 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCENTS: Generating synthetic electricity consumption time series for rare and unseen scenarios
Jan 27, 2025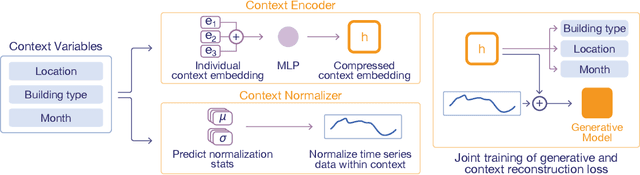

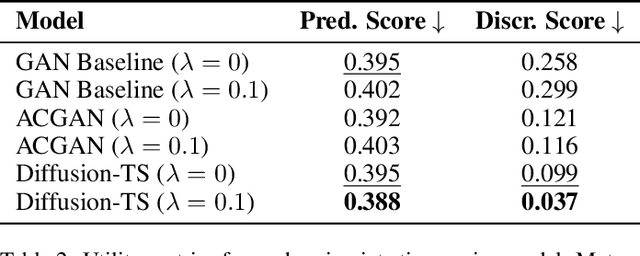
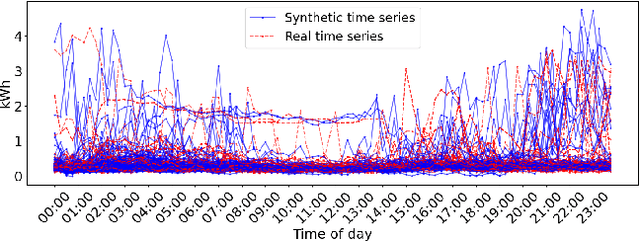
Recent breakthroughs in large-scale generative modeling have demonstrated the potential of foundation models in domains such as natural language, computer vision, and protein structure prediction. However, their application in the energy and smart grid sector remains limited due to the scarcity and heterogeneity of high-quality data. In this work, we propose a method for creating high-fidelity electricity consumption time series data for rare and unseen context variables (e.g. location, building type, photovoltaics). Our approach, Context Encoding and Normalizing Time Series Generation, or CENTS, includes three key innovations: (i) A context normalization approach that enables inverse transformation for time series context variables unseen during training, (ii) a novel context encoder to condition any state-of-the-art time-series generator on arbitrary numbers and combinations of context variables, (iii) a framework for training this context encoder jointly with a time-series generator using an auxiliary context classification loss designed to increase expressivity of context embeddings and improve model performance. We further provide a comprehensive overview of different evaluation metrics for generative time series models. Our results highlight the efficacy of the proposed method in generating realistic household-level electricity consumption data, paving the way for training larger foundation models in the energy domain on synthetic as well as real-world data.
Explingo: Explaining AI Predictions using Large Language Models
Dec 06, 2024



Explanations of machine learning (ML) model predictions generated by Explainable AI (XAI) techniques such as SHAP are essential for people using ML outputs for decision-making. We explore the potential of Large Language Models (LLMs) to transform these explanations into human-readable, narrative formats that align with natural communication. We address two key research questions: (1) Can LLMs reliably transform traditional explanations into high-quality narratives? and (2) How can we effectively evaluate the quality of narrative explanations? To answer these questions, we introduce Explingo, which consists of two LLM-based subsystems, a Narrator and Grader. The Narrator takes in ML explanations and transforms them into natural-language descriptions. The Grader scores these narratives on a set of metrics including accuracy, completeness, fluency, and conciseness. Our experiments demonstrate that LLMs can generate high-quality narratives that achieve high scores across all metrics, particularly when guided by a small number of human-labeled and bootstrapped examples. We also identified areas that remain challenging, in particular for effectively scoring narratives in complex domains. The findings from this work have been integrated into an open-source tool that makes narrative explanations available for further applications.
Large language models can be zero-shot anomaly detectors for time series?
