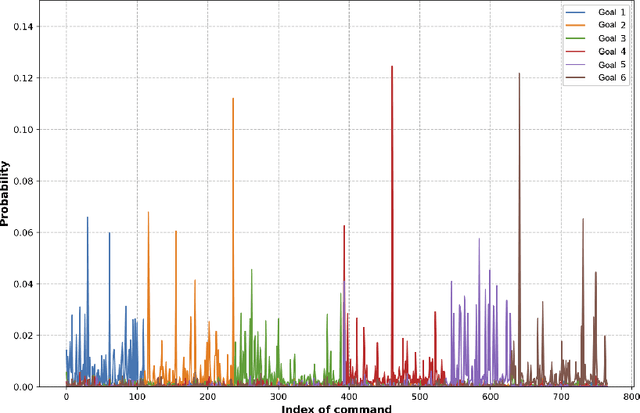
Recent times have seen data analytics software applications become an integral part of the decision-making process of analysts. The users of these software applications generate a vast amount of unstructured log data. These logs contain clues to the user's goals, which traditional recommender systems may find difficult to model implicitly from the log data. With this assumption, we would like to assist the analytics process of a user through command recommendations. We categorize the commands into software and data categories based on their purpose to fulfill the task at hand. On the premise that the sequence of commands leading up to a data command is a good predictor of the latter, we design, develop, and validate various sequence modeling techniques. In this paper, we propose a framework to provide goal-driven data command recommendations to the user by leveraging unstructured logs. We use the log data of a web-based analytics software to train our neural network models and quantify their performance, in comparison to relevant and competitive baselines. We propose a custom loss function to tailor the recommended data commands according to the goal information provided exogenously. We also propose an evaluation metric that captures the degree of goal orientation of the recommendations. We demonstrate the promise of our approach by evaluating the models with the proposed metric and showcasing the robustness of our models in the case of adversarial examples, where the user activity is misaligned with selected goal, through offline evaluation.