 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Context Effects in Similarity Judgements in Large Language Models
Aug 20, 2024



Large Language Models (LLMs) have revolutionised the capability of AI models in comprehending and generating natural language text. They are increasingly being used to empower and deploy agents in real-world scenarios, which make decisions and take actions based on their understanding of the context. Therefore researchers, policy makers and enterprises alike are working towards ensuring that the decisions made by these agents align with human values and user expectations. That being said, human values and decisions are not always straightforward to measure and are subject to different cognitive biases. There is a vast section of literature in Behavioural Science which studies biases in human judgements. In this work we report an ongoing investigation on alignment of LLMs with human judgements affected by order bias. Specifically, we focus on a famous human study which showed evidence of order effects in similarity judgements, and replicate it with various popular LLMs. We report the different settings where LLMs exhibit human-like order effect bias and discuss the implications of these findings to inform the design and development of LLM based applications.
Towards a Theoretical Understanding of Two-Stage Recommender Systems
Feb 23, 2024Production-grade recommender systems rely heavily on a large-scale corpus used by online media services, including Netflix, Pinterest, and Amazon. These systems enrich recommendations by learning users' and items' embeddings projected in a low-dimensional space with two-stage models (two deep neural networks), which facilitate their embedding constructs to predict users' feedback associated with items. Despite its popularity for recommendations, its theoretical behaviors remain comprehensively unexplored. We study the asymptotic behaviors of the two-stage recommender that entail a strong convergence to the optimal recommender system. We establish certain theoretical properties and statistical assurance of the two-stage recommender. In addition to asymptotic behaviors, we demonstrate that the two-stage recommender system attains faster convergence by relying on the intrinsic dimensions of the input features. Finally, we show numerically that the two-stage recommender enables encapsulating the impacts of items' and users' attributes on ratings, resulting in better performance compared to existing methods conducted using synthetic and real-world data experiments.
FakeClaim: A Multiple Platform-driven Dataset for Identification of Fake News on 2023 Israel-Hamas War
Jan 29, 2024



We contribute the first publicly available dataset of factual claims from different platforms and fake YouTube videos on the 2023 Israel-Hamas war for automatic fake YouTube video classification. The FakeClaim data is collected from 60 fact-checking organizations in 30 languages and enriched with metadata from the fact-checking organizations curated by trained journalists specialized in fact-checking. Further, we classify fake videos within the subset of YouTube videos using textual information and user comments. We used a pre-trained model to classify each video with different feature combinations. Our best-performing fine-tuned language model, Universal Sentence Encoder (USE), achieves a Macro F1 of 87\%, which shows that the trained model can be helpful for debunking fake videos using the comments from the user discussion. The dataset is available on Github\footnote{https://github.com/Gautamshahi/FakeClaim}
Towards Subject Agnostic Affective Emotion Recognition
Oct 20, 2023



This paper focuses on affective emotion recognition, aiming to perform in the subject-agnostic paradigm based on EEG signals. However, EEG signals manifest subject instability in subject-agnostic affective Brain-computer interfaces (aBCIs), which led to the problem of distributional shift. Furthermore, this problem is alleviated by approaches such as domain generalisation and domain adaptation. Typically, methods based on domain adaptation confer comparatively better results than the domain generalisation methods but demand more computational resources given new subjects. We propose a novel framework, meta-learning based augmented domain adaptation for subject-agnostic aBCIs. Our domain adaptation approach is augmented through meta-learning, which consists of a recurrent neural network, a classifier, and a distributional shift controller based on a sum-decomposable function. Also, we present that a neural network explicating a sum-decomposable function can effectively estimate the divergence between varied domains. The network setting for augmented domain adaptation follows meta-learning and adversarial learning, where the controller promptly adapts to new domains employing the target data via a few self-adaptation steps in the test phase. Our proposed approach is shown to be effective in experiments on a public aBICs dataset and achieves similar performance to state-of-the-art domain adaptation methods while avoiding the use of additional computational resources.
A Model-Agnostic Framework for Recommendation via Interest-aware Item Embeddings
Aug 17, 2023Item representation holds significant importance in recommendation systems, which encompasses domains such as news, retail, and videos. Retrieval and ranking models utilise item representation to capture the user-item relationship based on user behaviours. While existing representation learning methods primarily focus on optimising item-based mechanisms, such as attention and sequential modelling. However, these methods lack a modelling mechanism to directly reflect user interests within the learned item representations. Consequently, these methods may be less effective in capturing user interests indirectly. To address this challenge, we propose a novel Interest-aware Capsule network (IaCN) recommendation model, a model-agnostic framework that directly learns interest-oriented item representations. IaCN serves as an auxiliary task, enabling the joint learning of both item-based and interest-based representations. This framework adopts existing recommendation models without requiring substantial redesign. We evaluate the proposed approach on benchmark datasets, exploring various scenarios involving different deep neural networks, behaviour sequence lengths, and joint learning ratios of interest-oriented item representations. Experimental results demonstrate significant performance enhancements across diverse recommendation models, validating the effectiveness of our approach.
