 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$τ$-Knowledge: Evaluating Conversational Agents over Unstructured Knowledge
Mar 04, 2026Conversational agents are increasingly deployed in knowledge-intensive settings, where correct behavior depends on retrieving and applying domain-specific knowledge from large, proprietary, and unstructured corpora during live interactions with users. Yet most existing benchmarks evaluate retrieval or tool use independently of each other, creating a gap in realistic, fully agentic evaluation over unstructured data in long-horizon interactions. We introduce $τ$-Knowledge, an extension of $τ$-Bench for evaluating agents in environments where success depends on coordinating external, natural-language knowledge with tool outputs to produce verifiable, policy-compliant state changes. Our new domain, $τ$-Banking, models realistic fintech customer support workflows in which agents must navigate roughly 700 interconnected knowledge documents while executing tool-mediated account updates. Across embedding-based retrieval and terminal-based search, even frontier models with high reasoning budgets achieve only $\sim$25.5% pass^1, with reliability degrading sharply over repeated trials. Agents struggle to retrieve the correct documents from densely interlinked knowledge bases and to reason accurately over complex internal policies. Overall, $τ$-Knowledge provides a realistic testbed for developing agents that integrate unstructured knowledge in human-facing deployments.
Explingo: Explaining AI Predictions using Large Language Models
Dec 06, 2024



Explanations of machine learning (ML) model predictions generated by Explainable AI (XAI) techniques such as SHAP are essential for people using ML outputs for decision-making. We explore the potential of Large Language Models (LLMs) to transform these explanations into human-readable, narrative formats that align with natural communication. We address two key research questions: (1) Can LLMs reliably transform traditional explanations into high-quality narratives? and (2) How can we effectively evaluate the quality of narrative explanations? To answer these questions, we introduce Explingo, which consists of two LLM-based subsystems, a Narrator and Grader. The Narrator takes in ML explanations and transforms them into natural-language descriptions. The Grader scores these narratives on a set of metrics including accuracy, completeness, fluency, and conciseness. Our experiments demonstrate that LLMs can generate high-quality narratives that achieve high scores across all metrics, particularly when guided by a small number of human-labeled and bootstrapped examples. We also identified areas that remain challenging, in particular for effectively scoring narratives in complex domains. The findings from this work have been integrated into an open-source tool that makes narrative explanations available for further applications.
LLMs for XAI: Future Directions for Explaining Explanations
May 09, 2024In response to the demand for Explainable Artificial Intelligence (XAI), we investigate the use of Large Language Models (LLMs) to transform ML explanations into natural, human-readable narratives. Rather than directly explaining ML models using LLMs, we focus on refining explanations computed using existing XAI algorithms. We outline several research directions, including defining evaluation metrics, prompt design, comparing LLM models, exploring further training methods, and integrating external data. Initial experiments and user study suggest that LLMs offer a promising way to enhance the interpretability and usability of XAI.
Pyreal: A Framework for Interpretable ML Explanations
Dec 20, 2023Users in many domains use machine learning (ML) predictions to help them make decisions. Effective ML-based decision-making often requires explanations of ML models and their predictions. While there are many algorithms that explain models, generating explanations in a format that is comprehensible and useful to decision-makers is a nontrivial task that can require extensive development overhead. We developed Pyreal, a highly extensible system with a corresponding Python implementation for generating a variety of interpretable ML explanations. Pyreal converts data and explanations between the feature spaces expected by the model, relevant explanation algorithms, and human users, allowing users to generate interpretable explanations in a low-code manner. Our studies demonstrate that Pyreal generates more useful explanations than existing systems while remaining both easy-to-use and efficient.
Lessons from Usable ML Deployments and Application to Wind Turbine Monitoring
Dec 05, 2023Through past experiences deploying what we call usable ML (one step beyond explainable ML, including both explanations and other augmenting information) to real-world domains, we have learned three key lessons. First, many organizations are beginning to hire people who we call ``bridges'' because they bridge the gap between ML developers and domain experts, and these people fill a valuable role in developing usable ML applications. Second, a configurable system that enables easily iterating on usable ML interfaces during collaborations with bridges is key. Finally, there is a need for continuous, in-deployment evaluations to quantify the real-world impact of usable ML. Throughout this paper, we apply these lessons to the task of wind turbine monitoring, an essential task in the renewable energy domain. Turbine engineers and data analysts must decide whether to perform costly in-person investigations on turbines to prevent potential cases of brakepad failure, and well-tuned usable ML interfaces can aid with this decision-making process. Through the applications of our lessons to this task, we hope to demonstrate the potential real-world impact of usable ML in the renewable energy domain.
