 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplingo: Explaining AI Predictions using Large Language Models
Dec 06, 2024



Explanations of machine learning (ML) model predictions generated by Explainable AI (XAI) techniques such as SHAP are essential for people using ML outputs for decision-making. We explore the potential of Large Language Models (LLMs) to transform these explanations into human-readable, narrative formats that align with natural communication. We address two key research questions: (1) Can LLMs reliably transform traditional explanations into high-quality narratives? and (2) How can we effectively evaluate the quality of narrative explanations? To answer these questions, we introduce Explingo, which consists of two LLM-based subsystems, a Narrator and Grader. The Narrator takes in ML explanations and transforms them into natural-language descriptions. The Grader scores these narratives on a set of metrics including accuracy, completeness, fluency, and conciseness. Our experiments demonstrate that LLMs can generate high-quality narratives that achieve high scores across all metrics, particularly when guided by a small number of human-labeled and bootstrapped examples. We also identified areas that remain challenging, in particular for effectively scoring narratives in complex domains. The findings from this work have been integrated into an open-source tool that makes narrative explanations available for further applications.
Large language models can be zero-shot anomaly detectors for time series?
May 23, 2024



Recent studies have shown the ability of large language models to perform a variety of tasks, including time series forecasting. The flexible nature of these models allows them to be used for many applications. In this paper, we present a novel study of large language models used for the challenging task of time series anomaly detection. This problem entails two aspects novel for LLMs: the need for the model to identify part of the input sequence (or multiple parts) as anomalous; and the need for it to work with time series data rather than the traditional text input. We introduce sigllm, a framework for time series anomaly detection using large language models. Our framework includes a time-series-to-text conversion module, as well as end-to-end pipelines that prompt language models to perform time series anomaly detection. We investigate two paradigms for testing the abilities of large language models to perform the detection task. First, we present a prompt-based detection method that directly asks a language model to indicate which elements of the input are anomalies. Second, we leverage the forecasting capability of a large language model to guide the anomaly detection process. We evaluated our framework on 11 datasets spanning various sources and 10 pipelines. We show that the forecasting method significantly outperformed the prompting method in all 11 datasets with respect to the F1 score. Moreover, while large language models are capable of finding anomalies, state-of-the-art deep learning models are still superior in performance, achieving results 30% better than large language models.
Single Word Change is All You Need: Designing Attacks and Defenses for Text Classifiers
Jan 30, 2024In text classification, creating an adversarial example means subtly perturbing a few words in a sentence without changing its meaning, causing it to be misclassified by a classifier. A concerning observation is that a significant portion of adversarial examples generated by existing methods change only one word. This single-word perturbation vulnerability represents a significant weakness in classifiers, which malicious users can exploit to efficiently create a multitude of adversarial examples. This paper studies this problem and makes the following key contributions: (1) We introduce a novel metric \r{ho} to quantitatively assess a classifier's robustness against single-word perturbation. (2) We present the SP-Attack, designed to exploit the single-word perturbation vulnerability, achieving a higher attack success rate, better preserving sentence meaning, while reducing computation costs compared to state-of-the-art adversarial methods. (3) We propose SP-Defense, which aims to improve \r{ho} by applying data augmentation in learning. Experimental results on 4 datasets and BERT and distilBERT classifiers show that SP-Defense improves \r{ho} by 14.6% and 13.9% and decreases the attack success rate of SP-Attack by 30.4% and 21.2% on two classifiers respectively, and decreases the attack success rate of existing attack methods that involve multiple-word perturbations.
Pyreal: A Framework for Interpretable ML Explanations
Dec 20, 2023Users in many domains use machine learning (ML) predictions to help them make decisions. Effective ML-based decision-making often requires explanations of ML models and their predictions. While there are many algorithms that explain models, generating explanations in a format that is comprehensible and useful to decision-makers is a nontrivial task that can require extensive development overhead. We developed Pyreal, a highly extensible system with a corresponding Python implementation for generating a variety of interpretable ML explanations. Pyreal converts data and explanations between the feature spaces expected by the model, relevant explanation algorithms, and human users, allowing users to generate interpretable explanations in a low-code manner. Our studies demonstrate that Pyreal generates more useful explanations than existing systems while remaining both easy-to-use and efficient.
