 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Word Change is All You Need: Designing Attacks and Defenses for Text Classifiers
Jan 30, 2024In text classification, creating an adversarial example means subtly perturbing a few words in a sentence without changing its meaning, causing it to be misclassified by a classifier. A concerning observation is that a significant portion of adversarial examples generated by existing methods change only one word. This single-word perturbation vulnerability represents a significant weakness in classifiers, which malicious users can exploit to efficiently create a multitude of adversarial examples. This paper studies this problem and makes the following key contributions: (1) We introduce a novel metric \r{ho} to quantitatively assess a classifier's robustness against single-word perturbation. (2) We present the SP-Attack, designed to exploit the single-word perturbation vulnerability, achieving a higher attack success rate, better preserving sentence meaning, while reducing computation costs compared to state-of-the-art adversarial methods. (3) We propose SP-Defense, which aims to improve \r{ho} by applying data augmentation in learning. Experimental results on 4 datasets and BERT and distilBERT classifiers show that SP-Defense improves \r{ho} by 14.6% and 13.9% and decreases the attack success rate of SP-Attack by 30.4% and 21.2% on two classifiers respectively, and decreases the attack success rate of existing attack methods that involve multiple-word perturbations.
Modeling glycemia in humans by means of Grammatical Evolution
Apr 27, 2023
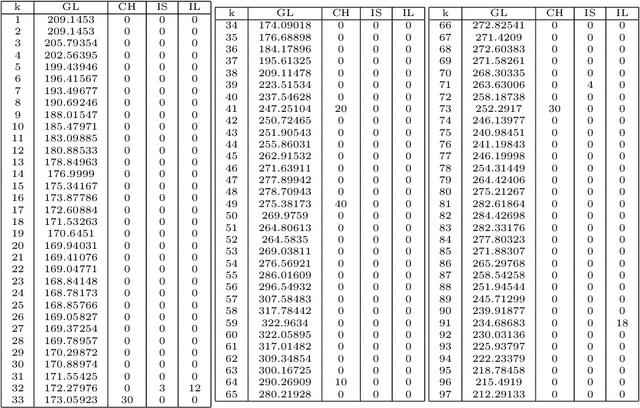

Diabetes mellitus is a disease that affects to hundreds of millions of people worldwide. Maintaining a good control of the disease is critical to avoid severe long-term complications. In recent years, several artificial pancreas systems have been proposed and developed, which are increasingly advanced. However there is still a lot of research to do. One of the main problems that arises in the (semi) automatic control of diabetes, is to get a model explaining how glycemia (glucose levels in blood) varies with insulin, food intakes and other factors, fitting the characteristics of each individual or patient. This paper proposes the application of evolutionary computation techniques to obtain customized models of patients, unlike most of previous approaches which obtain averaged models. The proposal is based on a kind of genetic programming based on grammars known as Grammatical Evolution (GE). The proposal has been tested with in-silico patient data and results are clearly positive. We present also a study of four different grammars and five objective functions. In the test phase the models characterized the glucose with a mean percentage average error of 13.69\%, modeling well also both hyper and hypoglycemic situations.