Lightweight Adaptation of Neural Language Models via Subspace Embedding
Aug 16, 2023Traditional neural word embeddings are usually dependent on a richer diversity of vocabulary. However, the language models recline to cover major vocabularies via the word embedding parameters, in particular, for multilingual language models that generally cover a significant part of their overall learning parameters. In this work, we present a new compact embedding structure to reduce the memory footprint of the pre-trained language models with a sacrifice of up to 4% absolute accuracy. The embeddings vectors reconstruction follows a set of subspace embeddings and an assignment procedure via the contextual relationship among tokens from pre-trained language models. The subspace embedding structure calibrates to masked language models, to evaluate our compact embedding structure on similarity and textual entailment tasks, sentence and paraphrase tasks. Our experimental evaluation shows that the subspace embeddings achieve compression rates beyond 99.8% in comparison with the original embeddings for the language models on XNLI and GLUE benchmark suites.
A Novel Deep Learning based Model for Erythrocytes Classification and Quantification in Sickle Cell Disease
May 02, 2023The shape of erythrocytes or red blood cells is altered in several pathological conditions. Therefore, identifying and quantifying different erythrocyte shapes can help diagnose various diseases and assist in designing a treatment strategy. Machine Learning (ML) can be efficiently used to identify and quantify distorted erythrocyte morphologies. In this paper, we proposed a customized deep convolutional neural network (CNN) model to classify and quantify the distorted and normal morphology of erythrocytes from the images taken from the blood samples of patients suffering from Sickle cell disease ( SCD). We chose SCD as a model disease condition due to the presence of diverse erythrocyte morphologies in the blood samples of SCD patients. For the analysis, we used 428 raw microscopic images of SCD blood samples and generated the dataset consisting of 10, 377 single-cell images. We focused on three well-defined erythrocyte shapes, including discocytes, oval, and sickle. We used 18 layered deep CNN architecture to identify and quantify these shapes with 81% accuracy, outperforming other models. We also used SHAP and LIME for further interpretability. The proposed model can be helpful for the quick and accurate analysis of SCD blood samples by the clinicians and help them make the right decision for better management of SCD.