The Need for Interpretable Features: Motivation and Taxonomy
Feb 23, 2022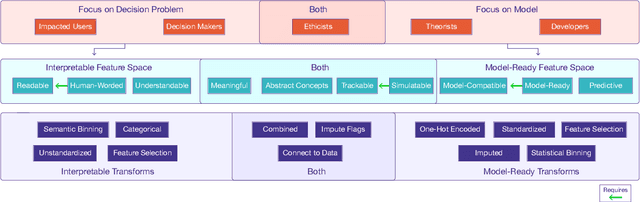
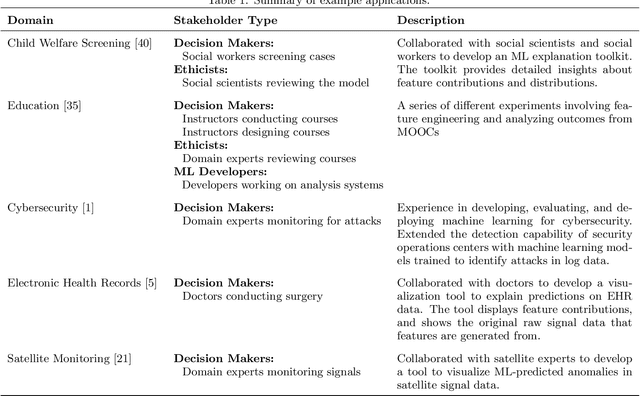
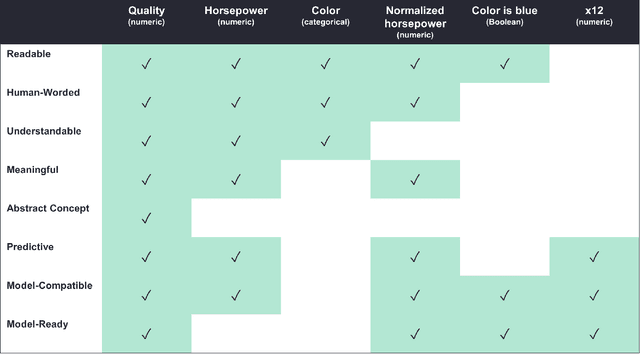

Through extensive experience developing and explaining machine learning (ML) applications for real-world domains, we have learned that ML models are only as interpretable as their features. Even simple, highly interpretable model types such as regression models can be difficult or impossible to understand if they use uninterpretable features. Different users, especially those using ML models for decision-making in their domains, may require different levels and types of feature interpretability. Furthermore, based on our experiences, we claim that the term "interpretable feature" is not specific nor detailed enough to capture the full extent to which features impact the usefulness of ML explanations. In this paper, we motivate and discuss three key lessons: 1) more attention should be given to what we refer to as the interpretable feature space, or the state of features that are useful to domain experts taking real-world actions, 2) a formal taxonomy is needed of the feature properties that may be required by these domain experts (we propose a partial taxonomy in this paper), and 3) transforms that take data from the model-ready state to an interpretable form are just as essential as traditional ML transforms that prepare features for the model.