May 23, 2024



Recent studies have shown the ability of large language models to perform a variety of tasks, including time series forecasting. The flexible nature of these models allows them to be used for many applications. In this paper, we present a novel study of large language models used for the challenging task of time series anomaly detection. This problem entails two aspects novel for LLMs: the need for the model to identify part of the input sequence (or multiple parts) as anomalous; and the need for it to work with time series data rather than the traditional text input. We introduce sigllm, a framework for time series anomaly detection using large language models. Our framework includes a time-series-to-text conversion module, as well as end-to-end pipelines that prompt language models to perform time series anomaly detection. We investigate two paradigms for testing the abilities of large language models to perform the detection task. First, we present a prompt-based detection method that directly asks a language model to indicate which elements of the input are anomalies. Second, we leverage the forecasting capability of a large language model to guide the anomaly detection process. We evaluated our framework on 11 datasets spanning various sources and 10 pipelines. We show that the forecasting method significantly outperformed the prompting method in all 11 datasets with respect to the F1 score. Moreover, while large language models are capable of finding anomalies, state-of-the-art deep learning models are still superior in performance, achieving results 30% better than large language models.
LLMs for XAI: Future Directions for Explaining Explanations
May 09, 2024In response to the demand for Explainable Artificial Intelligence (XAI), we investigate the use of Large Language Models (LLMs) to transform ML explanations into natural, human-readable narratives. Rather than directly explaining ML models using LLMs, we focus on refining explanations computed using existing XAI algorithms. We outline several research directions, including defining evaluation metrics, prompt design, comparing LLM models, exploring further training methods, and integrating external data. Initial experiments and user study suggest that LLMs offer a promising way to enhance the interpretability and usability of XAI.
Single Word Change is All You Need: Designing Attacks and Defenses for Text Classifiers
Jan 30, 2024In text classification, creating an adversarial example means subtly perturbing a few words in a sentence without changing its meaning, causing it to be misclassified by a classifier. A concerning observation is that a significant portion of adversarial examples generated by existing methods change only one word. This single-word perturbation vulnerability represents a significant weakness in classifiers, which malicious users can exploit to efficiently create a multitude of adversarial examples. This paper studies this problem and makes the following key contributions: (1) We introduce a novel metric \r{ho} to quantitatively assess a classifier's robustness against single-word perturbation. (2) We present the SP-Attack, designed to exploit the single-word perturbation vulnerability, achieving a higher attack success rate, better preserving sentence meaning, while reducing computation costs compared to state-of-the-art adversarial methods. (3) We propose SP-Defense, which aims to improve \r{ho} by applying data augmentation in learning. Experimental results on 4 datasets and BERT and distilBERT classifiers show that SP-Defense improves \r{ho} by 14.6% and 13.9% and decreases the attack success rate of SP-Attack by 30.4% and 21.2% on two classifiers respectively, and decreases the attack success rate of existing attack methods that involve multiple-word perturbations.
Pyreal: A Framework for Interpretable ML Explanations
Dec 20, 2023Users in many domains use machine learning (ML) predictions to help them make decisions. Effective ML-based decision-making often requires explanations of ML models and their predictions. While there are many algorithms that explain models, generating explanations in a format that is comprehensible and useful to decision-makers is a nontrivial task that can require extensive development overhead. We developed Pyreal, a highly extensible system with a corresponding Python implementation for generating a variety of interpretable ML explanations. Pyreal converts data and explanations between the feature spaces expected by the model, relevant explanation algorithms, and human users, allowing users to generate interpretable explanations in a low-code manner. Our studies demonstrate that Pyreal generates more useful explanations than existing systems while remaining both easy-to-use and efficient.
Lessons from Usable ML Deployments and Application to Wind Turbine Monitoring
Dec 05, 2023Through past experiences deploying what we call usable ML (one step beyond explainable ML, including both explanations and other augmenting information) to real-world domains, we have learned three key lessons. First, many organizations are beginning to hire people who we call ``bridges'' because they bridge the gap between ML developers and domain experts, and these people fill a valuable role in developing usable ML applications. Second, a configurable system that enables easily iterating on usable ML interfaces during collaborations with bridges is key. Finally, there is a need for continuous, in-deployment evaluations to quantify the real-world impact of usable ML. Throughout this paper, we apply these lessons to the task of wind turbine monitoring, an essential task in the renewable energy domain. Turbine engineers and data analysts must decide whether to perform costly in-person investigations on turbines to prevent potential cases of brakepad failure, and well-tuned usable ML interfaces can aid with this decision-making process. Through the applications of our lessons to this task, we hope to demonstrate the potential real-world impact of usable ML in the renewable energy domain.