TadGAN: Time Series Anomaly Detection Using Generative Adversarial Networks
Sep 19, 2020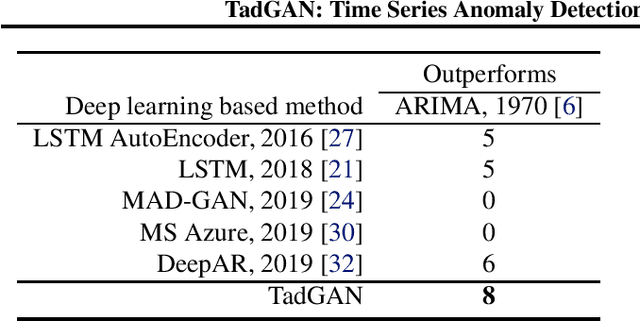
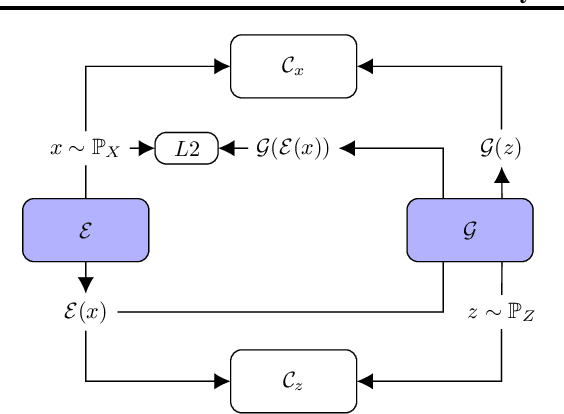
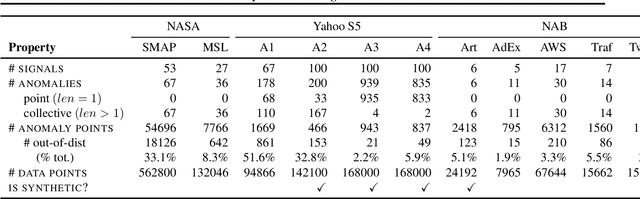
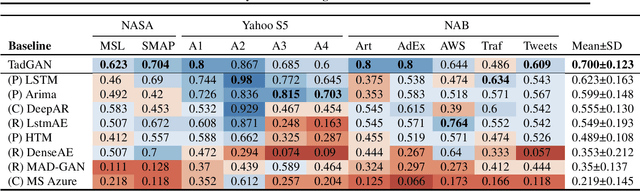
Time series anomalies can offer information relevant to critical situations facing various fields, from finance and aerospace to the IT, security, and medical domains. However, detecting anomalies in time series data is particularly challenging due to the vague definition of anomalies and said data's frequent lack of labels and highly complex temporal correlations. Current state-of-the-art unsupervised machine learning methods for anomaly detection suffer from scalability and portability issues, and may have high false positive rates. In this paper, we propose TadGAN, an unsupervised anomaly detection approach built on Generative Adversarial Networks (GANs). To capture the temporal correlations of time series distributions, we use LSTM Recurrent Neural Networks as base models for Generators and Critics. TadGAN is trained with cycle consistency loss to allow for effective time-series data reconstruction. We further propose several novel methods to compute reconstruction errors, as well as different approaches to combine reconstruction errors and Critic outputs to compute anomaly scores. To demonstrate the performance and generalizability of our approach, we test several anomaly scoring techniques and report the best-suited one. We compare our approach to 8 baseline anomaly detection methods on 11 datasets from multiple reputable sources such as NASA, Yahoo, Numenta, Amazon, and Twitter. The results show that our approach can effectively detect anomalies and outperform baseline methods in most cases (6 out of 11). Notably, our method has the highest averaged F1 score across all the datasets. Our code is open source and is available as a benchmarking tool.
Robust Invisible Video Watermarking with Attention
Sep 03, 2019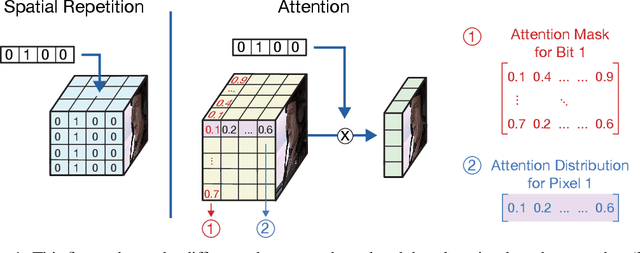
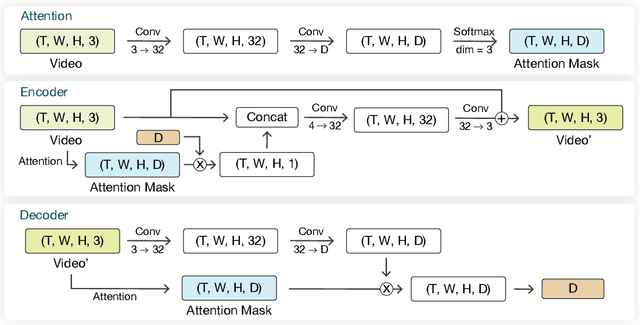
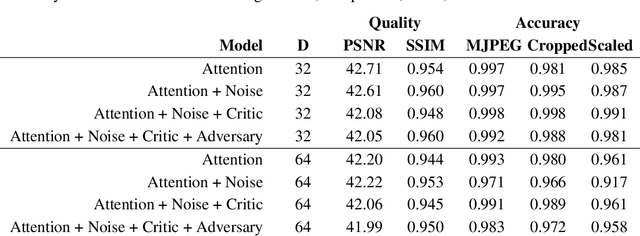

The goal of video watermarking is to embed a message within a video file in a way such that it minimally impacts the viewing experience but can be recovered even if the video is redistributed and modified, allowing media producers to assert ownership over their content. This paper presents RivaGAN, a novel architecture for robust video watermarking which features a custom attention-based mechanism for embedding arbitrary data as well as two independent adversarial networks which critique the video quality and optimize for robustness. Using this technique, we are able to achieve state-of-the-art results in deep learning-based video watermarking and produce watermarked videos which have minimal visual distortion and are robust against common video processing operations.
