 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Categorization of Scientific Texts with In-Context Learning and Prompt-Chaining in Large Language Models
Apr 25, 2026The relentless expansion of scientific literature presents significant challenges for navigation and knowledge discovery. Within Research Information Retrieval, established tasks such as text summarization and classification remain crucial for enabling researchers and practitioners to effectively navigate this vast landscape, so that efforts have increasingly been focused on developing advanced research information systems. These systems aim not only to provide standard keyword-based search functionalities but also to incorporate capabilities for automatic content categorization within knowledge-intensive organizations across academia and industry. This study systematically evaluates the performance of off-the-shelf Large Language Models (LLMs) in analyzing scientific texts according to a given classification scheme. We utilized the hierarchical ORKG taxonomy as a classification framework, employing the FORC dataset as ground truth. We investigated the effectiveness of advanced prompt engineering strategies, namely In-Context Learning (ICL) and Prompt Chaining, and experimentally explored the influence of the LLMs' temperature hyperparameter on classification accuracy. Our experiments demonstrate that Prompt Chaining yields superior classification accuracy compared to pure ICL, particularly when applied to the nested structure of the ORKG taxonomy. LLMs with prompt chaining outperform the state-of-the-art models for domain (1st level) prediction and show even better performance for subject (2nd level) prediction compared to the older BERT model. However, LLMs are not yet able to perform well in classifying the topic (3rd level) of research areas based on this specific hierarchical taxonomy, as they only reach about 50% accuracy even with prompt chaining.
Enhancing Research Information Systems with Identification of Domain Experts
Mar 28, 2024Research organisations and their research outputs have been growing considerably in the past decades. This large body of knowledge attracts various stakeholders, e.g., for knowledge sharing, technology transfer, or potential collaborations. However, due to the large amount of complex knowledge created, traditional methods of manually curating catalogues are often out of time, imprecise, and cumbersome. Finding domain experts and knowledge within any larger organisation, scientific and also industrial, has thus become a serious challenge. Hence, exploring an institutions domain knowledge and finding its experts can only be solved by an automated solution. This work presents the scheme of an automated approach for identifying scholarly experts based on their publications and, prospectively, their teaching materials. Based on a search engine, this approach is currently being implemented for two universities, for which some examples are presented. The proposed system will be helpful for finding peer researchers as well as starting points for knowledge exploitation and technology transfer. As the system is designed in a scalable manner, it can easily include additional institutions and hence provide a broader coverage of research facilities in the future.
TweetInfo: An Interactive System to Mitigate Online Harm
Mar 03, 2024The increase in active users on social networking sites (SNSs) has also observed an increase in harmful content on social media sites. Harmful content is described as an inappropriate activity to harm or deceive an individual or a group of users. Alongside existing methods to detect misinformation and hate speech, users still need to be well-informed about the harmfulness of the content on SNSs. This study proposes a user-interactive system TweetInfo for mitigating the consumption of harmful content by providing metainformation about the posts. It focuses on two types of harmful content: hate speech and misinformation. TweetInfo provides insights into tweets by doing content analysis. Based on previous research, we have selected a list of metainformation. We offer the option to filter content based on metainformation Bot, Hate Speech, Misinformation, Verified Account, Sentiment, Tweet Category, Language. The proposed user interface allows customising the user's timeline to mitigate harmful content. This study present the demo version of the propose user interface of TweetInfo.