Making the End-User a Priority in Benchmarking: OrionBench for Unsupervised Time Series Anomaly Detection
Oct 26, 2023Time series anomaly detection is a prevalent problem in many application domains such as patient monitoring in healthcare, forecasting in finance, or predictive maintenance in energy. This has led to the emergence of a plethora of anomaly detection methods, including more recently, deep learning based methods. Although several benchmarks have been proposed to compare newly developed models, they usually rely on one-time execution over a limited set of datasets and the comparison is restricted to a few models. We propose OrionBench -- a user centric continuously maintained benchmark for unsupervised time series anomaly detection. The framework provides universal abstractions to represent models, extensibility to add new pipelines and datasets, hyperparameter standardization, pipeline verification, and frequent releases with published benchmarks. We demonstrate the usage of OrionBench, and the progression of pipelines across 15 releases published over the course of three years. Moreover, we walk through two real scenarios we experienced with OrionBench that highlight the importance of continuous benchmarks in unsupervised time series anomaly detection.
AER: Auto-Encoder with Regression for Time Series Anomaly Detection
Dec 27, 2022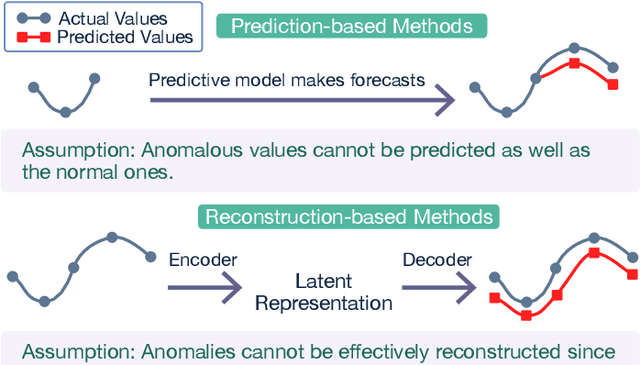
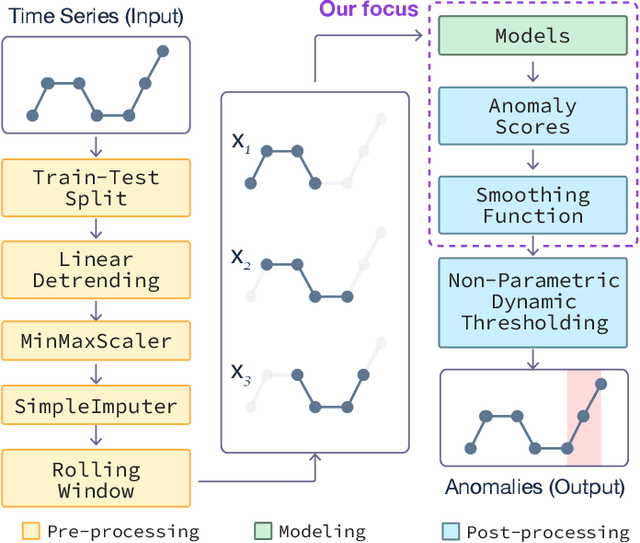
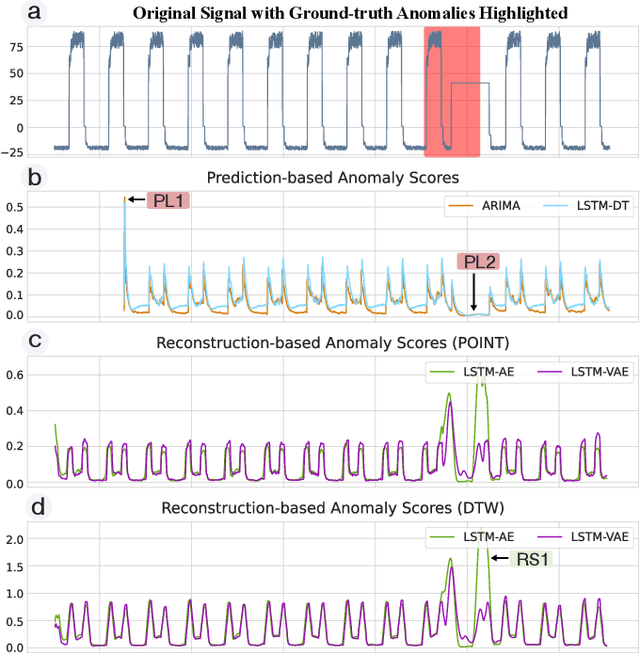
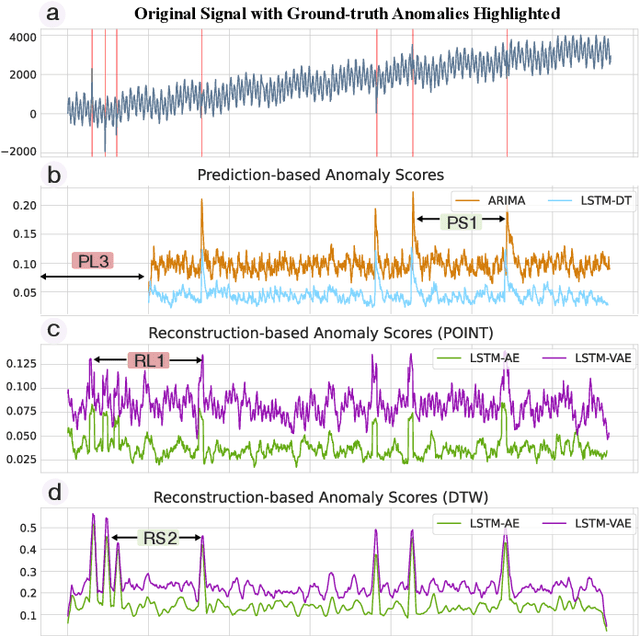
Anomaly detection on time series data is increasingly common across various industrial domains that monitor metrics in order to prevent potential accidents and economic losses. However, a scarcity of labeled data and ambiguous definitions of anomalies can complicate these efforts. Recent unsupervised machine learning methods have made remarkable progress in tackling this problem using either single-timestamp predictions or time series reconstructions. While traditionally considered separately, these methods are not mutually exclusive and can offer complementary perspectives on anomaly detection. This paper first highlights the successes and limitations of prediction-based and reconstruction-based methods with visualized time series signals