 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Low-Latency Vision-Language Models with Doubly-Correct Predictions in Egocentric Visual Understanding
Jun 23, 2026The rapid rise of Vision-Language Models (VLMs) in egocentric visual understanding has made low-latency inference in human-robot collaborative (HRC) tasks increasingly critical. Weight pruning techniques developed for VLMs to shrink model size and computation can be readily applied to satisfy the efficiency demands of on-board processing and real-time interactive robotics. Moreover, safe human-robot interaction demands pruning strategies that preserve doubly-correct predictions; outputs must be both accurate and evidentially grounded to mitigate risks and ensure user trust. In this paper, we present a new study of VLM pruning through the lens of doubly-correct prediction. Our experiments surprisingly show that existing pruning methods often preserve the right evidence localization but undermine correct prediction. To address this, we propose a rationale-informed pruning strategy that better aligns evidence with decisions. Benchmark results on egocentric video datasets demonstrate that our method not only achieves the highest prediction accuracy but also outperforms existing approaches in attaining doubly-correct predictions. We aim to stimulate research on efficient and reliable VLMs, ensuring accuracy-driven advances align with the transparency, auditability, and safety required for responsible human-robot interaction and embodied intelligence.
APT: Atomic Physical Transitions for Causal Video-Language Understanding
Jun 17, 2026Physical events are not understood by their names alone, but by the causal state changes that compose them. A clip-level label such as "bounce" can be correct while hiding the process that makes the event physically valid, from support loss and contact onset to rebound and settling. To make this hidden process explicit, we introduce Atomic Physical Transitions (APTs): minimal, temporally localized state changes that bind a visible cue to an active physical mechanism and before/after dynamical regimes. An APT chain represents a video as an ordered causal transition sequence rather than a single aggregate event label: event labels tell what happened; APT chains explain why it happened. To make APTs learnable by VLMs, we construct mixed-source APT data from human annotations and simulator ground truth, covering 14 transition types across contact, gravity, friction, and rotation/stability, with 27,303 timed instances over 1,246 trials. Using this data, we find that current VLMs miss transition-level physics, with zero-shot recall at most 14% and errors dominated by missed transitions. Direct fine-tuning on APT chains improves transition detection but causes event-level forgetting, indicating that the model learns a specialized answer format rather than a reusable physical representation. We therefore propose APT-Tune, a parameter-efficient recipe that teaches VLMs to use causal transitions without forgetting how to answer video questions. It combines image-pad-aware supervision, format-conditional co-training, and mechanism-conditioned domain-to-type decoding to make APT learning format-robust and physically grounded. With only 11 M LoRA parameters on Qwen3-VL-2B, APT-Tune substantially improves APT recall while also improving event-level video transfer. These results show that APTs are not a new answer format, but a human-aligned causal supervision signal for physical video understanding.
CF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
Apr 28, 2026Flow-based vision-language-action (VLA) policies offer strong expressivity for action generation, but suffer from a fundamental inefficiency: multi-step inference is required to recover action structure from uninformative Gaussian noise, leading to a poor efficiency-quality trade-off under real-time constraints. We address this issue by rethinking the role of the starting point in generative action modeling. Instead of shortening the sampling trajectory, we propose CF-VLA, a coarse-to-fine two-stage formulation that restructures action generation into a coarse initialization step that constructs an action-aware starting point, followed by a single-step local refinement that corrects residual errors. Concretely, the coarse stage learns a conditional posterior over endpoint velocity to transform Gaussian noise into a structured initialization, while the fine stage performs a fixed-time refinement from this initialization. To stabilize training, we introduce a stepwise strategy that first learns a controlled coarse predictor and then performs joint optimization. Experiments on CALVIN and LIBERO show that our method establishes a strong efficiency-performance frontier under low-NFE (Number of Function Evaluations) regimes: it consistently outperforms existing NFE=2 methods, matches or surpasses the NFE=10 $π_{0.5}$ baseline on several metrics, reduces action sampling latency by 75.4%, and achieves the best average real-robot success rate of 83.0%, outperforming MIP by 19.5 points and $π_{0.5}$ by 4.0 points. These results suggest that structured, coarse-to-fine generation enables both strong performance and efficient inference. Our code is available at https://github.com/EmbodiedAI-RoboTron/CF-VLA.