Making the End-User a Priority in Benchmarking: OrionBench for Unsupervised Time Series Anomaly Detection
Oct 26, 2023Time series anomaly detection is a prevalent problem in many application domains such as patient monitoring in healthcare, forecasting in finance, or predictive maintenance in energy. This has led to the emergence of a plethora of anomaly detection methods, including more recently, deep learning based methods. Although several benchmarks have been proposed to compare newly developed models, they usually rely on one-time execution over a limited set of datasets and the comparison is restricted to a few models. We propose OrionBench -- a user centric continuously maintained benchmark for unsupervised time series anomaly detection. The framework provides universal abstractions to represent models, extensibility to add new pipelines and datasets, hyperparameter standardization, pipeline verification, and frequent releases with published benchmarks. We demonstrate the usage of OrionBench, and the progression of pipelines across 15 releases published over the course of three years. Moreover, we walk through two real scenarios we experienced with OrionBench that highlight the importance of continuous benchmarks in unsupervised time series anomaly detection.
Discovering Transition Pathways Towards Coviability with Machine Learning
Jan 06, 2023Coviability refers to the multiple socio-ecological arrangements and governance structures under which humans and nature can coexist in functional, fair, and persistent ways. Transitioning to a coviable state in environmentally degraded and socially vulnerable territories is challenging. This paper presents an ongoing French-Brazilian joint research project combining machine learning, agroecology, and social sciences to discover coviability pathways that can be adopted and implemented by local populations in the North-East region of Brazil.
AER: Auto-Encoder with Regression for Time Series Anomaly Detection
