 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewriting Meaningful Sentences via Conditional BERT Sampling and an application on fooling text classifiers
Oct 22, 2020
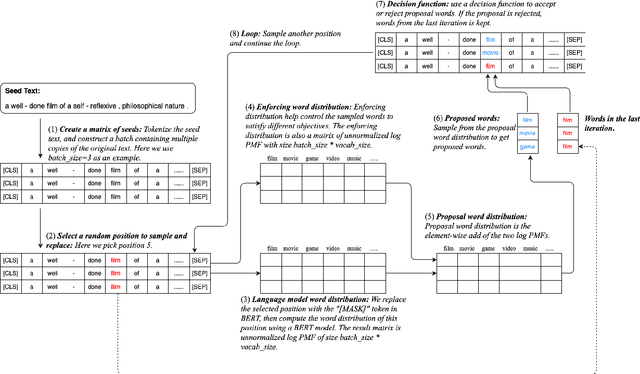

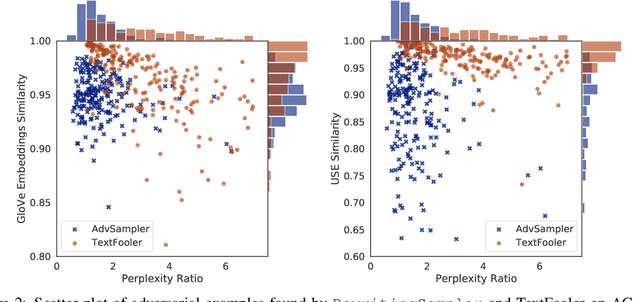
Most adversarial attack methods that are designed to deceive a text classifier change the text classifier's prediction by modifying a few words or characters. Few try to attack classifiers by rewriting a whole sentence, due to the difficulties inherent in sentence-level rephrasing as well as the problem of setting the criteria for legitimate rewriting. In this paper, we explore the problem of creating adversarial examples with sentence-level rewriting. We design a new sampling method, named ParaphraseSampler, to efficiently rewrite the original sentence in multiple ways. Then we propose a new criteria for modification, called a sentence-level threaten model. This criteria allows for both word- and sentence-level changes, and can be adjusted independently in two dimensions: semantic similarity and grammatical quality. Experimental results show that many of these rewritten sentences are misclassified by the classifier. On all 6 datasets, our ParaphraseSampler achieves a better attack success rate than our baseline.
Learning Fair Classifiers in Online Stochastic Settings
Aug 19, 2019
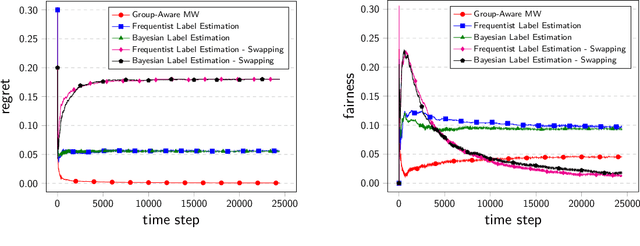
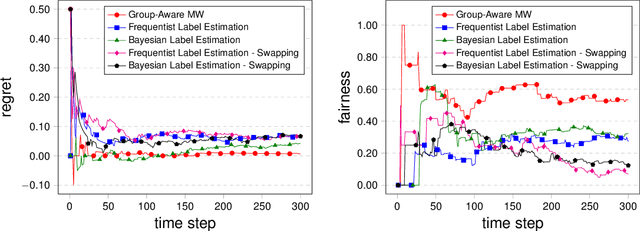
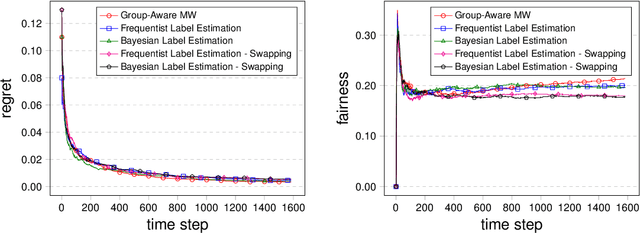
In many real life situations, including job and loan applications, gatekeepers must make justified, real-time decisions about a person's fitness for a particular opportunity. People on both sides of such decisions have understandable concerns about their fairness, especially when they occur online or algorithmically. In this paper we consider the setting where we try to satisfy approximate fairness in an online decision making process where examples are sampled i.i.d from an underlying distribution. The fairness metric we consider is "equalized odds", which requires that approximately equalized false positive rates and false negative rates across groups. Our work follows from the classical learning from experts scheme and extends the multiplicative weights algorithm by maintaining an estimation for label distribution and keeping separate weights for label classes as well as groups. Our theoretical results show that approximate equalized odds can be achieved without sacrificing much regret from some distributions. We also demonstrate the algorithm on real data sets commonly used by the fairness community.