PhyPrompt: RL-based Prompt Refinement for Physically Plausible Text-to-Video Generation
Mar 03, 2026State-of-the-art text-to-video (T2V) generators frequently violate physical laws despite high visual quality. We show this stems from insufficient physical constraints in prompts rather than model limitations: manually adding physics details reliably produces physically plausible videos, but requires expertise and does not scale. We present PhyPrompt, a two-stage reinforcement learning framework that automatically refines prompts for physically realistic generation. First, we fine-tune a large language model on a physics-focused Chain-of-Thought dataset to integrate principles like object motion and force interactions while preserving user intent. Second, we apply Group Relative Policy Optimization with a dynamic reward curriculum that initially prioritizes semantic fidelity, then progressively shifts toward physical commonsense. This curriculum achieves synergistic optimization: PhyPrompt-7B reaches 40.8\% joint success on VideoPhy2 (8.6pp gain), improving physical commonsense by 11pp (55.8\% to 66.8\%) while simultaneously increasing semantic adherence by 4.4pp (43.4\% to 47.8\%). Remarkably, our curriculum exceeds single-objective training on both metrics, demonstrating compositional prompt discovery beyond conventional multi-objective trade-offs. PhyPrompt outperforms GPT-4o (+3.8\% joint) and DeepSeek-V3 (+2.2\%, 100$\times$ larger) using only 7B parameters. The approach transfers zero-shot across diverse T2V architectures (Lavie, VideoCrafter2, CogVideoX-5B) with up to 16.8\% improvement, establishing that domain-specialized reinforcement learning with compositional curricula surpasses general-purpose scaling for physics-aware generation.
Phys4D: Fine-Grained Physics-Consistent 4D Modeling from Video Diffusion
Mar 03, 2026Recent video diffusion models have achieved impressive capabilities as large-scale generative world models. However, these models often struggle with fine-grained physical consistency, exhibiting physically implausible dynamics over time. In this work, we present \textbf{Phys4D}, a pipeline for learning physics-consistent 4D world representations from video diffusion models. Phys4D adopts \textbf{a three-stage training paradigm} that progressively lifts appearance-driven video diffusion models into physics-consistent 4D world representations. We first bootstrap robust geometry and motion representations through large-scale pseudo-supervised pretraining, establishing a foundation for 4D scene modeling. We then perform physics-grounded supervised fine-tuning using simulation-generated data, enforcing temporally consistent 4D dynamics. Finally, we apply simulation-grounded reinforcement learning to correct residual physical violations that are difficult to capture through explicit supervision. To evaluate fine-grained physical consistency beyond appearance-based metrics, we introduce a set of \textbf{4D world consistency evaluation} that probe geometric coherence, motion stability, and long-horizon physical plausibility. Experimental results demonstrate that Phys4D substantially improves fine-grained spatiotemporal and physical consistency compared to appearance-driven baselines, while maintaining strong generative performance. Our project page is available at https://sensational-brioche-7657e7.netlify.app/
Towards Sparse Video Understanding and Reasoning
Feb 14, 2026We present \revise (\underline{Re}asoning with \underline{Vi}deo \underline{S}parsity), a multi-round agent for video question answering (VQA). Instead of uniformly sampling frames, \revise selects a small set of informative frames, maintains a summary-as-state across rounds, and stops early when confident. It supports proprietary vision-language models (VLMs) in a ``plug-and-play'' setting and enables reinforcement fine-tuning for open-source models. For fine-tuning, we introduce EAGER (Evidence-Adjusted Gain for Efficient Reasoning), an annotation-free reward with three terms: (1) Confidence gain: after new frames are added, we reward the increase in the log-odds gap between the correct option and the strongest alternative; (2) Summary sufficiency: at answer time we re-ask using only the last committed summary and reward success; (3) Correct-and-early stop: answering correctly within a small turn budget is rewarded. Across multiple VQA benchmarks, \revise improves accuracy while reducing frames, rounds, and prompt tokens, demonstrating practical sparse video reasoning.