FakeClaim: A Multiple Platform-driven Dataset for Identification of Fake News on 2023 Israel-Hamas War
Jan 29, 2024



We contribute the first publicly available dataset of factual claims from different platforms and fake YouTube videos on the 2023 Israel-Hamas war for automatic fake YouTube video classification. The FakeClaim data is collected from 60 fact-checking organizations in 30 languages and enriched with metadata from the fact-checking organizations curated by trained journalists specialized in fact-checking. Further, we classify fake videos within the subset of YouTube videos using textual information and user comments. We used a pre-trained model to classify each video with different feature combinations. Our best-performing fine-tuned language model, Universal Sentence Encoder (USE), achieves a Macro F1 of 87\%, which shows that the trained model can be helpful for debunking fake videos using the comments from the user discussion. The dataset is available on Github\footnote{https://github.com/Gautamshahi/FakeClaim}
Overview of the HASOC Subtrack at FIRE 2021: Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Dec 17, 2021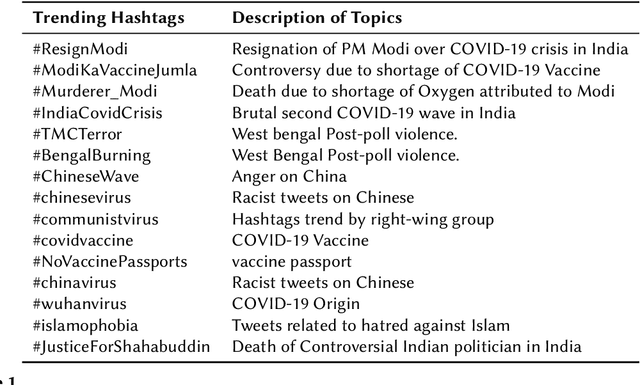
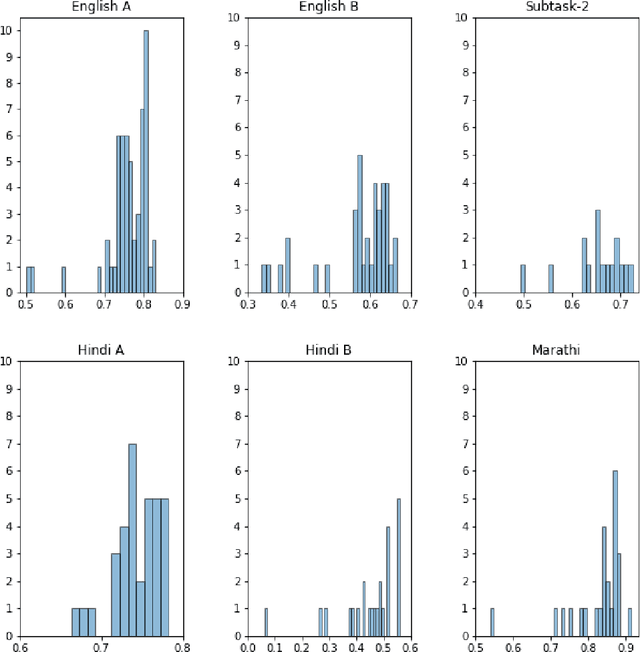
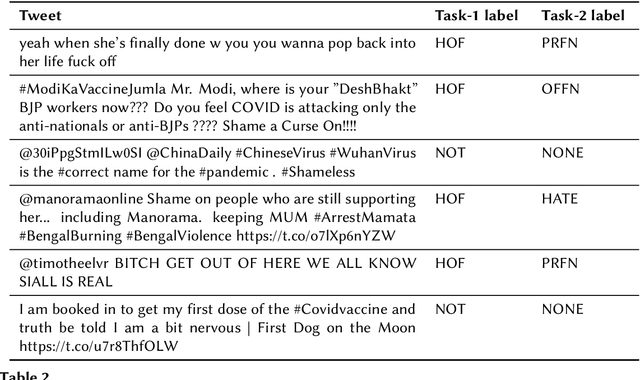
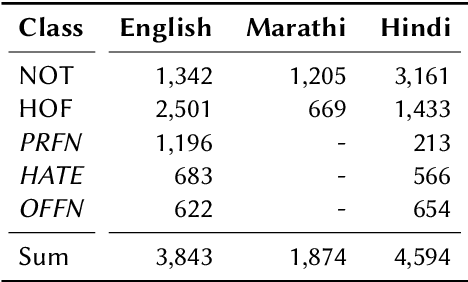
The widespread of offensive content online such as hate speech poses a growing societal problem. AI tools are necessary for supporting the moderation process at online platforms. For the evaluation of these identification tools, continuous experimentation with data sets in different languages are necessary. The HASOC track (Hate Speech and Offensive Content Identification) is dedicated to develop benchmark data for this purpose. This paper presents the HASOC subtrack for English, Hindi, and Marathi. The data set was assembled from Twitter. This subtrack has two sub-tasks. Task A is a binary classification problem (Hate and Not Offensive) offered for all three languages. Task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY offered for English and Hindi. Overall, 652 runs were submitted by 65 teams. The performance of the best classification algorithms for task A are F1 measures 0.91, 0.78 and 0.83 for Marathi, Hindi and English, respectively. This overview presents the tasks and the data development as well as the detailed results. The systems submitted to the competition applied a variety of technologies. The best performing algorithms were mainly variants of transformer architectures.
