 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting Fire with Fire: Adversarial Prompting to Generate a Misinformation Detection Dataset
Jan 09, 2024The recent success in language generation capabilities of large language models (LLMs), such as GPT, Bard, Llama etc., can potentially lead to concerns about their possible misuse in inducing mass agitation and communal hatred via generating fake news and spreading misinformation. Traditional means of developing a misinformation ground-truth dataset does not scale well because of the extensive manual effort required to annotate the data. In this paper, we propose an LLM-based approach of creating silver-standard ground-truth datasets for identifying misinformation. Specifically speaking, given a trusted news article, our proposed approach involves prompting LLMs to automatically generate a summarised version of the original article. The prompts in our proposed approach act as a controlling mechanism to generate specific types of factual incorrectness in the generated summaries, e.g., incorrect quantities, false attributions etc. To investigate the usefulness of this dataset, we conduct a set of experiments where we train a range of supervised models for the task of misinformation detection.
Robust Direction-of-Arrival Estimation using Array Feedback Beamforming in Low SNR Scenarios
Mar 16, 2023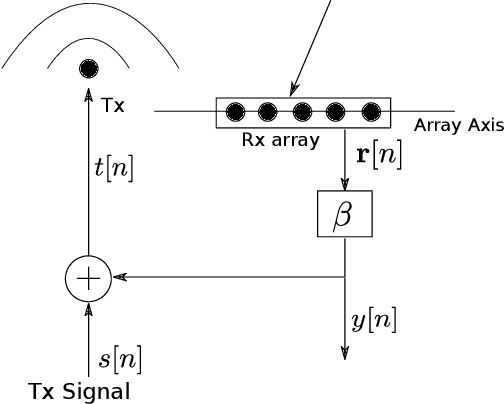
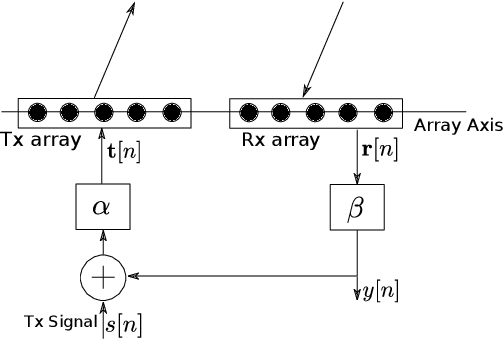
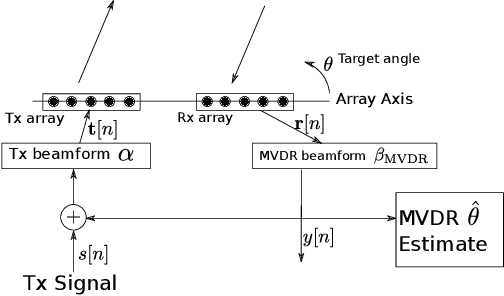
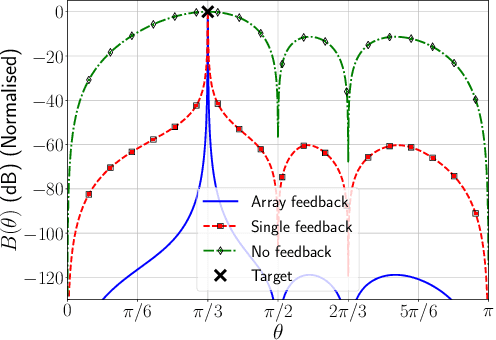
A new spatial IIR beamformer based direction-of-arrival (DoA) estimation method is proposed in this paper. We propose a retransmission based spatial feedback method for an array of transmit and receive antennas that improves the performance parameters of a beamformer viz. half-power beamwidth (HPBW), side-lobe suppression, and directivity. Through quantitative comparison we show that our approach outperforms the previous feedback beamforming approach with single transmit antenna, and the conventional beamformer. We then incorporate a retransmission based minimum variance distortionless response (MVDR) beamformer with the feedback beamforming setup. We propose two approaches and show that one approach is superior in terms of lower estimation error, and use that as DoA estimation method. We then compare this approach with Multiple Signal Classification (MUSIC) and Estimation of Parameters using Rotation Invariant Technique (ESPRIT) methods. While these previous methods perform poorly in low signal-to-noise-ratio (SNR) regime, we show that our method outperforms both at very low SNR levels. The results show that at SNR levels of -80 db to -10 db, the error is 80% less compared to that of MUSIC and ESPRIT.
Lattice All-Pass Filter based Precoder Adaptation for MIMO Wireless Channels
Feb 22, 2023Modern 5G communication systems employ multiple-input multiple-output (MIMO) in conjunction with orthogonal frequency division multiplexing (OFDM) to enhance data rates, particularly for wideband millimetre wave (mmW) applications. Since these systems use a large number of subcarriers, feeding back the estimated precoder for even a subset of subcarriers from the receiver to the transmitter is prohibitive. Moreover, such frequency domain approaches also do not exploit the predominant line-of-sight component that is present in such channels to reduce feedback. In this work, we view the precoder in the time domain as a matrix all-pass filter, and model the discrete-time precoder filter using a matrix-lattice structure that aids in reducing the overall feedback while still maintaining the desired frequency-phase delay profile. This provides an efficient precoder representation across the subcarriers using fewer coefficients, and is amenable to tracking over time with much lower feedback than past approaches. Compared to frequency domain geodesic interpolation, Givens rotation based parameterisation, and the angle-delay domain approach that depends on approximate discrete-time representation, the proposed approach yields higher achievable rates with a much lower feedback burden. Via extensive simulations over mmW channel models, we confirm the effectiveness of our claims, and show that the proposed approach can reduce the feedback burden by up to 70%.
