 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI for Software Metadata: Overview of the Information Retrieval in Software Engineering Track at FIRE 2023
Oct 27, 2023The Information Retrieval in Software Engineering (IRSE) track aims to develop solutions for automated evaluation of code comments in a machine learning framework based on human and large language model generated labels. In this track, there is a binary classification task to classify comments as useful and not useful. The dataset consists of 9048 code comments and surrounding code snippet pairs extracted from open source github C based projects and an additional dataset generated individually by teams using large language models. Overall 56 experiments have been submitted by 17 teams from various universities and software companies. The submissions have been evaluated quantitatively using the F1-Score and qualitatively based on the type of features developed, the supervised learning model used and their corresponding hyper-parameters. The labels generated from large language models increase the bias in the prediction model but lead to less over-fitted results.
Overview of the HASOC Subtrack at FIRE 2021: Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Dec 17, 2021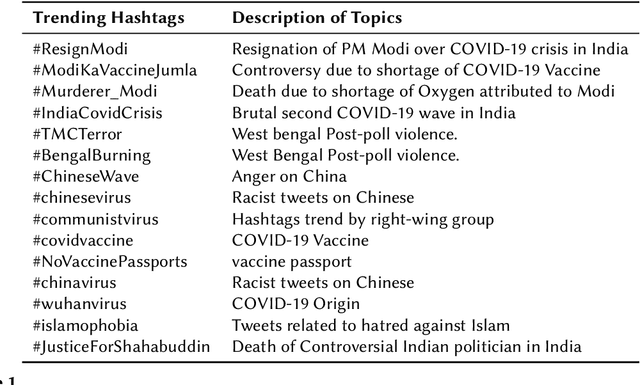
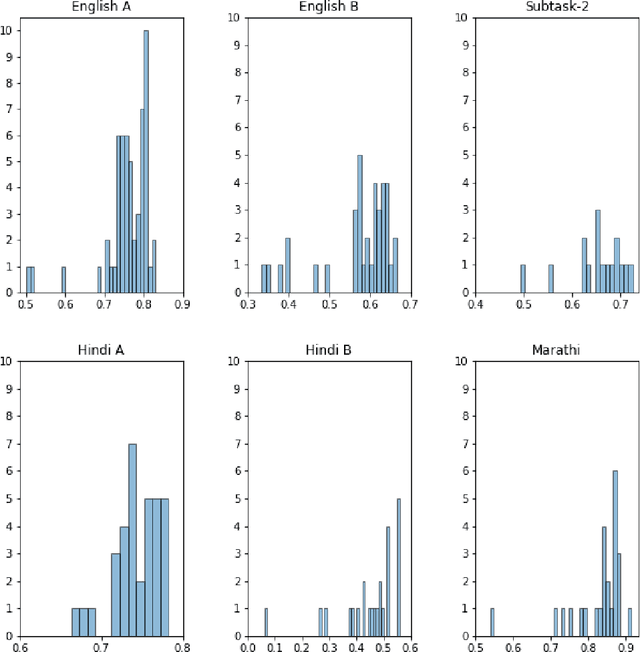
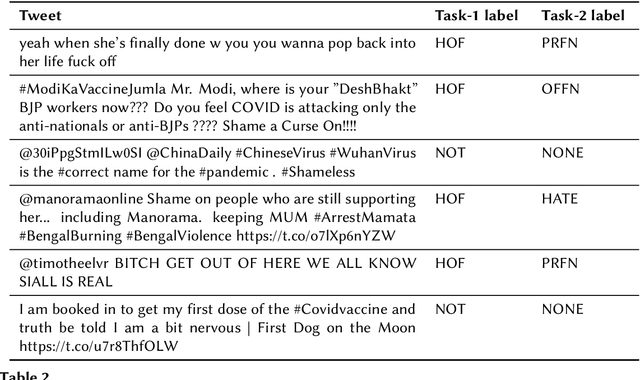
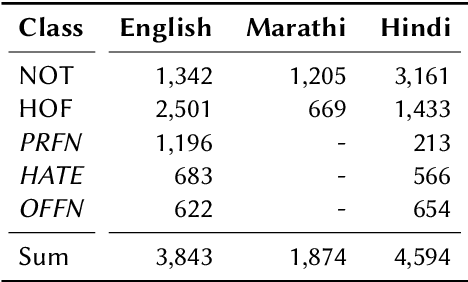
The widespread of offensive content online such as hate speech poses a growing societal problem. AI tools are necessary for supporting the moderation process at online platforms. For the evaluation of these identification tools, continuous experimentation with data sets in different languages are necessary. The HASOC track (Hate Speech and Offensive Content Identification) is dedicated to develop benchmark data for this purpose. This paper presents the HASOC subtrack for English, Hindi, and Marathi. The data set was assembled from Twitter. This subtrack has two sub-tasks. Task A is a binary classification problem (Hate and Not Offensive) offered for all three languages. Task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY offered for English and Hindi. Overall, 652 runs were submitted by 65 teams. The performance of the best classification algorithms for task A are F1 measures 0.91, 0.78 and 0.83 for Marathi, Hindi and English, respectively. This overview presents the tasks and the data development as well as the detailed results. The systems submitted to the competition applied a variety of technologies. The best performing algorithms were mainly variants of transformer architectures.