Overview of the CLEF--2021 CheckThat! Lab on Detecting Check-Worthy Claims, Previously Fact-Checked Claims, and Fake News
Sep 23, 2021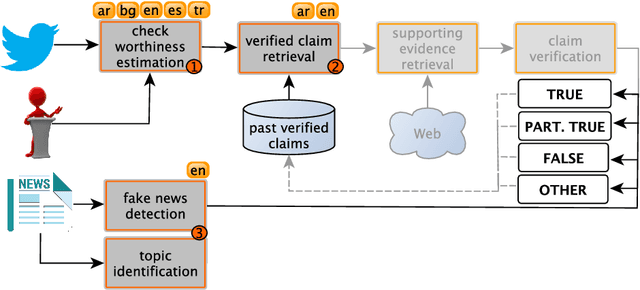
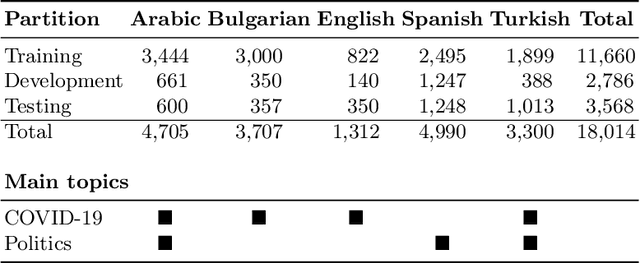
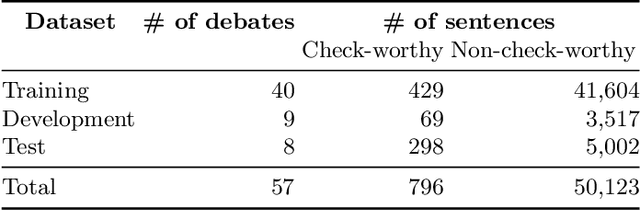
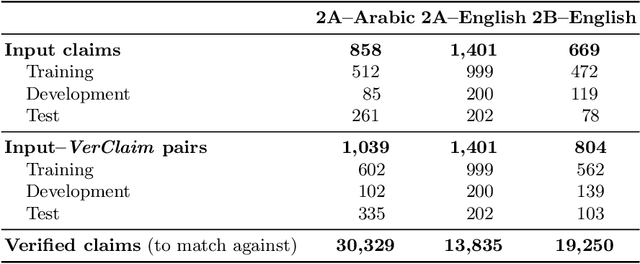
We describe the fourth edition of the CheckThat! Lab, part of the 2021 Conference and Labs of the Evaluation Forum (CLEF). The lab evaluates technology supporting tasks related to factuality, and covers Arabic, Bulgarian, English, Spanish, and Turkish. Task 1 asks to predict which posts in a Twitter stream are worth fact-checking, focusing on COVID-19 and politics (in all five languages). Task 2 asks to determine whether a claim in a tweet can be verified using a set of previously fact-checked claims (in Arabic and English). Task 3 asks to predict the veracity of a news article and its topical domain (in English). The evaluation is based on mean average precision or precision at rank k for the ranking tasks, and macro-F1 for the classification tasks. This was the most popular CLEF-2021 lab in terms of team registrations: 132 teams. Nearly one-third of them participated: 15, 5, and 25 teams submitted official runs for tasks 1, 2, and 3, respectively.
