 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMethodology for Online Estimation of Rheological Parameters in Polymer Melts Using Deep Learning and Microfluidics
Dec 05, 2024Microfluidic devices are increasingly used in biological and chemical experiments due to their cost-effectiveness for rheological estimation in fluids. However, these devices often face challenges in terms of accuracy, size, and cost. This study presents a methodology, integrating deep learning, modeling and simulation to enhance the design of microfluidic systems, used to develop an innovative approach for viscosity measurement of polymer melts. We use synthetic data generated from the simulations to train a deep learning model, which then identifies rheological parameters of polymer melts from pressure drop and flow rate measurements in a microfluidic circuit, enabling online estimation of fluid properties. By improving the accuracy and flexibility of microfluidic rheological estimation, our methodology accelerates the design and testing of microfluidic devices, reducing reliance on physical prototypes, and offering significant contributions to the field.
Modeling methodology for the accurate and prompt prediction of symptomatic events in chronic diseases
Feb 15, 2024



Prediction of symptomatic crises in chronic diseases allows to take decisions before the symptoms occur, such as the intake of drugs to avoid the symptoms or the activation of medical alarms. The prediction horizon is in this case an important parameter in order to fulfill the pharmacokinetics of medications, or the time response of medical services. This paper presents a study about the prediction limits of a chronic disease with symptomatic crises: the migraine. For that purpose, this work develops a methodology to build predictive migraine models and to improve these predictions beyond the limits of the initial models. The maximum prediction horizon is analyzed, and its dependency on the selected features is studied. A strategy for model selection is proposed to tackle the trade off between conservative but robust predictive models, with respect to less accurate predictions with higher horizons. The obtained results show a prediction horizon close to 40 minutes, which is in the time range of the drug pharmacokinetics. Experiments have been performed in a realistic scenario where input data have been acquired in an ambulatory clinical study by the deployment of a non-intrusive Wireless Body Sensor Network. Our results provide an effective methodology for the selection of the future horizon in the development of prediction algorithms for diseases experiencing symptomatic crises.
Heuristics and Metaheuristics for Dynamic Management of Computing and Cooling Energy in Cloud Data Centers
Dec 17, 2023Data centers handle impressive high figures in terms of energy consumption, and the growing popularity of Cloud applications is intensifying their computational demand. Moreover, the cooling needed to keep the servers within reliable thermal operating conditions also has an impact on the thermal distribution of the data room, thus affecting to servers' power leakage. Optimizing the energy consumption of these infrastructures is a major challenge to place data centers on a more scalable scenario. Thus, understanding the relationship between power, temperature, consolidation and performance is crucial to enable an energy-efficient management at the data center level. In this research, we propose novel power and thermal-aware strategies and models to provide joint cooling and computing optimizations from a local perspective based on the global energy consumption of metaheuristic-based optimizations. Our results show that the combined awareness from both metaheuristic and best fit decreasing algorithms allow us to describe the global energy into faster and lighter optimization strategies that may be used during runtime. This approach allows us to improve the energy efficiency of the data center, considering both computing and cooling infrastructures, in up to a 21.74\% while maintaining quality of service.
Predictive and diagnosis models of stroke from hemodynamic signal monitoring
May 30, 2023This work presents a novel and promising approach to the clinical management of acute stroke. Using machine learning techniques, our research has succeeded in developing accurate diagnosis and prediction real-time models from hemodynamic data. These models are able to diagnose stroke subtype with 30 minutes of monitoring, to predict the exitus during the first 3 hours of monitoring, and to predict the stroke recurrence in just 15 minutes of monitoring. Patients with difficult access to a \acrshort{CT} scan, and all patients that arrive at the stroke unit of a specialized hospital will benefit from these positive results. The results obtained from the real-time developed models are the following: stroke diagnosis around $98\%$ precision ($97.8\%$ Sensitivity, $99.5\%$ Specificity), exitus prediction with $99.8\%$ precision ($99.8\%$ Sens., $99.9\%$ Spec.) and $98\%$ precision predicting stroke recurrence ($98\%$ Sens., $99\%$ Spec.).