VBridge: Connecting the Dots Between Features, Explanations, and Data for Healthcare Models
Aug 04, 2021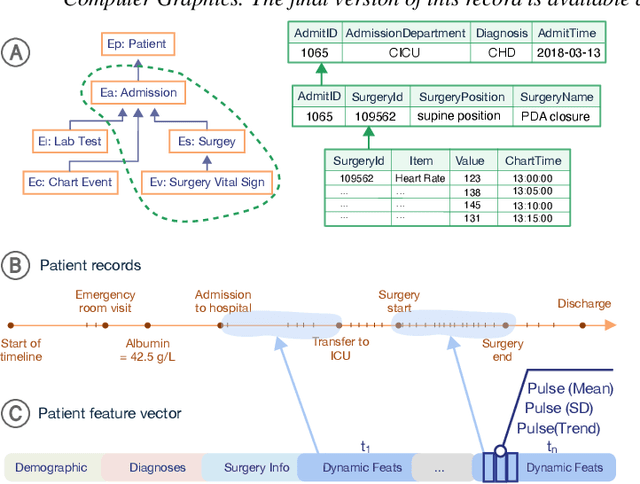
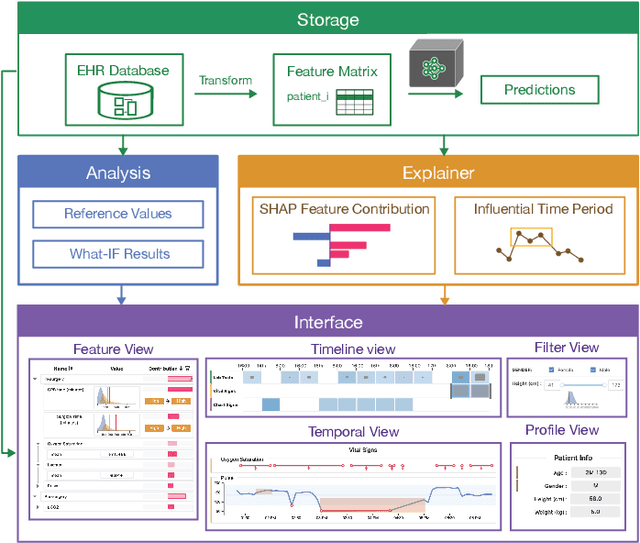
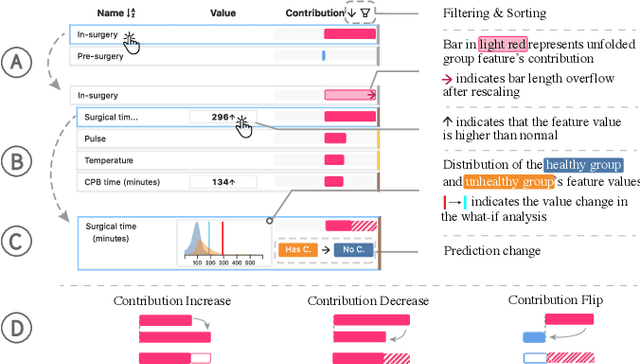
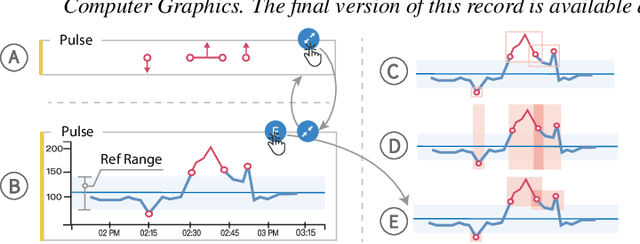
Machine learning (ML) is increasingly applied to Electronic Health Records (EHRs) to solve clinical prediction tasks. Although many ML models perform promisingly, issues with model transparency and interpretability limit their adoption in clinical practice. Directly using existing explainable ML techniques in clinical settings can be challenging. Through literature surveys and collaborations with six clinicians with an average of 17 years of clinical experience, we identified three key challenges, including clinicians' unfamiliarity with ML features, lack of contextual information, and the need for cohort-level evidence. Following an iterative design process, we further designed and developed VBridge, a visual analytics tool that seamlessly incorporates ML explanations into clinicians' decision-making workflow. The system includes a novel hierarchical display of contribution-based feature explanations and enriched interactions that connect the dots between ML features, explanations, and data. We demonstrated the effectiveness of VBridge through two case studies and expert interviews with four clinicians, showing that visually associating model explanations with patients' situational records can help clinicians better interpret and use model predictions when making clinician decisions. We further derived a list of design implications for developing future explainable ML tools to support clinical decision-making.