Dec 27, 2022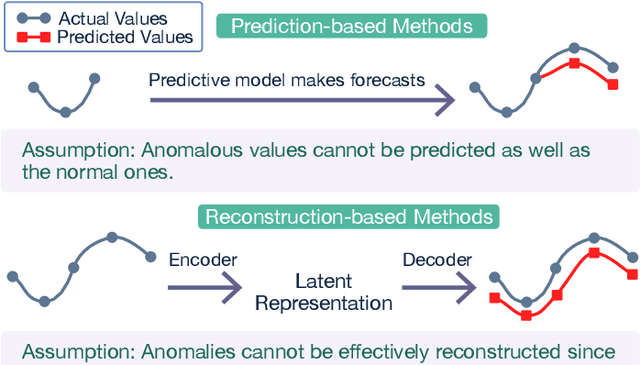
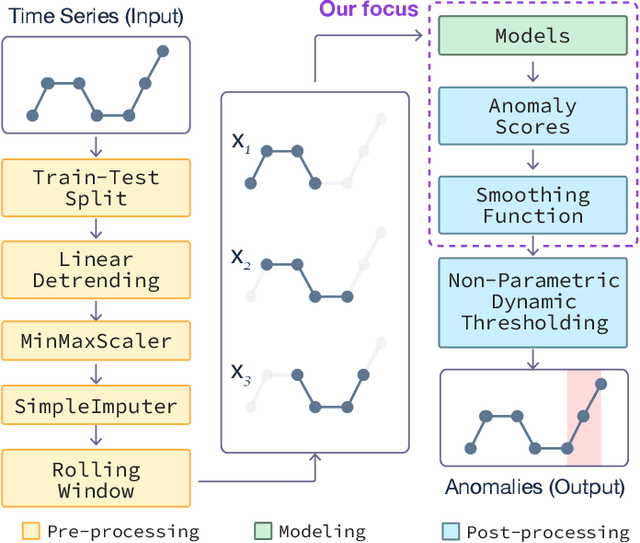
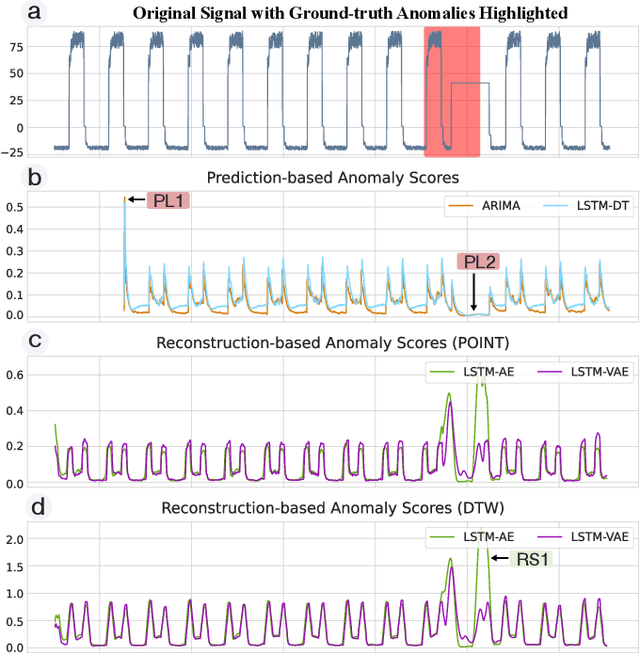
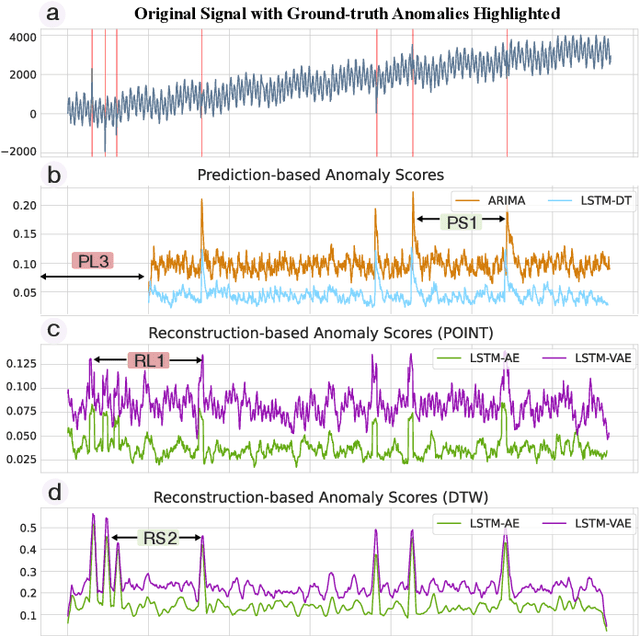
Anomaly detection on time series data is increasingly common across various industrial domains that monitor metrics in order to prevent potential accidents and economic losses. However, a scarcity of labeled data and ambiguous definitions of anomalies can complicate these efforts. Recent unsupervised machine learning methods have made remarkable progress in tackling this problem using either single-timestamp predictions or time series reconstructions. While traditionally considered separately, these methods are not mutually exclusive and can offer complementary perspectives on anomaly detection. This paper first highlights the successes and limitations of prediction-based and reconstruction-based methods with visualized time series signals and anomaly scores. We then propose AER (Auto-encoder with Regression), a joint model that combines a vanilla auto-encoder and an LSTM regressor to incorporate the successes and address the limitations of each method. Our model can produce bi-directional predictions while simultaneously reconstructing the original time series by optimizing a joint objective function. Furthermore, we propose several ways of combining the prediction and reconstruction errors through a series of ablation studies. Finally, we compare the performance of the AER architecture against two prediction-based methods and three reconstruction-based methods on 12 well-known univariate time series datasets from NASA, Yahoo, Numenta, and UCR. The results show that AER has the highest averaged F1 score across all datasets (a 23.5% improvement compared to ARIMA) while retaining a runtime similar to its vanilla auto-encoder and regressor components. Our model is available in Orion, an open-source benchmarking tool for time series anomaly detection.