When Does Uncertainty Matter?: Understanding the Impact of Predictive Uncertainty in ML Assisted Decision Making
Nov 13, 2020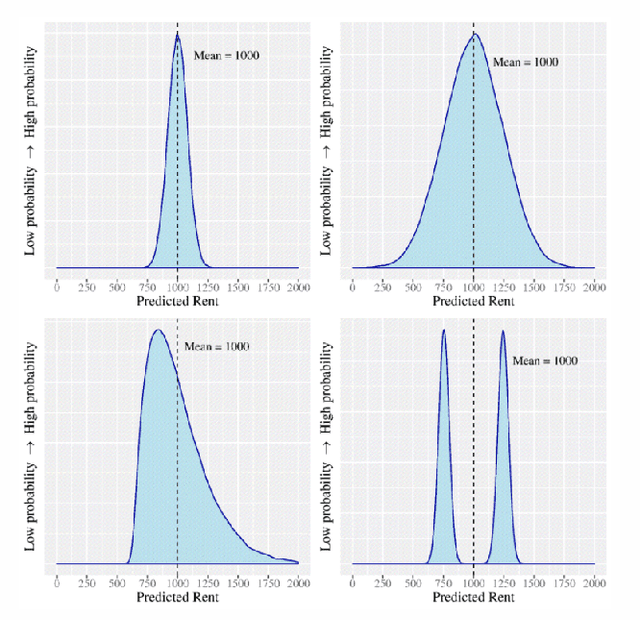

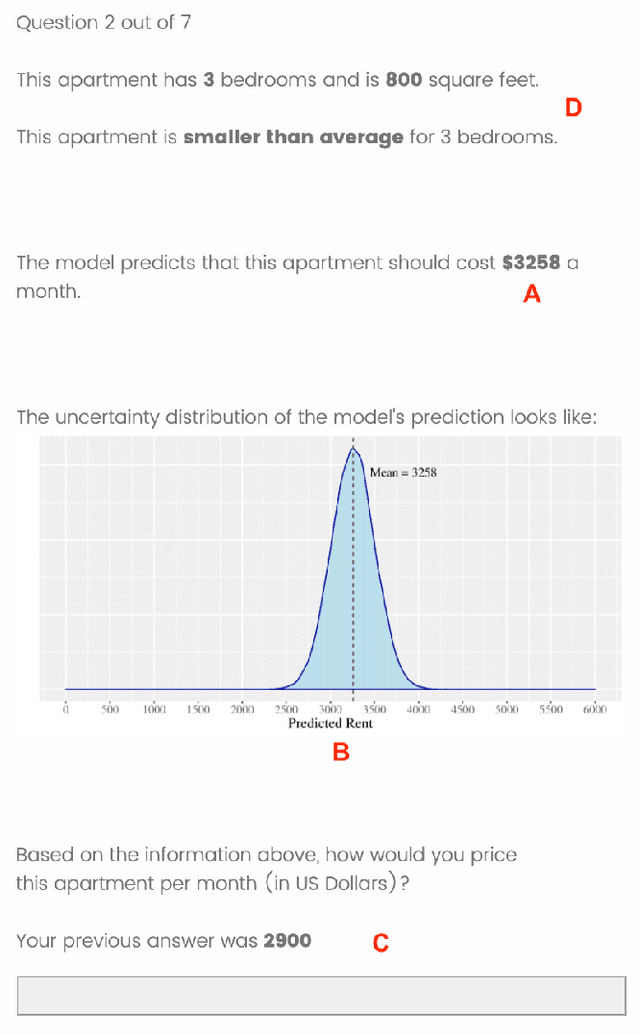
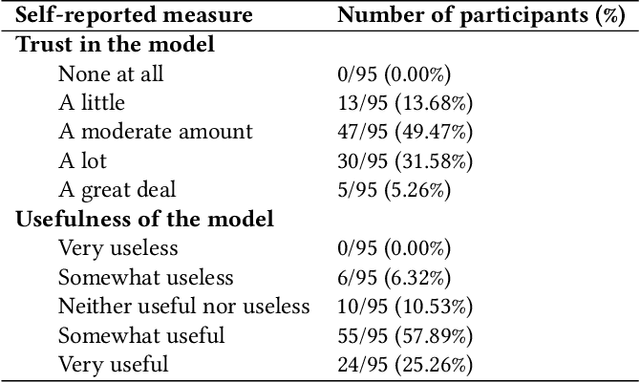
As machine learning (ML) models are increasingly being employed to assist human decision makers, it becomes critical to provide these decision makers with relevant inputs which can help them decide if and how to incorporate model predictions into their decision making. For instance, communicating the uncertainty associated with model predictions could potentially be helpful in this regard. However, there is little to no research that systematically explores if and how conveying predictive uncertainty impacts decision making. In this work, we carry out user studies to systematically assess how people respond to different types of predictive uncertainty i.e., posterior predictive distributions with different shapes and variances, in the context of ML assisted decision making. To the best of our knowledge, this work marks one of the first attempts at studying this question. Our results demonstrate that people are more likely to agree with a model prediction when they observe the corresponding uncertainty associated with the prediction. This finding holds regardless of the properties (shape or variance) of predictive uncertainty (posterior predictive distribution), suggesting that uncertainty is an effective tool for persuading humans to agree with model predictions. Furthermore, we also find that other factors such as domain expertise and familiarity with ML also play a role in determining how someone interprets and incorporates predictive uncertainty into their decision making.