DPAR: Dynamic Patchification for Efficient Autoregressive Visual Generation
Dec 26, 2025Decoder-only autoregressive image generation typically relies on fixed-length tokenization schemes whose token counts grow quadratically with resolution, substantially increasing the computational and memory demands of attention. We present DPAR, a novel decoder-only autoregressive model that dynamically aggregates image tokens into a variable number of patches for efficient image generation. Our work is the first to demonstrate that next-token prediction entropy from a lightweight and unsupervised autoregressive model provides a reliable criterion for merging tokens into larger patches based on information content. DPAR makes minimal modifications to the standard decoder architecture, ensuring compatibility with multimodal generation frameworks and allocating more compute to generation of high-information image regions. Further, we demonstrate that training with dynamically sized patches yields representations that are robust to patch boundaries, allowing DPAR to scale to larger patch sizes at inference. DPAR reduces token count by 1.81x and 2.06x on Imagenet 256 and 384 generation resolution respectively, leading to a reduction of up to 40% FLOPs in training costs. Further, our method exhibits faster convergence and improves FID by up to 27.1% relative to baseline models.
PersonaSAGE: A Multi-Persona Graph Neural Network
Dec 28, 2022



Graph Neural Networks (GNNs) have become increasingly important in recent years due to their state-of-the-art performance on many important downstream applications. Existing GNNs have mostly focused on learning a single node representation, despite that a node often exhibits polysemous behavior in different contexts. In this work, we develop a persona-based graph neural network framework called PersonaSAGE that learns multiple persona-based embeddings for each node in the graph. Such disentangled representations are more interpretable and useful than a single embedding. Furthermore, PersonaSAGE learns the appropriate set of persona embeddings for each node in the graph, and every node can have a different number of assigned persona embeddings. The framework is flexible enough and the general design helps in the wide applicability of the learned embeddings to suit the domain. We utilize publicly available benchmark datasets to evaluate our approach and against a variety of baselines. The experiments demonstrate the effectiveness of PersonaSAGE for a variety of important tasks including link prediction where we achieve an average gain of 15% while remaining competitive for node classification. Finally, we also demonstrate the utility of PersonaSAGE with a case study for personalized recommendation of different entity types in a data management platform.
Bundle MCR: Towards Conversational Bundle Recommendation
Jul 26, 2022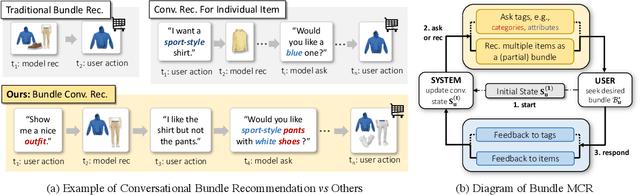

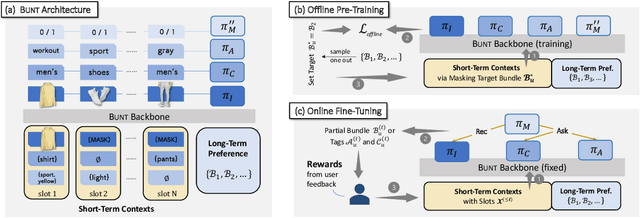

Bundle recommender systems recommend sets of items (e.g., pants, shirt, and shoes) to users, but they often suffer from two issues: significant interaction sparsity and a large output space. In this work, we extend multi-round conversational recommendation (MCR) to alleviate these issues. MCR, which uses a conversational paradigm to elicit user interests by asking user preferences on tags (e.g., categories or attributes) and handling user feedback across multiple rounds, is an emerging recommendation setting to acquire user feedback and narrow down the output space, but has not been explored in the context of bundle recommendation. In this work, we propose a novel recommendation task named Bundle MCR. We first propose a new framework to formulate Bundle MCR as Markov Decision Processes (MDPs) with multiple agents, for user modeling, consultation and feedback handling in bundle contexts. Under this framework, we propose a model architecture, called Bundle Bert (Bunt) to (1) recommend items, (2) post questions and (3) manage conversations based on bundle-aware conversation states. Moreover, to train Bunt effectively, we propose a two-stage training strategy. In an offline pre-training stage, Bunt is trained using multiple cloze tasks to mimic bundle interactions in conversations. Then in an online fine-tuning stage, Bunt agents are enhanced by user interactions. Our experiments on multiple offline datasets as well as the human evaluation show the value of extending MCR frameworks to bundle settings and the effectiveness of our Bunt design.
