 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Need for Interpretable Features: Motivation and Taxonomy
Paper and Code
Feb 23, 2022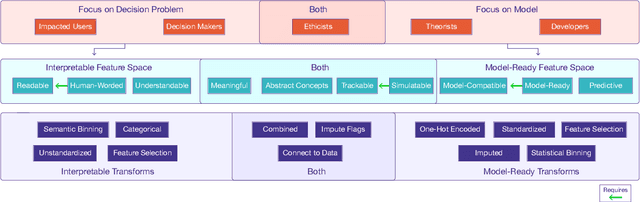
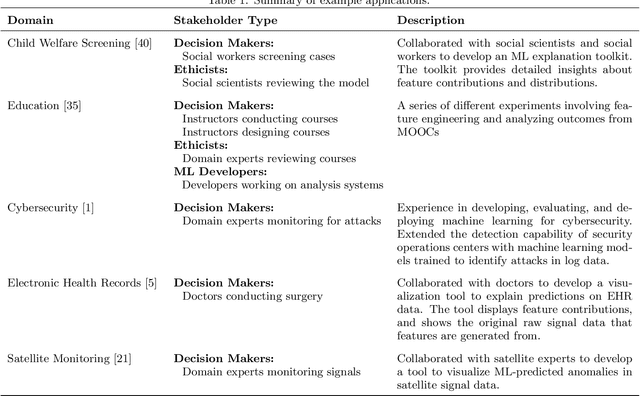
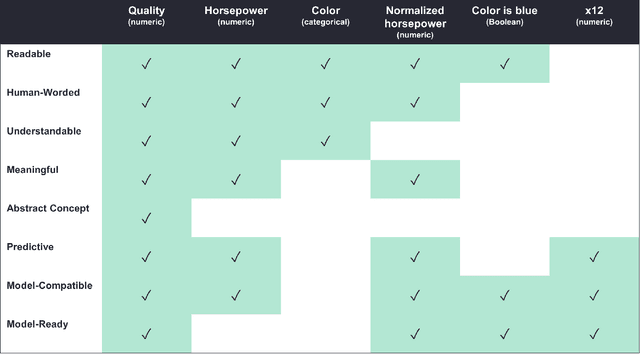

Through extensive experience developing and explaining machine learning (ML) applications for real-world domains, we have learned that ML models are only as interpretable as their features. Even simple, highly interpretable model types such as regression models can be difficult or impossible to understand if they use uninterpretable features. Different users, especially those using ML models for decision-making in their domains, may require different levels and types of feature interpretability. Furthermore, based on our experiences, we claim that the term "interpretable feature" is not specific nor detailed enough to capture the full extent to which features impact the usefulness of ML explanations. In this paper, we motivate and discuss three key lessons: 1) more attention should be given to what we refer to as the interpretable feature space, or the state of features that are useful to domain experts taking real-world actions, 2) a formal taxonomy is needed of the feature properties that may be required by these domain experts (we propose a partial taxonomy in this paper), and 3) transforms that take data from the model-ready state to an interpretable form are just as essential as traditional ML transforms that prepare features for the model.