Bringing AI to the edge: A formal M&S specification to deploy effective IoT architectures
May 11, 2023The Internet of Things is transforming our society, providing new services that improve the quality of life and resource management. These applications are based on ubiquitous networks of multiple distributed devices, with limited computing resources and power, capable of collecting and storing data from heterogeneous sources in real-time. To avoid network saturation and high delays, new architectures such as fog computing are emerging to bring computing infrastructure closer to data sources. Additionally, new data centers are needed to provide real-time Big Data and data analytics capabilities at the edge of the network, where energy efficiency needs to be considered to ensure a sustainable and effective deployment in areas of human activity. In this research, we present an IoT model based on the principles of Model-Based Systems Engineering defined using the Discrete Event System Specification formalism. The provided mathematical formalism covers the description of the entire architecture, from IoT devices to the processing units in edge data centers. Our work includes the location-awareness of user equipment, network, and computing infrastructures to optimize federated resource management in terms of delay and power consumption. We present an effective framework to assist the dimensioning and the dynamic operation of IoT data stream analytics applications, demonstrating our contributions through a driving assistance use case based on real traces and data.
Modeling glycemia in humans by means of Grammatical Evolution
Apr 27, 2023
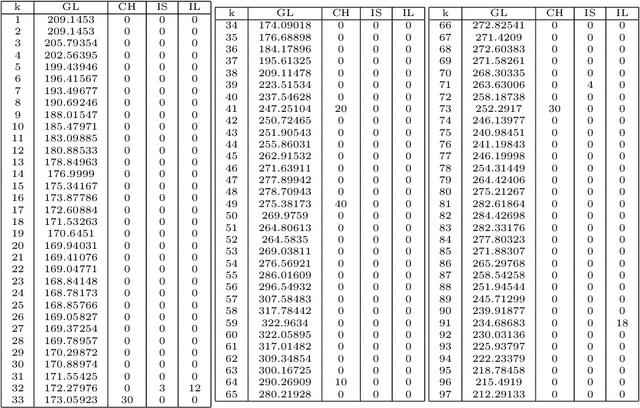
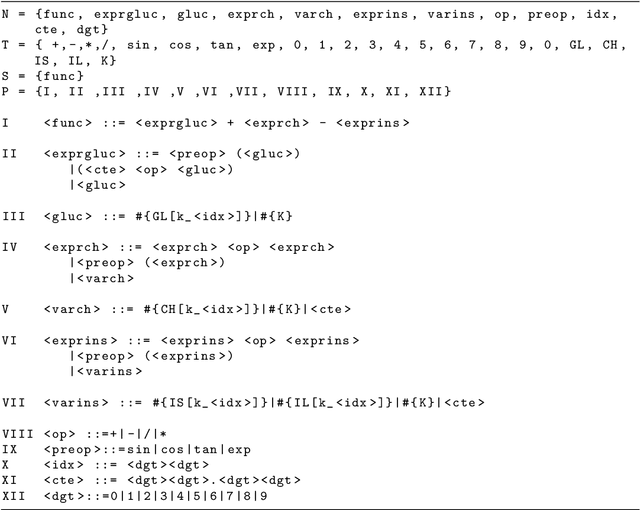

Diabetes mellitus is a disease that affects to hundreds of millions of people worldwide. Maintaining a good control of the disease is critical to avoid severe long-term complications. In recent years, several artificial pancreas systems have been proposed and developed, which are increasingly advanced. However there is still a lot of research to do. One of the main problems that arises in the (semi) automatic control of diabetes, is to get a model explaining how glycemia (glucose levels in blood) varies with insulin, food intakes and other factors, fitting the characteristics of each individual or patient. This paper proposes the application of evolutionary computation techniques to obtain customized models of patients, unlike most of previous approaches which obtain averaged models. The proposal is based on a kind of genetic programming based on grammars known as Grammatical Evolution (GE). The proposal has been tested with in-silico patient data and results are clearly positive. We present also a study of four different grammars and five objective functions. In the test phase the models characterized the glucose with a mean percentage average error of 13.69\%, modeling well also both hyper and hypoglycemic situations.