Reconstruction of Long-Term Historical Demand Data
Sep 10, 2022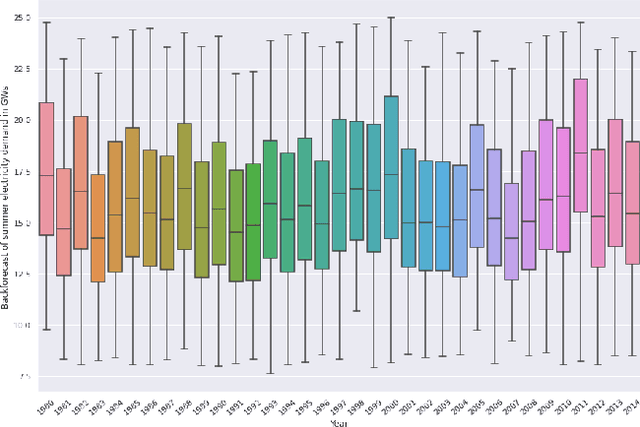

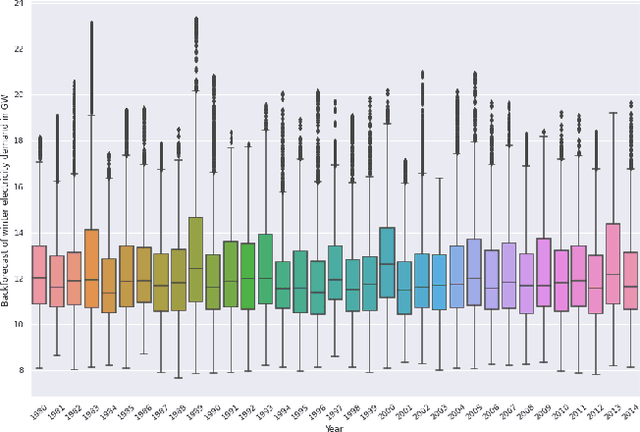
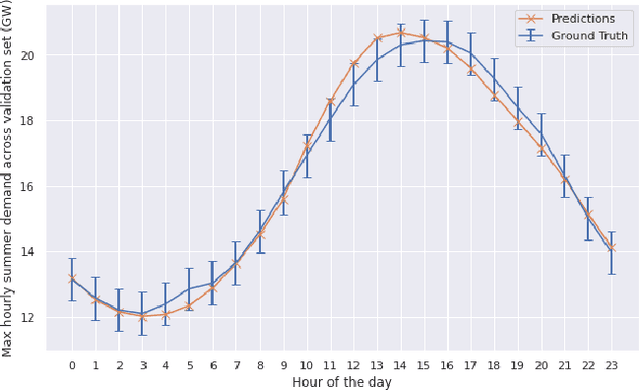
Long-term planning of a robust power system requires the understanding of changing demand patterns. Electricity demand is highly weather sensitive. Thus, the supply side variation from introducing intermittent renewable sources, juxtaposed with variable demand, will introduce additional challenges in the grid planning process. By understanding the spatial and temporal variability of temperature over the US, the response of demand to natural variability and climate change-related effects on temperature can be separated, especially because the effects due to the former factor are not known. Through this project, we aim to better support the technology & policy development process for power systems by developing machine and deep learning 'back-forecasting' models to reconstruct multidecadal demand records and study the natural variability of temperature and its influence on demand.
* Accepted to Tackling Climate Change with Machine Learning Workshop, ICML 2021
Sintel: A Machine Learning Framework to Extract Insights from Signals
Apr 19, 2022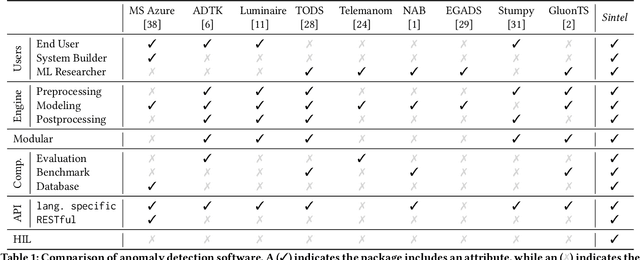
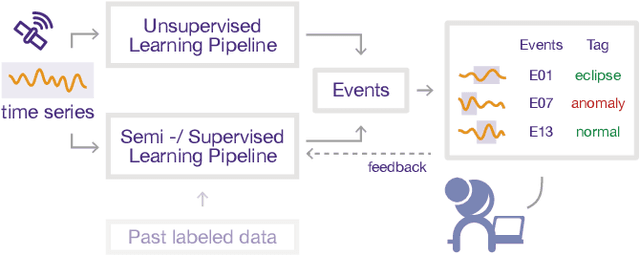
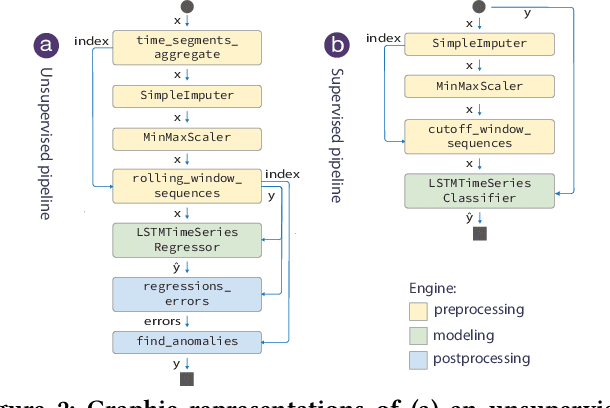

The detection of anomalies in time series data is a critical task with many monitoring applications. Existing systems often fail to encompass an end-to-end detection process, to facilitate comparative analysis of various anomaly detection methods, or to incorporate human knowledge to refine output. This precludes current methods from being used in real-world settings by practitioners who are not ML experts. In this paper, we introduce Sintel, a machine learning framework for end-to-end time series tasks such as anomaly detection. The framework uses state-of-the-art approaches to support all steps of the anomaly detection process. Sintel logs the entire anomaly detection journey, providing detailed