LawSum: A weakly supervised approach for Indian Legal Document Summarization
Oct 05, 2021


Unlike the courts in western countries, public records of Indian judiciary are completely unstructured and noisy. No large scale publicly available annotated datasets of Indian legal documents exist till date. This limits the scope for legal analytics research. In this work, we propose a new dataset consisting of over 10,000 judgements delivered by the supreme court of India and their corresponding hand written summaries. The proposed dataset is pre-processed by normalising common legal abbreviations, handling spelling variations in named entities, handling bad punctuations and accurate sentence tokenization. Each sentence is tagged with their rhetorical roles. We also annotate each judgement with several attributes like date, names of the plaintiffs, defendants and the people representing them, judges who delivered the judgement, acts/statutes that are cited and the most common citations used to refer the judgement. Further, we propose an automatic labelling technique for identifying sentences which have summary worthy information. We demonstrate that this auto labeled data can be used effectively to train a weakly supervised sentence extractor with high accuracy. Some possible applications of this dataset besides legal document summarization can be in retrieval, citation analysis and prediction of decisions by a particular judge.
Overview of the HASOC track at FIRE 2020: Hate Speech and Offensive Content Identification in Indo-European Languages
Aug 12, 2021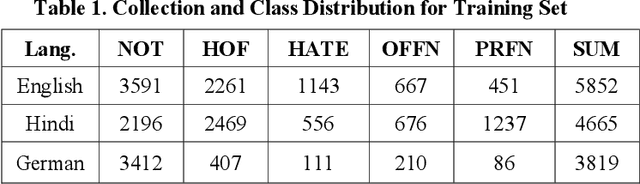
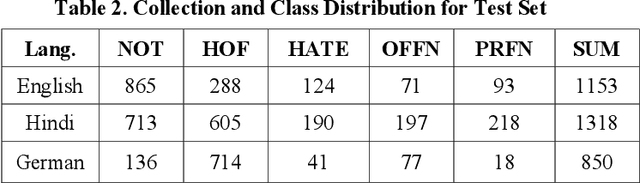
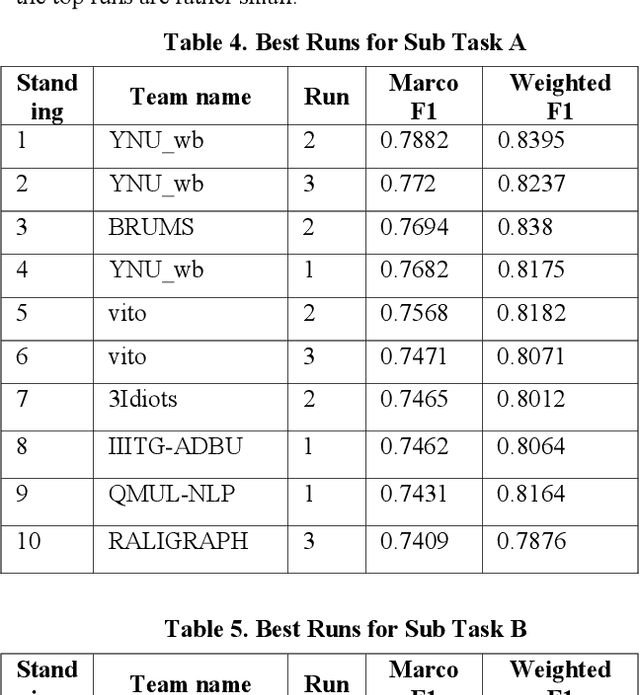
With the growth of social media, the spread of hate speech is also increasing rapidly. Social media are widely used in many countries. Also Hate Speech is spreading in these countries. This brings a need for multilingual Hate Speech detection algorithms. Much research in this area is dedicated to English at the moment. The HASOC track intends to provide a platform to develop and optimize Hate Speech detection algorithms for Hindi, German and English. The dataset is collected from a Twitter archive and pre-classified by a machine learning system. HASOC has two sub-task for all three languages: task A is a binary classification problem (Hate and Not Offensive) while task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY. Overall, 252 runs were submitted by 40 teams. The performance of the best classification algorithms for task