Exploiting local and global performance of candidate systems for aggregation of summarization techniques
Sep 07, 2018
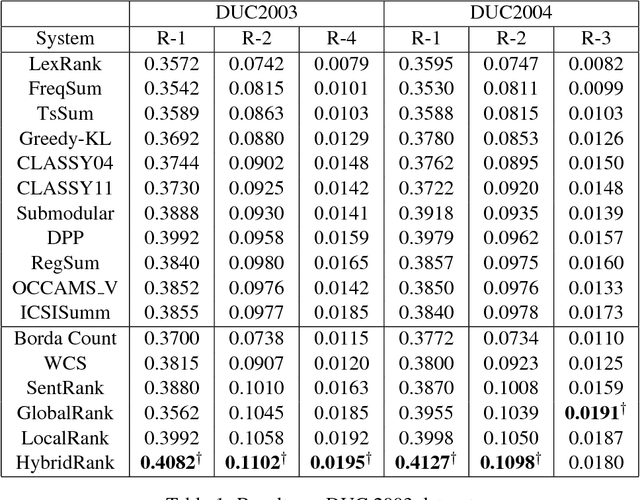
With an ever growing number of extractive summarization techniques being proposed, there is less clarity then ever about how good each system is compared to the rest. Several studies highlight the variance in performance of these systems with change in datasets or even across documents within the same corpus. An effective way to counter this variance and to make the systems more robust could be to use inputs from multiple systems when generating a summary. In the present work, we define a novel way of creating such ensemble by exploiting similarity between the content of candidate summaries to estimate their reliability. We define GlobalRank which captures the performance of a candidate system on an overall corpus and LocalRank which estimates its performance on a given document cluster. We then use these two scores to assign a weight to each individual systems, which is then used to generate the new aggregate ranking. Experiments on DUC2003 and DUC 2004 datasets show a significant improvement in terms of ROUGE score, over existing sate-of-art techniques.
Attention based Sentence Extraction from Scientific Articles using Pseudo-Labeled data
Feb 13, 2018
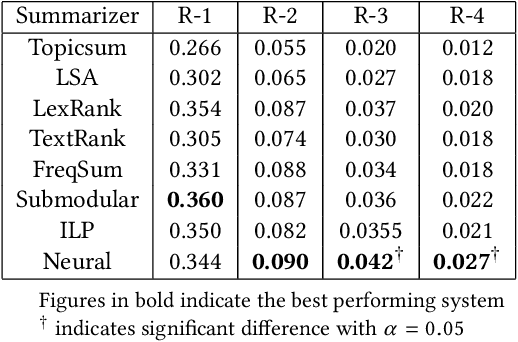
In this work, we present a weakly supervised sentence extraction technique for identifying important sentences in scientific papers that are worthy of inclusion in the abstract. We propose a new attention based deep learning architecture that jointly learns to identify important content, as well as the cue phrases that are indicative of summary worthy sentences. We propose a new context embedding technique for determining the focus of a given paper using topic models and use it jointly with an LSTM based sequence encoder to learn attention weights across the sentence words. We use a collection of articles publicly available through ACL anthology for our experiments. Our system achieves a performance that is better, in terms of several ROUGE metrics, as compared to several state of art extractive techniques. It also generates more coherent summaries and preserves the overall structure of the document.
Content based Weighted Consensus Summarization
Feb 03, 2018
Multi-document summarization has received a great deal of attention in the past couple of decades. Several approaches have been proposed, many of which perform equally well and it is becoming in- creasingly difficult to choose one particular system over another. An ensemble of such systems that is able to leverage the strengths of each individual systems can build a better and more robust summary. Despite this, few attempts have been made in this direction. In this paper, we describe a category of ensemble systems which use consensus between the candidate systems to build a better meta-summary. We highlight two major shortcomings of such systems: the inability to take into account relative performance of individual systems and overlooking content of candidate summaries in favour of the sentence rankings. We propose an alternate method, content-based weighted consensus summarization, which address these concerns. We use pseudo-relevant summaries to estimate the performance of individual candidate systems, and then use this information to generate a better aggregate ranking. Experiments on DUC 2003 and DUC 2004 datasets show that the proposed system outperforms existing consensus-based techniques by a large margin.