Learning Fair Classifiers in Online Stochastic Settings
Aug 19, 2019
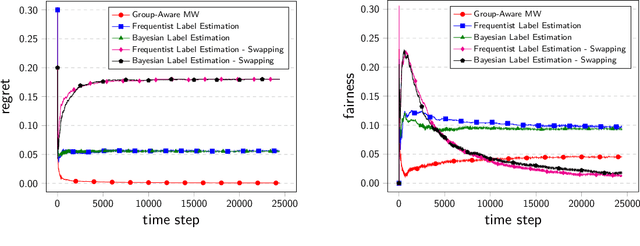
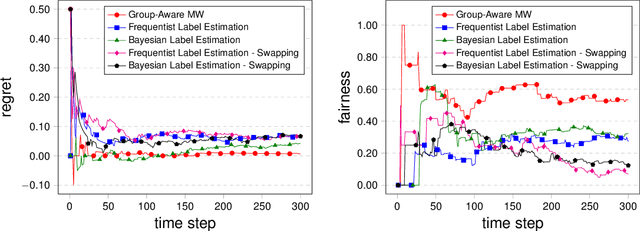
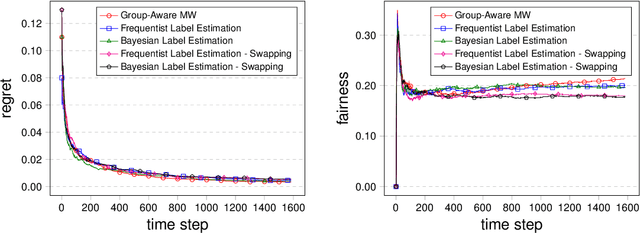
In many real life situations, including job and loan applications, gatekeepers must make justified, real-time decisions about a person's fitness for a particular opportunity. People on both sides of such decisions have understandable concerns about their fairness, especially when they occur online or algorithmically. In this paper we consider the setting where we try to satisfy approximate fairness in an online decision making process where examples are sampled i.i.d from an underlying distribution. The fairness metric we consider is "equalized odds", which requires that approximately equalized false positive rates and false negative rates across groups. Our work follows from the classical learning from experts scheme and extends the multiplicative weights algorithm by maintaining an estimation for label distribution and keeping separate weights for label classes as well as groups. Our theoretical results show that approximate equalized odds can be achieved without sacrificing much regret from some distributions. We also demonstrate the algorithm on real data sets commonly used by the fairness community.
Modeling Tabular data using Conditional GAN
Jul 01, 2019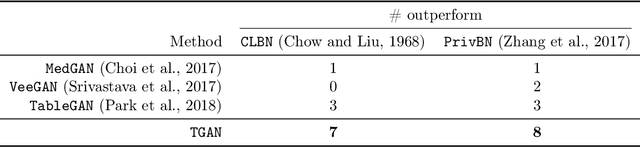
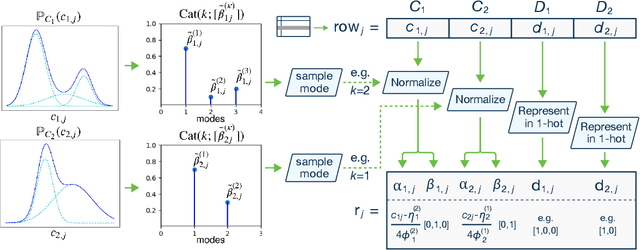
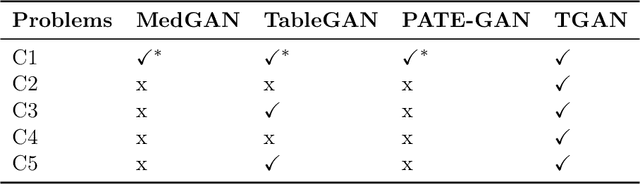
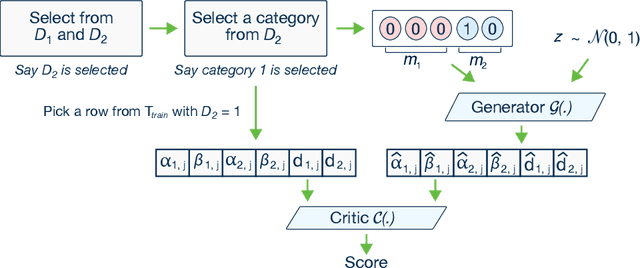
Modeling the probability distribution of rows in tabular data and generating realistic synthetic data is a non-trivial task. Tabular data usually contains a mix of discrete and continuous columns. Continuous columns may have multiple modes whereas discrete columns are sometimes imbalanced making the modeling difficult. Existing statistical and deep neural network models fail to properly model this type of data. We design TGAN, which uses a conditional generative adversarial network to address these challenges. To aid in a fair and thorough comparison, we design a benchmark with 7 simulated and 8 real datasets and several Bayesian network baselines. TGAN outperforms Bayesian methods on most of the real datasets whereas other deep learning methods could not.