A are F1 measures of 0.51, 0.53 and 0.52 for English, Hindi, and German, respectively. For task B, the best classification algorithms achieved F1 measures of 0.26, 0.33 and 0.29 for English, Hindi, and German, respectively. This article presents the tasks and the data development as well as the results. The best performing algorithms were mainly variants of the transformer architecture BERT. However, also other systems were applied with good success
An Empirical Evaluation of Text Representation Schemes on Multilingual Social Web to Filter the Textual Aggression
Apr 16, 2019
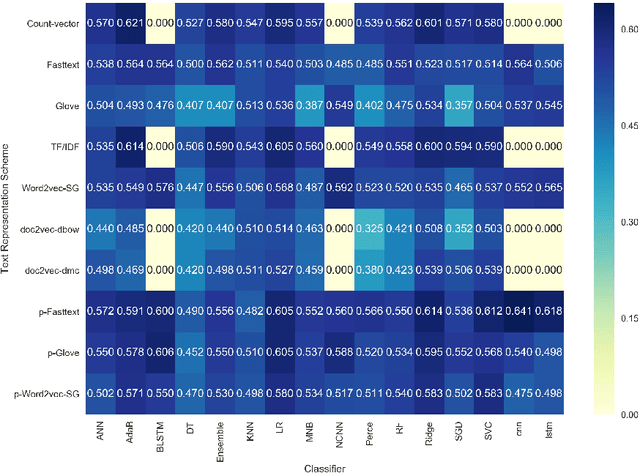

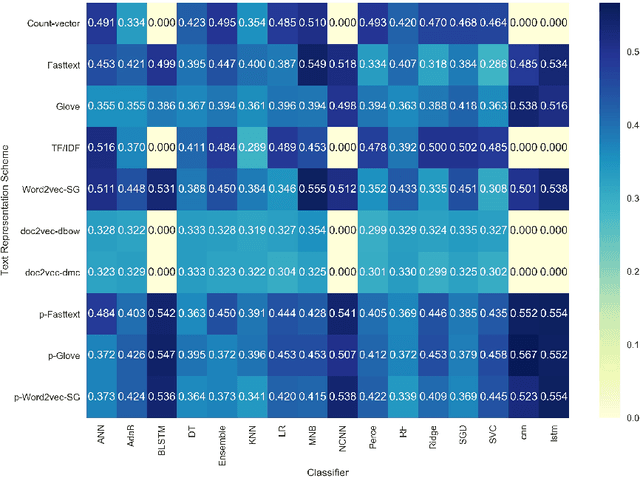
This paper attempt to study the effectiveness of text representation schemes on two tasks namely: User Aggression and Fact Detection from the social media contents. In User Aggression detection, The aim is to identify the level of aggression from the contents generated in the Social media and written in the English, Devanagari Hindi and Romanized Hindi. Aggression levels are categorized into three predefined classes namely: `Non-aggressive`, `Overtly Aggressive`, and `Covertly Aggressive`. During the disaster-related incident, Social media like, Twitter is flooded with millions of posts. In such emergency situations, identification of factual posts is important for organizations involved in the relief operation. We anticipated this problem as a combination of classification and Ranking problem. This paper presents a comparison of various text representation scheme based on BoW techniques, distributed word/sentence representation, transfer learning on classifiers. Weighted $F_1$ score is used as a primary evaluation metric. Results show that text representation using BoW performs better than word embedding on machine learning classifiers. While pre-trained Word embedding techniques perform better on classifiers based on deep neural net. Recent transfer learning model like ELMO, ULMFiT are fine-tuned for the Aggression classification task. However, results are not at par with pre-trained word embedding model. Overall, word embedding using fastText produce best weighted $F_1$-score than Word2Vec and Glove. Results are further improved using pre-trained vector model. Statistical significance tests are employed to ensure the significance of the classification results. In the case of lexically different test Dataset, other than training Dataset, deep neural models are more robust and perform substantially better than machine learning classifiers.