Understanding the Usability Challenges of Machine Learning In High-Stakes Decision Making
Mar 02, 2021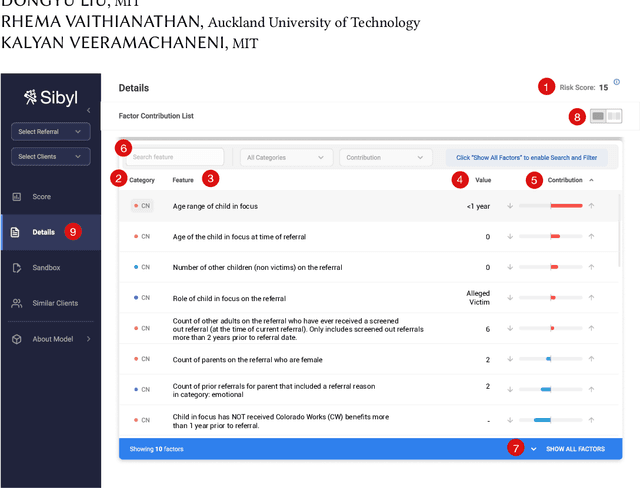

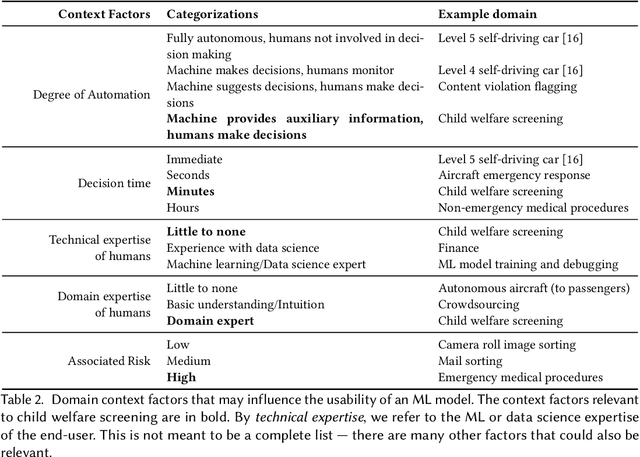
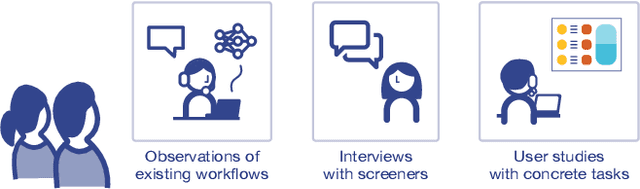
Machine learning (ML) is being applied to a diverse and ever-growing set of domains. In many cases, domain experts -- who often have no expertise in ML or data science -- are asked to use ML predictions to make high-stakes decisions. Multiple ML usability challenges can appear as result, such as lack of user trust in the model, inability to reconcile human-ML disagreement, and ethical concerns about oversimplification of complex problems to a single algorithm output. In this paper, we investigate the ML usability challenges present in the domain of child welfare screening through a series of collaborations with child welfare screeners, which included field observations, interviews, and a formal user study. Through our collaborations, we identified four key ML challenges, and honed in on one promising ML augmentation tool to address them (local factor contributions). We also composed a list of design considerations to be taken into account when developing future augmentation tools for child welfare screeners and similar domain experts.