SteganoGAN: Pushing the Limits of Image Steganography
Jan 12, 2019
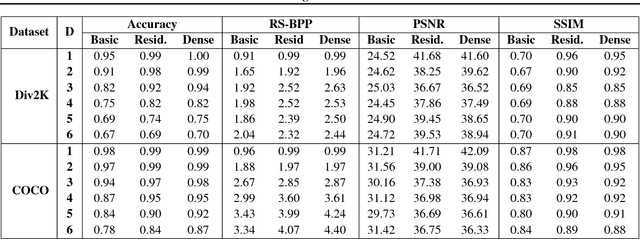
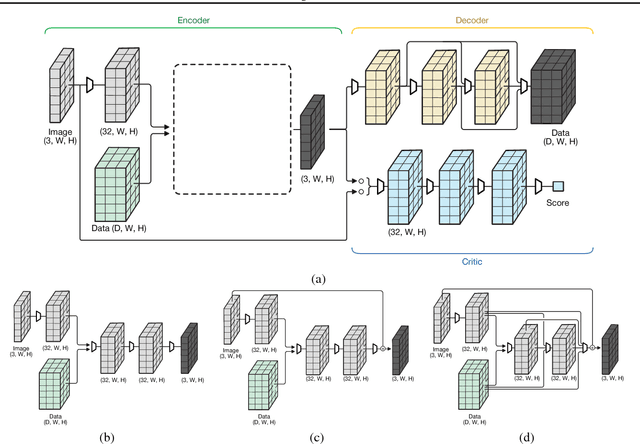

Image steganography is a procedure for hiding messages inside pictures. While other techniques such as cryptography aim to prevent adversaries from reading the secret message, steganography aims to hide the presence of the message itself. In this paper, we propose a novel technique based on generative adversarial networks for hiding arbitrary binary data in images. We show that our approach achieves state-of-the-art payloads of 4.4 bits per pixel, evades detection by steganalysis tools, and is effective on images from multiple datasets. To enable fair comparisons, we have released an open source library that is available online at https://github.com/DAI-Lab/SteganoGAN.
Learning Vine Copula Models For Synthetic Data Generation
Dec 04, 2018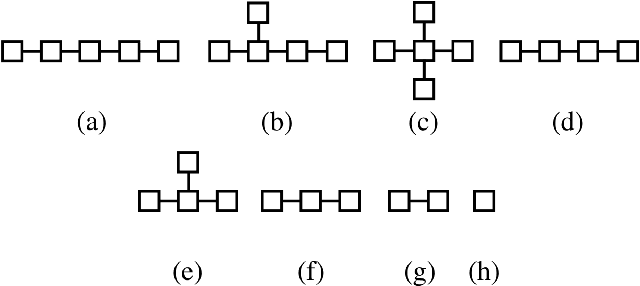
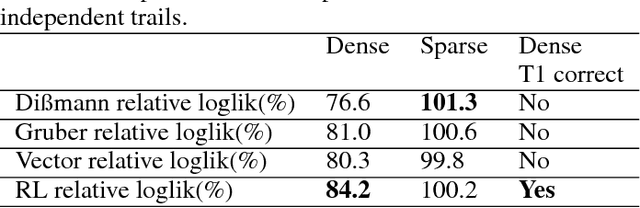
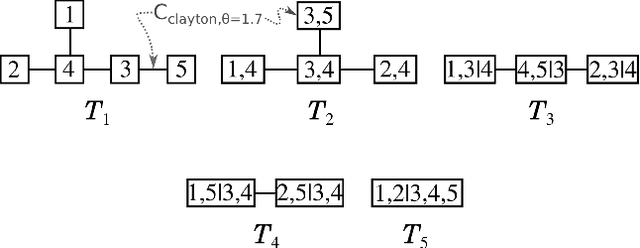

A vine copula model is a flexible high-dimensional dependence model which uses only bivariate building blocks. However, the number of possible configurations of a vine copula grows exponentially as the number of variables increases, making model selection a major challenge in development. In this work, we formulate a vine structure learning problem with both vector and reinforcement learning representation. We use neural network to find the embeddings for the best possible vine model and generate a structure. Throughout experiments on synthetic and real-world datasets, we show that our proposed approach fits the data better in terms of log-likelihood. Moreover, we demonstrate that the model is able to generate high-quality samples in a variety of applications, making it a good candidate for synthetic data generation.