Exploiting local and global performance of candidate systems for aggregation of summarization techniques
Sep 07, 2018
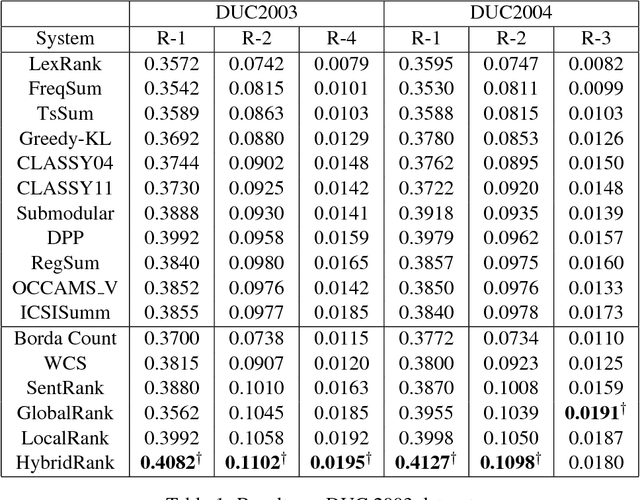
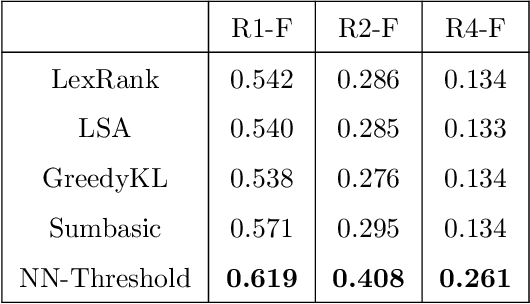
With an ever growing number of extractive summarization techniques being proposed, there is less clarity then ever about how good each system is compared to the rest. Several studies highlight the variance in performance of these systems with change in datasets or even across documents within the same corpus. An effective way to counter this variance and to make the systems more robust could be to use inputs from multiple systems when generating a summary. In the present work, we define a novel way of creating such ensemble by exploiting similarity between the content of candidate summaries to estimate their reliability. We define GlobalRank which captures the performance of a candidate system on an overall corpus and LocalRank which estimates its performance on a given document cluster. We then use these two scores to assign a weight to each individual systems, which is then used to generate the new aggregate ranking. Experiments on DUC2003 and DUC 2004 datasets show a significant improvement in terms of ROUGE score, over existing sate-of-art techniques.
Attention based Sentence Extraction from Scientific Articles using Pseudo-Labeled data
Feb 13, 2018
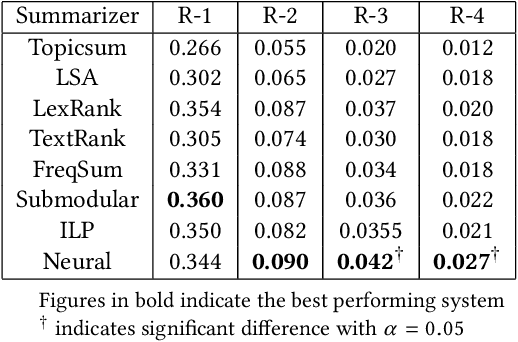
In this work, we present a weakly supervised sentence extraction technique for identifying important sentences in scientific papers that are worthy of inclusion in the abstract. We propose a new attention based deep learning architecture that jointly learns to identify important content, as well as the cue phrases that are indicative of summary worthy sentences. We propose a new context embedding technique for determining the focus of a given paper using topic models and use it jointly with an LSTM based sequence encoder to learn attention weights across the sentence words. We use a collection of articles publicly available through ACL anthology for our experiments. Our system achieves a performance that is better, in terms of several ROUGE metrics, as compared to several state of art extractive techniques. It also generates more coherent summaries and preserves the overall structure of the document.