Optimizing L1 cache for embedded systems through grammatical evolution
Mar 06, 2023Nowadays, embedded systems are provided with cache memories that are large enough to influence in both performance and energy consumption as never occurred before in this kind of systems. In addition, the cache memory system has been identified as a component that improves those metrics by adapting its configuration according to the memory access patterns of the applications being run. However, given that cache memories have many parameters which may be set to a high number of different values, designers face to a wide and time-consuming exploration space. In this paper we propose an optimization framework based on Grammatical Evolution (GE) which is able to efficiently find the best cache configurations for a given set of benchmark applications. This metaheuristic allows an important reduction of the optimization runtime obtaining good results in a low number of generations. Besides, this reduction is also increased due to the efficient storage of evaluated caches. Moreover, we selected GE because the plasticity of the grammar eases the creation of phenotypes that form the call to the cache simulator required for the evaluation of the different configurations. Experimental results for the Mediabench suite show that our proposal is able to find cache configurations that obtain an average improvement of $62\%$ versus a real world baseline configuration.
Multi-objective optimization of energy consumption and execution time in a single level cache memory for embedded systems
Feb 22, 2023



Current embedded systems are specifically designed to run multimedia applications. These applications have a big impact on both performance and energy consumption. Both metrics can be optimized selecting the best cache configuration for a target set of applications. Multi-objective optimization may help to minimize both conflicting metrics in an independent manner. In this work, we propose an optimization method that based on Multi-Objective Evolutionary Algorithms, is able to find the best cache configuration for a given set of applications. To evaluate the goodness of candidate solutions, the execution of the optimization algorithm is combined with a static profiling methodology using several well-known simulation tools. Results show that our optimization framework is able to obtain an optimized cache for Mediabench applications. Compared to a baseline cache memory, our design method reaches an average improvement of 64.43\% and 91.69\% in execution time and energy consumption, respectively.
A Unified Cloud-Enabled Discrete Event Parallel and Distributed Simulation Architecture
Feb 22, 2023



Cloud simulation environments today are largely employed to model and simulate complex systems for remote accessibility and variable capacity requirements. In this regard, scalability issues in Modeling and Simulation (M\&S) computational requirements can be tackled through the elasticity of on-demand Cloud deployment. However, implementing a high performance cloud M\&S framework following these elastic principles is not a trivial task as parallelizing and distributing existing architectures is challenging. Indeed, both the parallel and distributed M\&S developments have evolved following separate ways. Parallel solutions has always been focused on ad-hoc solutions, while distributed approaches, on the other hand, have led to the definition of standard distributed frameworks like the High Level Architecture (HLA) or influenced the use of distributed technologies like the Message Passing Interface (MPI). Only a few developments have been able to evolve with the current resilience of computing hardware resources deployment, largely focused on the implementation of Simulation as a Service (SaaS), albeit independently of the parallel ad-hoc methods branch. In this paper, we present a unified parallel and distributed M\&S architecture with enough flexibility to deploy parallel and distributed simulations in the Cloud with a low effort, without modifying the underlying model source code, and reaching important speedups against the sequential simulation, especially in the parallel implementation. Our framework is based on the Discrete Event System Specification (DEVS) formalism. The performance of the parallel and distributed framework is tested using the xDEVS M\&S tool, Application Programming Interface (API) and the DEVStone benchmark with up to eight computing nodes, obtaining maximum speedups of $15.95\times$ and $1.84\times$, respectively.
Efficient micro data centres deployment for mobile healthcare monitoring systems in IoT urban scenarios
Feb 20, 2023In the last decade, the Internet of Things paradigm has caused an exponential increase in the number of connected devices. This trend brings the Internet closer to everyday activities and enables data collection that can be used to create and improve a great variety of services and applications. Despite its great benefits, this paradigm also comes with several challenges. More powerful storage and processing capabilities are required to service all these devices. Additionally, the need to deploy and manage the infrastructure to efficiently support these resources continues to pose a challenge. Modeling and simulation can help to design and analyze these scenarios, providing flexible and powerful mechanisms to study and compare different strategies and infrastructures. In this scenario, Micro Data Centers (MDCs) can be used as an effective way of reducing overwhelmed Cloud Data Center infrastructures. This paper explores an M\&S methodology to study the overall power consumption of a healthcare IoT scenario. The patients wear non-intrusive monitoring devices that periodically generate tasks to be executed in MDCs. We extract the layout of existing urban infrastructures, simulate the monitored population's behavior, and compare the power consumption of several data center configurations.