documentation of anomalies over time. It enables users to analyze signals, compare methods, and investigate anomalies through an interactive visualization tool, where they can annotate, modify, create, and remove events. Using these annotations, the framework leverages human knowledge to improve the anomaly detection pipeline. We demonstrate the usability, efficiency, and effectiveness of Sintel through a series of experiments on three public time series datasets, as well as one real-world use case involving spacecraft experts tasked with anomaly analysis tasks. Sintel's framework, code, and datasets are open-sourced at https://github.com/sintel-dev/.
The Need for Interpretable Features: Motivation and Taxonomy
Feb 23, 2022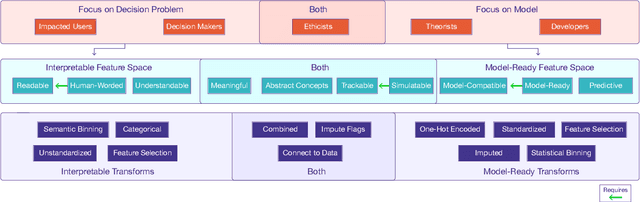
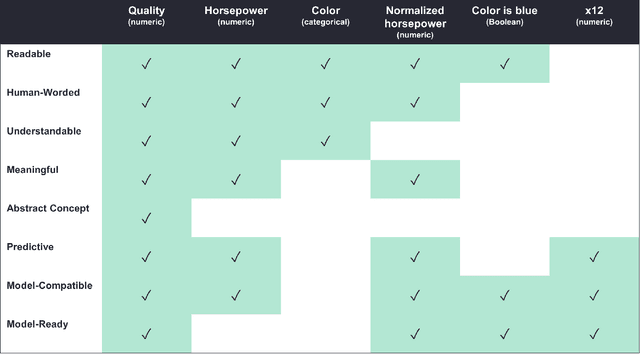

Through extensive experience developing and explaining machine learning (ML) applications for real-world domains, we have learned that ML models are only as interpretable as their features. Even simple, highly interpretable model types such as regression models can be difficult or impossible to understand if they use uninterpretable features. Different users, especially those using ML models for decision-making in their domains, may require different levels and types of feature interpretability. Furthermore, based on our experiences, we claim that the term "interpretable feature" is not specific nor detailed enough to capture the full extent to which features impact the usefulness of ML explanations. In this paper, we motivate and discuss three key lessons: 1) more attention should be given to what we refer to as the interpretable feature space, or the state of features that are useful to domain experts taking real-world actions, 2) a formal taxonomy is needed of the feature properties that may be required by these domain experts (we propose a partial taxonomy in this paper), and 3) transforms that take data from the model-ready state to an interpretable form are just as essential as traditional ML transforms that prepare features for the model.