Overview of the HASOC Subtrack at FIRE 2021: Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Dec 17, 2021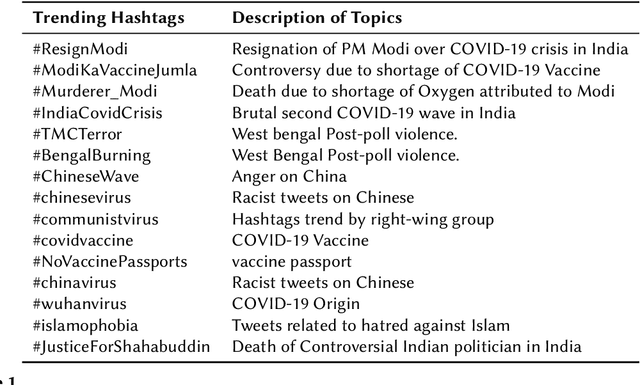
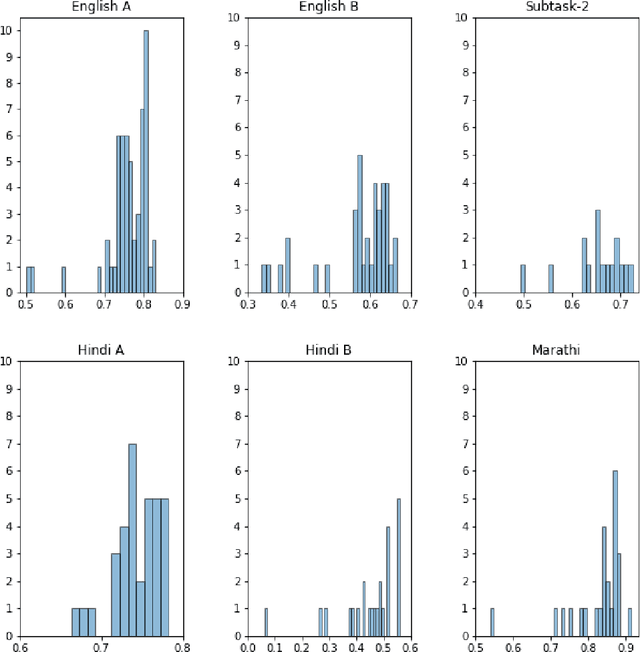
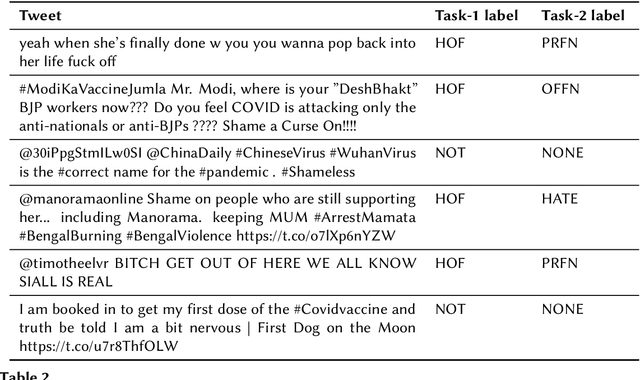
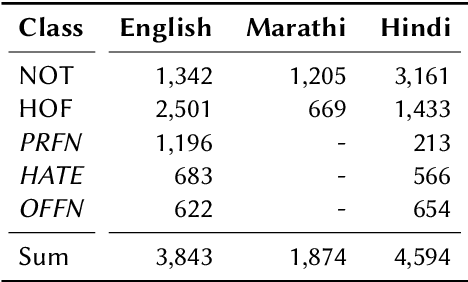
The widespread of offensive content online such as hate speech poses a growing societal problem. AI tools are necessary for supporting the moderation process at online platforms. For the evaluation of these identification tools, continuous experimentation with data sets in different languages are necessary. The HASOC track (Hate Speech and Offensive Content Identification) is dedicated to develop benchmark data for this purpose. This paper presents the HASOC subtrack for English, Hindi, and Marathi. The data set was assembled from Twitter. This subtrack has two sub-tasks. Task A is a binary classification problem (Hate and Not Offensive) offered for all three languages. Task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY offered for English and Hindi. Overall, 652 runs were submitted by 65 teams. The performance of the best classification algorithms for task A are F1 measures 0.91, 0.78 and 0.83 for Marathi, Hindi and English, respectively. This overview presents the tasks and the data development as well as the detailed results. The systems submitted to the competition applied a variety of technologies. The best performing algorithms were mainly variants of transformer architectures.
Overview of the HASOC track at FIRE 2020: Hate Speech and Offensive Content Identification in Indo-European Languages
Aug 12, 2021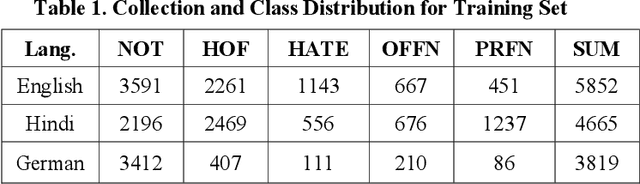
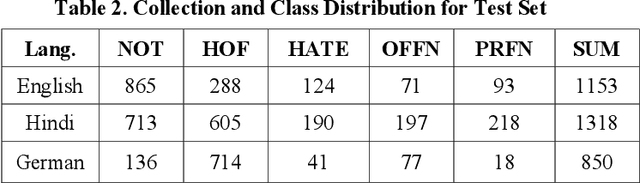
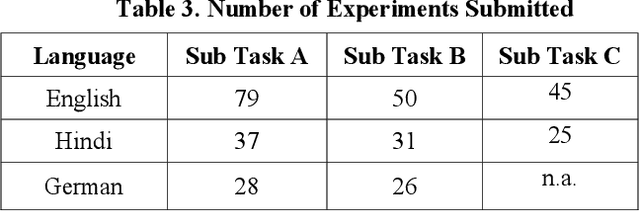
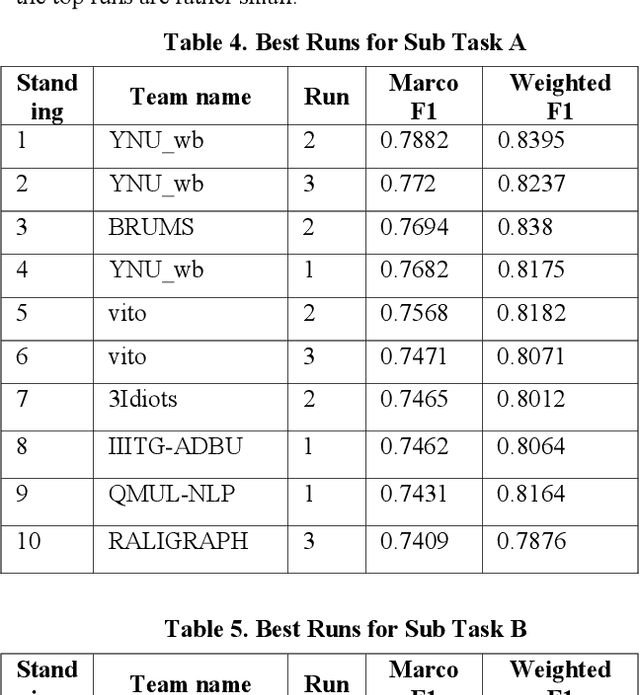