CGC: Contrastive Graph Clustering for Community Detection and Tracking
Apr 05, 2022
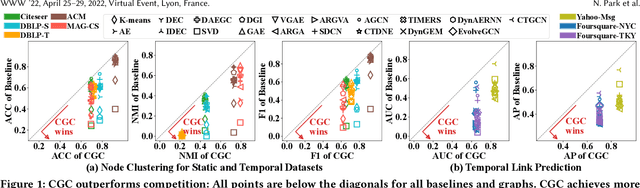
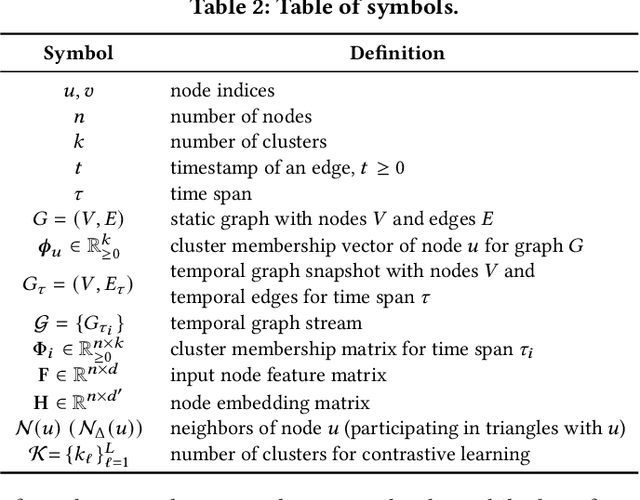
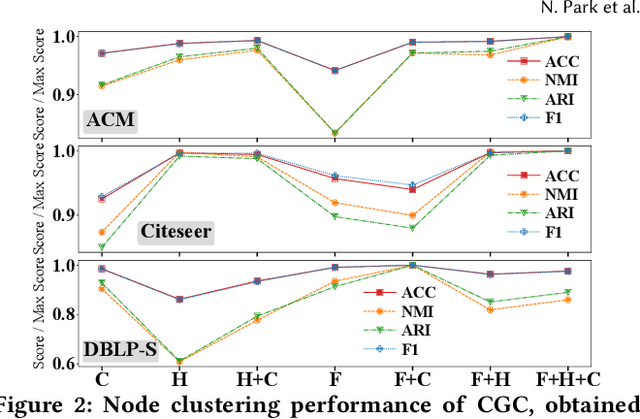
Given entities and their interactions in the web data, which may have occurred at different time, how can we find communities of entities and track their evolution? In this paper, we approach this important task from graph clustering perspective. Recently, state-of-the-art clustering performance in various domains has been achieved by deep clustering methods. Especially, deep graph clustering (DGC) methods have successfully extended deep clustering to graph-structured data by learning node representations and cluster assignments in a joint optimization framework. Despite some differences in modeling choices (e.g., encoder architectures), existing DGC methods are mainly based on autoencoders and use the same clustering objective with relatively minor adaptations. Also, while many real-world graphs are dynamic, previous DGC methods considered only static graphs. In this work, we develop CGC, a novel end-to-end framework for graph clustering, which fundamentally differs from existing methods. CGC learns node embeddings and cluster assignments in a contrastive graph learning framework, where positive and negative samples are carefully selected in a multi-level scheme such that they reflect hierarchical community structures and network homophily. Also, we extend CGC for time-evolving data, where temporal graph clustering is performed in an incremental learning fashion, with the ability to detect change points. Extensive evaluation on real-world graphs demonstrates that the proposed CGC consistently outperforms existing methods.