Content based Weighted Consensus Summarization
Feb 03, 2018
Multi-document summarization has received a great deal of attention in the past couple of decades. Several approaches have been proposed, many of which perform equally well and it is becoming in- creasingly difficult to choose one particular system over another. An ensemble of such systems that is able to leverage the strengths of each individual systems can build a better and more robust summary. Despite this, few attempts have been made in this direction. In this paper, we describe a category of ensemble systems which use consensus between the candidate systems to build a better meta-summary. We highlight two major shortcomings of such systems: the inability to take into account relative performance of individual systems and overlooking content of candidate summaries in favour of the sentence rankings. We propose an alternate method, content-based weighted consensus summarization, which address these concerns. We use pseudo-relevant summaries to estimate the performance of individual candidate systems, and then use this information to generate a better aggregate ranking. Experiments on DUC 2003 and DUC 2004 datasets show that the proposed system outperforms existing consensus-based techniques by a large margin.
Re-evaluating the need for Modelling Term-Dependence in Text Classification Problems
Oct 25, 2017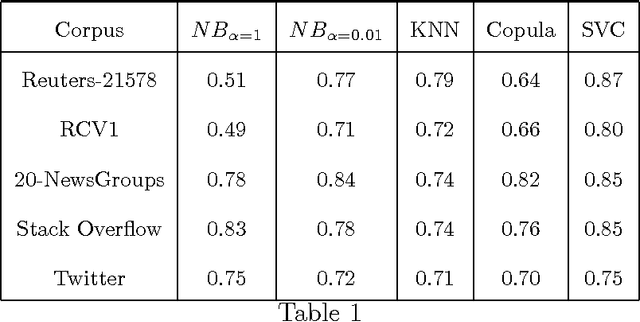
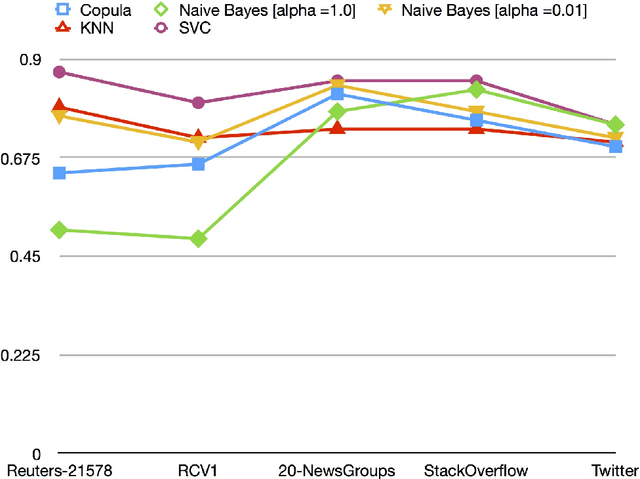
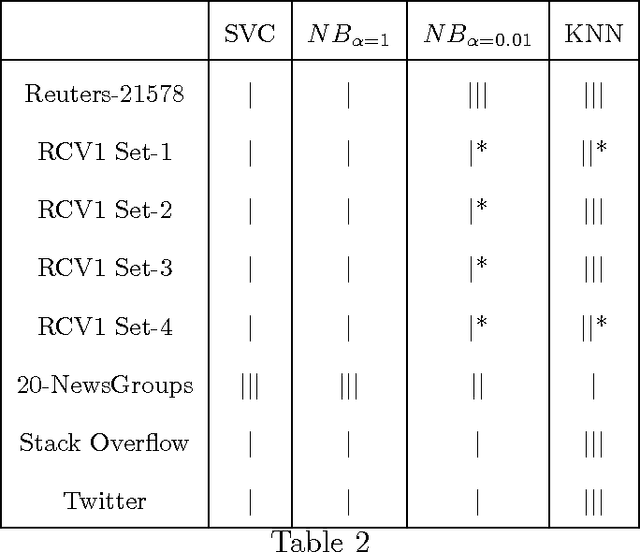
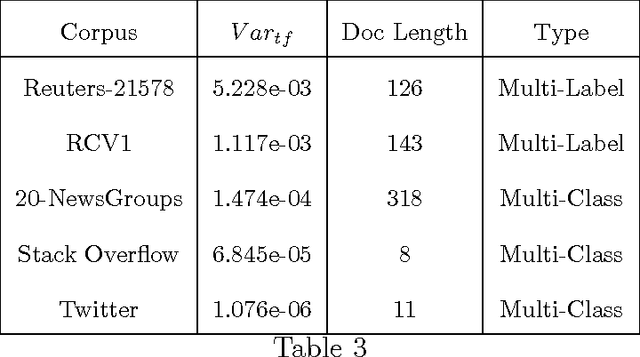
A substantial amount of research has been carried out in developing machine learning algorithms that account for term dependence in text classification. These algorithms offer acceptable performance in most cases but they are associated with a substantial cost. They require significantly greater resources to operate. This paper argues against the justification of the higher costs of these algorithms, based on their performance in text classification problems. In order to prove the conjecture, the performance of one of the best dependence models is compared to several well established algorithms in text classification. A very specific collection of datasets have been designed, which would best reflect the disparity in the nature of text data, that are present in real world applications. The results show that even one of the best term dependence models, performs decent at best when compared to other independence models. Coupled with their substantially greater requirement for hardware resources for operation, this makes them an impractical choice for being used in real world scenarios.
