 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing L1 cache for embedded systems through grammatical evolution
Mar 06, 2023Nowadays, embedded systems are provided with cache memories that are large enough to influence in both performance and energy consumption as never occurred before in this kind of systems. In addition, the cache memory system has been identified as a component that improves those metrics by adapting its configuration according to the memory access patterns of the applications being run. However, given that cache memories have many parameters which may be set to a high number of different values, designers face to a wide and time-consuming exploration space. In this paper we propose an optimization framework based on Grammatical Evolution (GE) which is able to efficiently find the best cache configurations for a given set of benchmark applications. This metaheuristic allows an important reduction of the optimization runtime obtaining good results in a low number of generations. Besides, this reduction is also increased due to the efficient storage of evaluated caches. Moreover, we selected GE because the plasticity of the grammar eases the creation of phenotypes that form the call to the cache simulator required for the evaluation of the different configurations. Experimental results for the Mediabench suite show that our proposal is able to find cache configurations that obtain an average improvement of $62\%$ versus a real world baseline configuration.
A Critical Review of the state-of-the-art on Deep Neural Networks for Blood Glucose Prediction in Patients with Diabetes
Sep 02, 2021

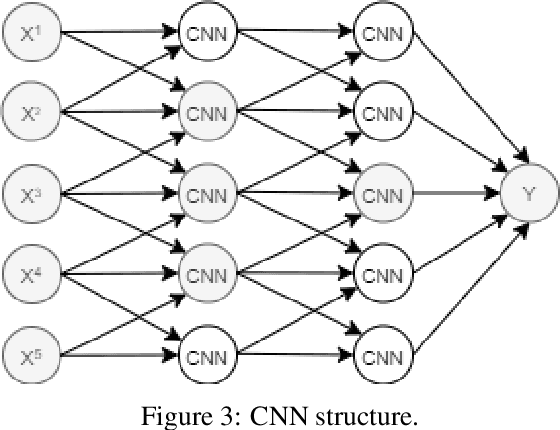
This article compares ten recently proposed neural networks and proposes two ensemble neural network-based models for blood glucose prediction. All of them are tested under the same dataset, preprocessing workflow, and tools using the OhioT1DM Dataset at three different prediction horizons: 30, 60, and 120 minutes. We compare their performance using the most common metrics in blood glucose prediction and rank the best-performing ones using three methods devised for the statistical comparison of the performance of multiple algorithms: scmamp, model confidence set, and superior predictive ability. Our analysis highlights those models with the highest probability of being the best predictors, estimates the increase in error of the models that perform more poorly with respect to the best ones, and provides a guide for their use in clinical practice.