 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Rewriting Approaches for Different Conversational Tasks
Feb 26, 2025



Conversational assistants often require a question rewriting algorithm that leverages a subset of past interactions to provide a more meaningful (accurate) answer to the user's question or request. However, the exact rewriting approach may often depend on the use case and application-specific tasks supported by the conversational assistant, among other constraints. In this paper, we systematically investigate two different approaches, denoted as rewriting and fusion, on two fundamentally different generation tasks, including a text-to-text generation task and a multimodal generative task that takes as input text and generates a visualization or data table that answers the user's question. Our results indicate that the specific rewriting or fusion approach highly depends on the underlying use case and generative task. In particular, we find that for a conversational question-answering assistant, the query rewriting approach performs best, whereas for a data analysis assistant that generates visualizations and data tables based on the user's conversation with the assistant, the fusion approach works best. Notably, we explore two datasets for the data analysis assistant use case, for short and long conversations, and we find that query fusion always performs better, whereas for the conversational text-based question-answering, the query rewrite approach performs best.
PersonaSAGE: A Multi-Persona Graph Neural Network
Dec 28, 2022



Graph Neural Networks (GNNs) have become increasingly important in recent years due to their state-of-the-art performance on many important downstream applications. Existing GNNs have mostly focused on learning a single node representation, despite that a node often exhibits polysemous behavior in different contexts. In this work, we develop a persona-based graph neural network framework called PersonaSAGE that learns multiple persona-based embeddings for each node in the graph. Such disentangled representations are more interpretable and useful than a single embedding. Furthermore, PersonaSAGE learns the appropriate set of persona embeddings for each node in the graph, and every node can have a different number of assigned persona embeddings. The framework is flexible enough and the general design helps in the wide applicability of the learned embeddings to suit the domain. We utilize publicly available benchmark datasets to evaluate our approach and against a variety of baselines. The experiments demonstrate the effectiveness of PersonaSAGE for a variety of important tasks including link prediction where we achieve an average gain of 15% while remaining competitive for node classification. Finally, we also demonstrate the utility of PersonaSAGE with a case study for personalized recommendation of different entity types in a data management platform.
CGC: Contrastive Graph Clustering for Community Detection and Tracking
Apr 05, 2022
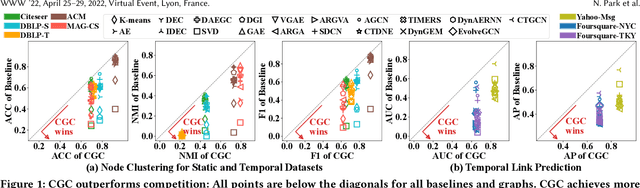
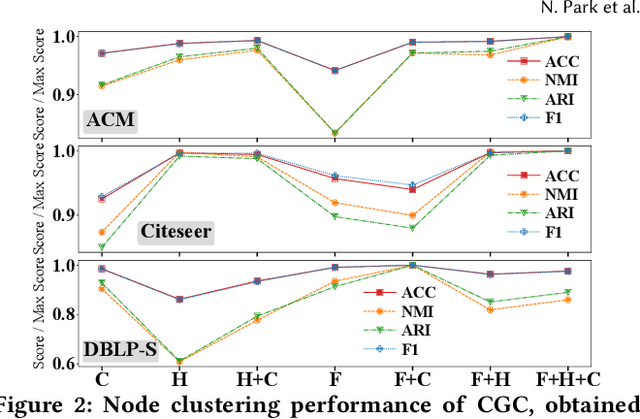
Given entities and their interactions in the web data, which may have occurred at different time, how can we find communities of entities and track their evolution? In this paper, we approach this important task from graph clustering perspective. Recently, state-of-the-art clustering performance in various domains has been achieved by deep clustering methods. Especially, deep graph clustering (DGC) methods have successfully extended deep clustering to graph-structured data by learning node representations and cluster assignments in a joint optimization framework. Despite some differences in modeling choices (e.g., encoder architectures), existing DGC methods are mainly based on autoencoders and use the same clustering objective with relatively minor adaptations. Also, while many real-world graphs are dynamic, previous DGC methods considered only static graphs. In this work, we develop CGC, a novel end-to-end framework for graph clustering, which fundamentally differs from existing methods. CGC learns node embeddings and cluster assignments in a contrastive graph learning framework, where positive and negative samples are carefully selected in a multi-level scheme such that they reflect hierarchical community structures and network homophily. Also, we extend CGC for time-evolving data, where temporal graph clustering is performed in an incremental learning fashion, with the ability to detect change points. Extensive evaluation on real-world graphs demonstrates that the proposed CGC consistently outperforms existing methods.