Formal Ontology Learning on Factual IS-A Corpus in English using Description Logics
Mar 08, 2016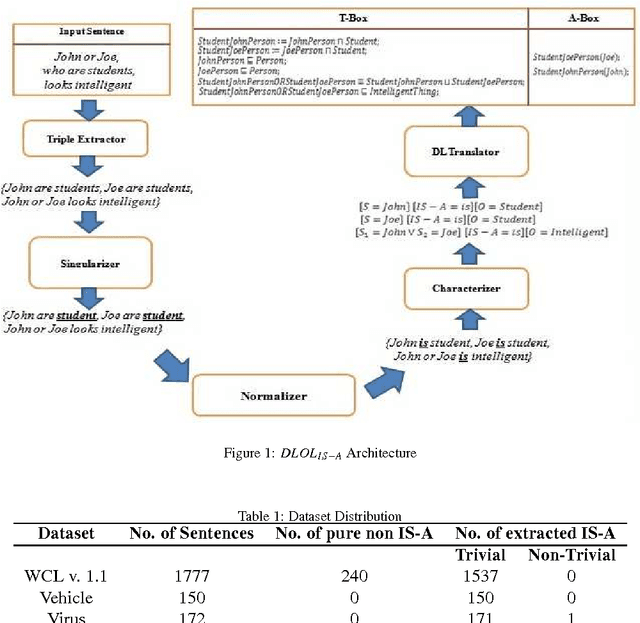

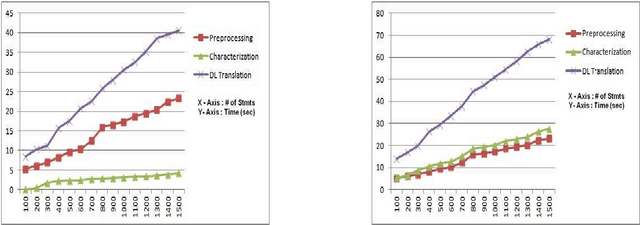
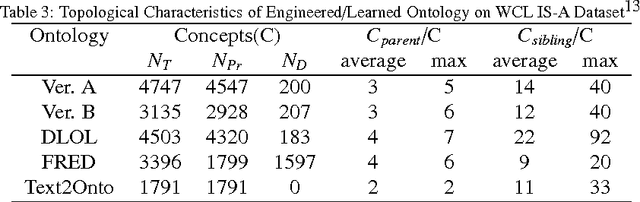
Ontology Learning (OL) is the computational task of generating a knowledge base in the form of an ontology given an unstructured corpus whose content is in natural language (NL). Several works can be found in this area most of which are limited to statistical and lexico-syntactic pattern matching based techniques Light-Weight OL. These techniques do not lead to very accurate learning mostly because of several linguistic nuances in NL. Formal OL is an alternative (less explored) methodology were deep linguistics analysis is made using theory and tools found in computational linguistics to generate formal axioms and definitions instead simply inducing a taxonomy. In this paper we propose "Description Logic (DL)" based formal OL framework for learning factual IS-A type sentences in English. We claim that semantic construction of IS-A sentences is non trivial. Hence, we also claim that such sentences requires special studies in the context of OL before any truly formal OL can be proposed. We introduce a learner tool, called DLOL_IS-A, that generated such ontologies in the owl format. We have adopted "Gold Standard" based OL evaluation on IS-A rich WCL v.1.1 dataset and our own Community representative IS-A dataset. We observed significant improvement of DLOL_IS-A when compared to the light-weight OL tool Text2Onto and formal OL tool FRED.