and anomaly scores. We then propose AER (Auto-encoder with Regression), a joint model that combines a vanilla auto-encoder and an LSTM regressor to incorporate the successes and address the limitations of each method. Our model can produce bi-directional predictions while simultaneously reconstructing the original time series by optimizing a joint objective function. Furthermore, we propose several ways of combining the prediction and reconstruction errors through a series of ablation studies. Finally, we compare the performance of the AER architecture against two prediction-based methods and three reconstruction-based methods on 12 well-known univariate time series datasets from NASA, Yahoo, Numenta, and UCR. The results show that AER has the highest averaged F1 score across all datasets (a 23.5% improvement compared to ARIMA) while retaining a runtime similar to its vanilla auto-encoder and regressor components. Our model is available in Orion, an open-source benchmarking tool for time series anomaly detection.
Sequential Models in the Synthetic Data Vault
Jul 28, 2022

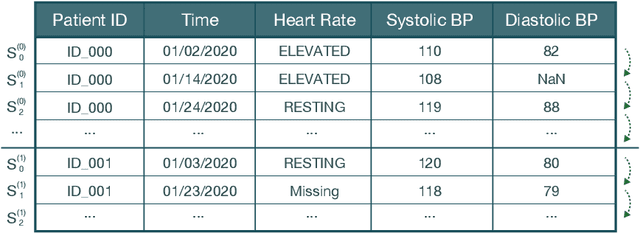
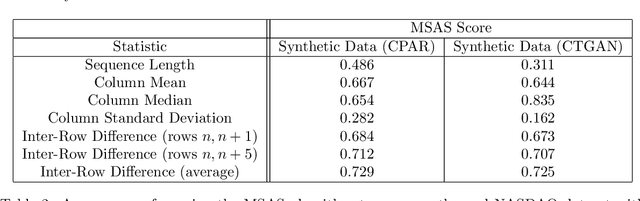
The goal of this paper is to describe a system for generating synthetic sequential data within the Synthetic data vault. To achieve this, we present the Sequential model currently in SDV, an end-to-end framework that builds a generative model for multi-sequence, real-world data. This includes a novel neural network-based machine learning model, conditional probabilistic auto-regressive (CPAR) model. The overall system and the model is available in the open source Synthetic Data Vault (SDV) library {https://github.com/sdv-dev/SDV}, along with a variety of other models for different synthetic data needs. After building the Sequential SDV, we used it to generate synthetic data and compared its quality against an existing, non-sequential generative adversarial network based model called CTGAN. To compare the sequential synthetic data against its real counterpart, we invented a new metric called Multi-Sequence Aggregate Similarity (MSAS). We used it to conclude that our Sequential SDV model learns higher level patterns than non-sequential models without any trade-offs in synthetic data quality.