When Does Uncertainty Matter?: Understanding the Impact of Predictive Uncertainty in ML Assisted Decision Making
Nov 13, 2020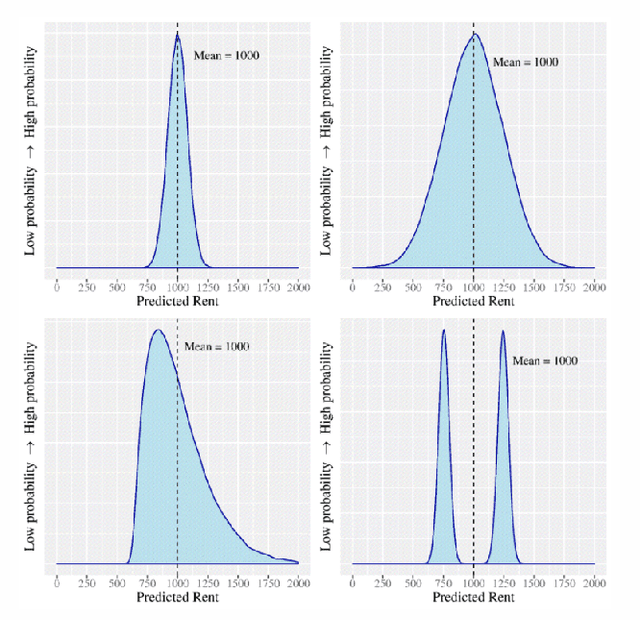

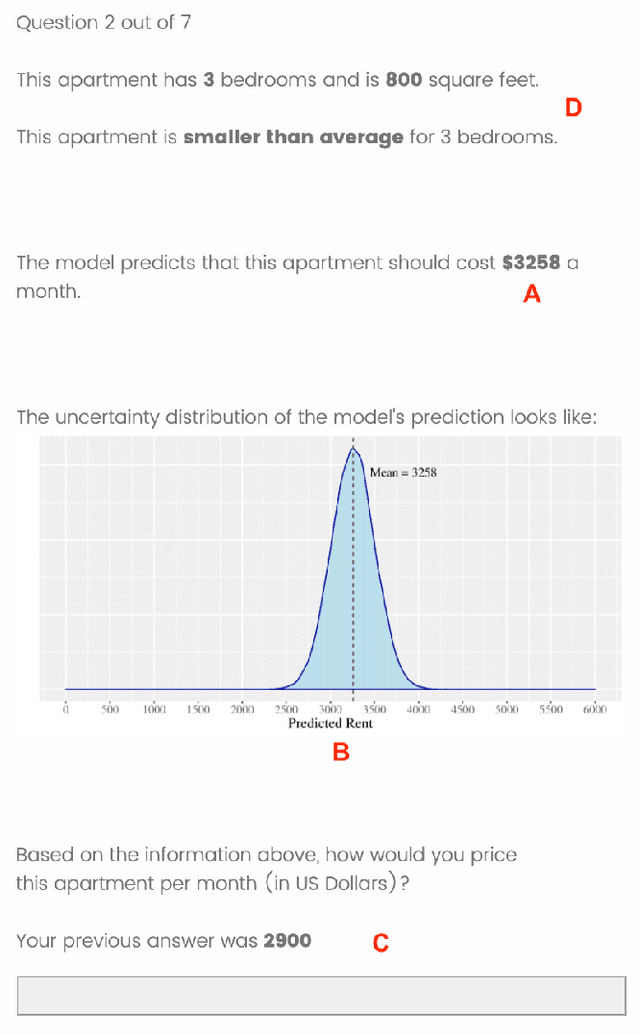
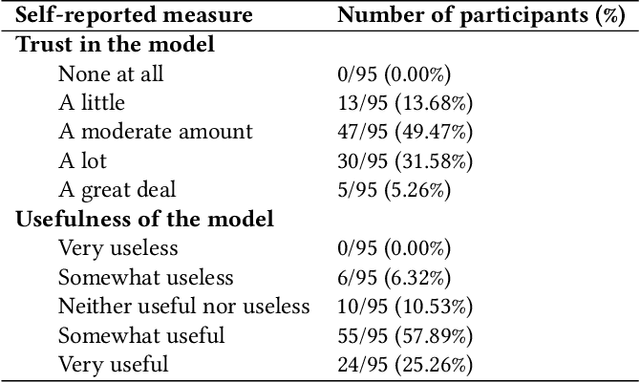
As machine learning (ML) models are increasingly being employed to assist human decision makers, it becomes critical to provide these decision makers with relevant inputs which can help them decide if and how to incorporate model predictions into their decision making. For instance, communicating the uncertainty associated with model predictions could potentially be helpful in this regard. However, there is little to no research that systematically explores if and how conveying predictive uncertainty impacts decision making. In this work, we carry out user studies to systematically assess how people respond to different types of predictive uncertainty i.e., posterior predictive distributions with different shapes and variances, in the context of ML assisted decision making. To the best of our knowledge, this work marks one of the first attempts at studying this question. Our results demonstrate that people are more likely to agree with a model prediction when they observe the corresponding uncertainty associated with the prediction. This finding holds regardless of the properties (shape or variance) of predictive uncertainty (posterior predictive distribution), suggesting that uncertainty is an effective tool for persuading humans to agree with model predictions. Furthermore, we also find that other factors such as domain expertise and familiarity with ML also play a role in determining how someone interprets and incorporates predictive uncertainty into their decision making.