Goal-driven Command Recommendations for Analysts
Nov 12, 2020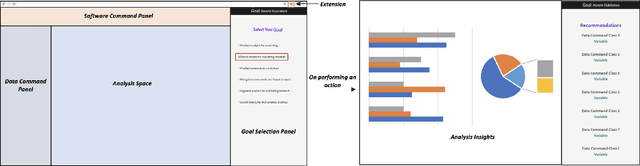
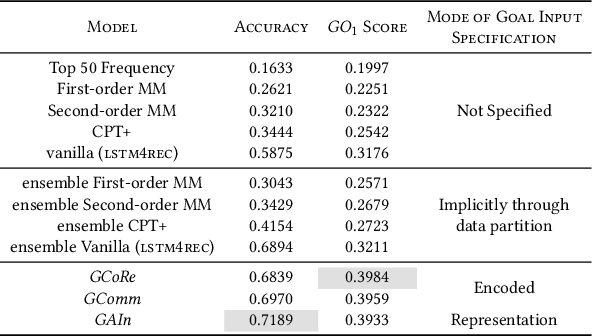
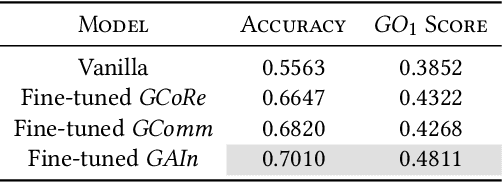
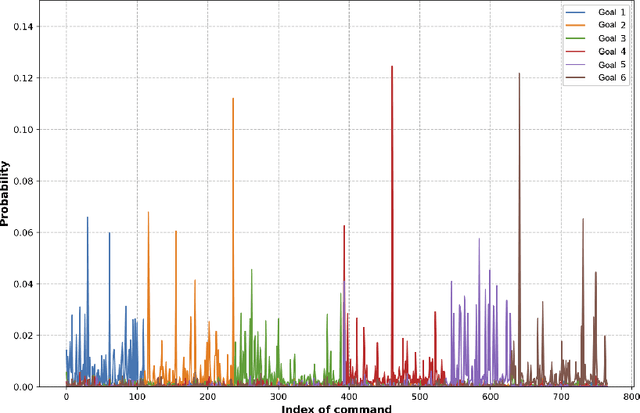
Recent times have seen data analytics software applications become an integral part of the decision-making process of analysts. The users of these software applications generate a vast amount of unstructured log data. These logs contain clues to the user's goals, which traditional recommender systems may find difficult to model implicitly from the log data. With this assumption, we would like to assist the analytics process of a user through command recommendations. We categorize the commands into software and data categories based on their purpose to fulfill the task at hand. On the premise that the sequence of commands leading up to a data command is a good predictor of the latter, we design, develop, and validate various sequence modeling techniques. In this paper, we propose a framework to provide goal-driven data command recommendations to the user by leveraging unstructured logs. We use the log data of a web-based analytics software to train our neural network models and quantify their performance, in comparison to relevant and competitive baselines. We propose a custom loss function to tailor the recommended data commands according to the goal information provided exogenously. We also propose an evaluation metric that captures the degree of goal orientation of the recommendations. We demonstrate the promise of our approach by evaluating the models with the proposed metric and showcasing the robustness of our models in the case of adversarial examples, where the user activity is misaligned with selected goal, through offline evaluation.
Online Diverse Learning to Rank from Partial-Click Feedback
Nov 01, 2018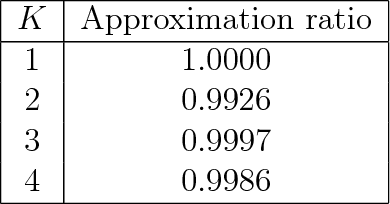
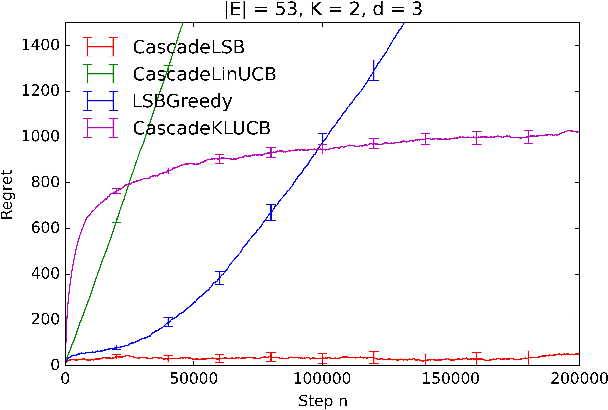
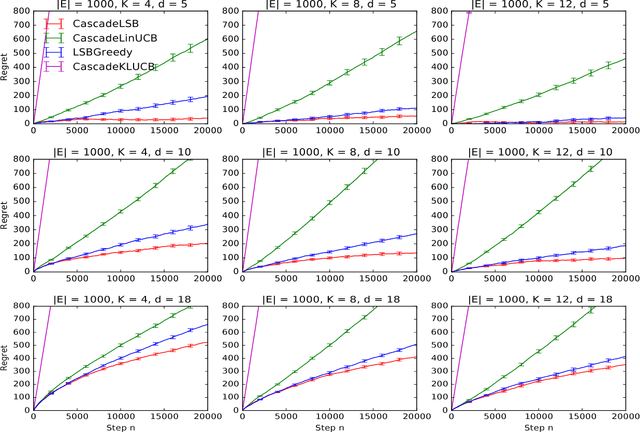
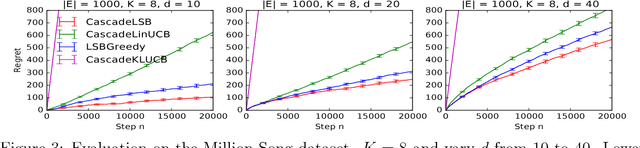
Learning to rank is an important problem in machine learning and recommender systems. In a recommender system, a user is typically recommended a list of items. Since the user is unlikely to examine the entire recommended list, partial feedback arises naturally. At the same time, diverse recommendations are important because it is challenging to model all tastes of the user in practice. In this paper, we propose the first algorithm for online learning to rank diverse items from partial-click feedback. We assume that the user examines the list of recommended items until the user is attracted by an item, which is clicked, and does not examine the rest of the items. This model of user behavior is known as the cascade model. We propose an online learning algorithm, cascadelsb, for solving our problem. The algorithm actively explores the tastes of the user with the objective of learning to recommend the optimal diverse list. We analyze the algorithm and prove a gap-free upper bound on its n-step regret. We evaluate cascadelsb on both synthetic and real-world datasets, compare it to various baselines, and show that it learns even when our modeling assumptions do not hold exactly.