With the growth of social media, the spread of hate speech is also increasing rapidly. Social media are widely used in many countries. Also Hate Speech is spreading in these countries. This brings a need for multilingual Hate Speech detection algorithms. Much research in this area is dedicated to English at the moment. The HASOC track intends to provide a platform to develop and optimize Hate Speech detection algorithms for Hindi, German and English. The dataset is collected from a Twitter archive and pre-classified by a machine learning system. HASOC has two sub-task for all three languages: task A is a binary classification problem (Hate and Not Offensive) while task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY. Overall, 252 runs were submitted by 40 teams. The performance of the best classification algorithms for task A are F1 measures of 0.51, 0.53 and 0.52 for English, Hindi, and German, respectively. For task B, the best classification algorithms achieved F1 measures of 0.26, 0.33 and 0.29 for English, Hindi, and German, respectively. This article presents the tasks and the data development as well as the results. The best performing algorithms were mainly variants of the transformer architecture BERT. However, also other systems were applied with good success
Reinforcement Learning-driven Information Seeking: A Quantum Probabilistic Approach
Aug 05, 2020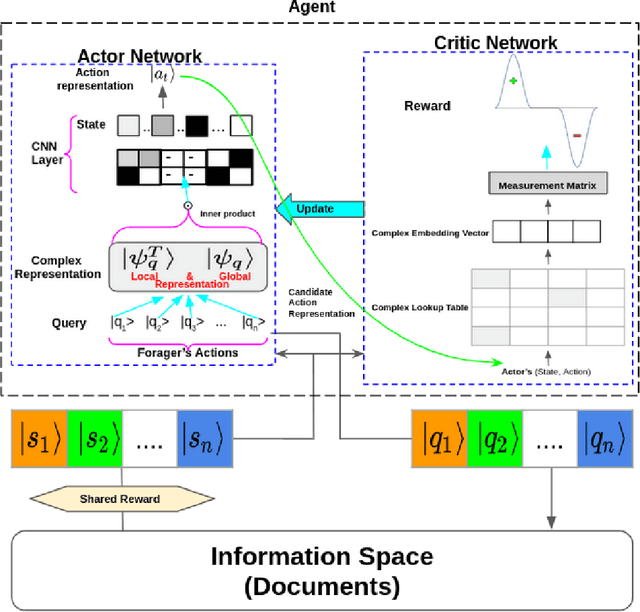
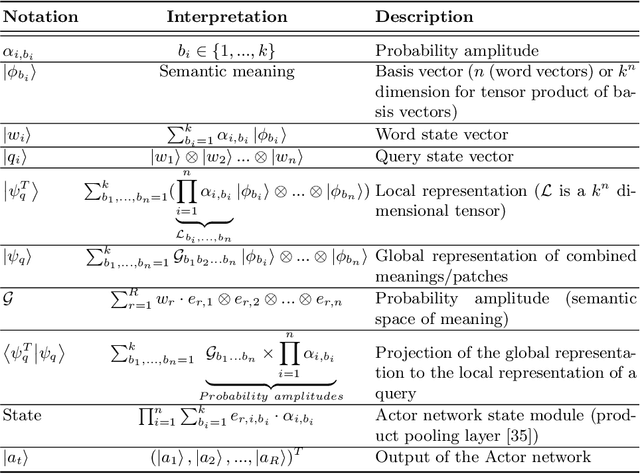
Understanding an information forager's actions during interaction is very important for the study of interactive information retrieval. Although information spread in uncertain information space is substantially complex due to the high entanglement of users interacting with information objects~(text, image, etc.). However, an information forager, in general, accompanies a piece of information (information diet) while searching (or foraging) alternative contents, typically subject to decisive uncertainty. Such types of uncertainty are analogous to measurements in quantum mechanics which follow the uncertainty principle. In this paper, we discuss information seeking as a reinforcement learning task. We then present a reinforcement learning-based framework to model forager exploration that treats the information forager as an agent to guide their behaviour. Also, our framework incorporates the inherent uncertainty of the foragers' action using the mathematical formalism of quantum mechanics.