* Check-Worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Detecting Previously Fact-Checked Claims, Social Media Verification, Computational Journalism, COVID-19
Overview of the HASOC track at FIRE 2020: Hate Speech and Offensive Content Identification in Indo-European Languages
Aug 12, 2021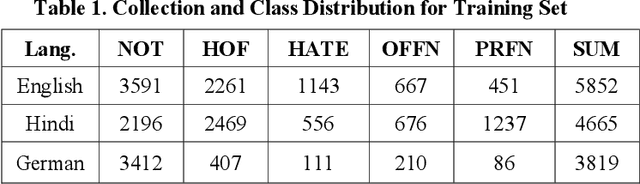
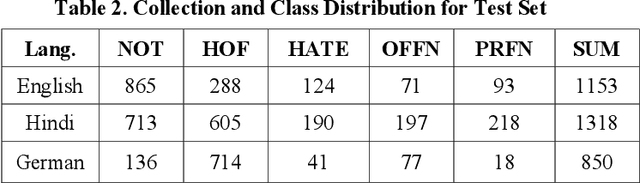
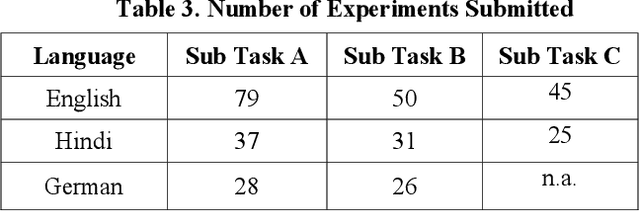
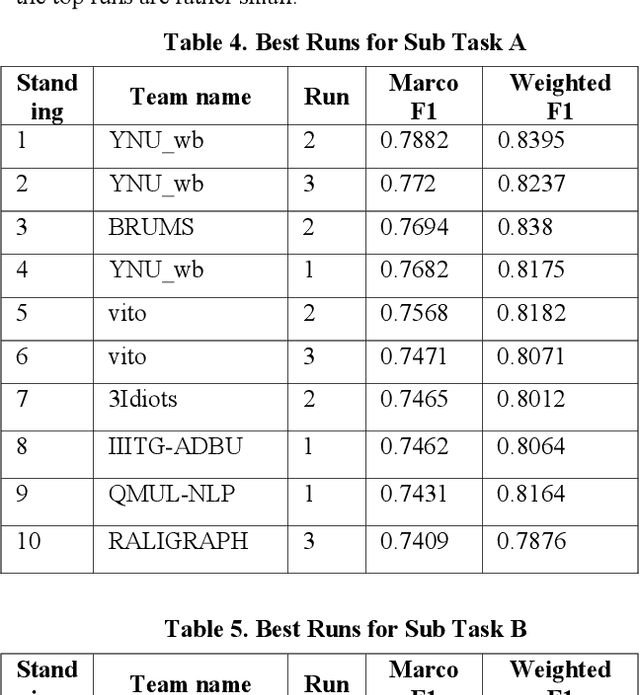
With the growth of social media, the spread of hate speech is also increasing rapidly. Social media are widely used in many countries. Also Hate Speech is spreading in these countries. This brings a need for multilingual Hate Speech detection algorithms. Much research in this area is dedicated to English at the moment. The HASOC track intends to provide a platform to develop and optimize Hate Speech detection algorithms for Hindi, German and English. The dataset is collected from a Twitter archive and pre-classified by a machine learning system. HASOC has two sub-task for all three languages: task A is a binary classification problem (Hate and Not Offensive) while task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY. Overall, 252 runs were submitted by 40 teams. The performance of the best classification algorithms for task A are F1 measures of 0.51, 0.53 and 0.52 for English, Hindi, and German, respectively. For task B, the best classification algorithms achieved F1 measures of 0.26, 0.33 and 0.29 for English, Hindi, and German, respectively. This article presents the tasks and the data development as well as the results. The best performing algorithms were mainly variants of the transformer architecture BERT. However, also other systems were applied with good success
Tiplines to Combat Misinformation on Encrypted Platforms: A Case Study of the 2019 Indian Election on WhatsApp
Jun 08, 2021
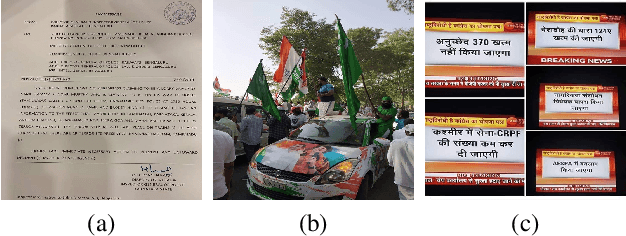


WhatsApp is a popular chat application used by over 2 billion users worldwide. However, due to end-to-end encryption, there is currently no easy way to fact-check content on WhatsApp at scale. In this paper, we analyze the usefulness of a crowd-sourced system on WhatsApp through which users can submit "tips" containing messages they want fact-checked. We compare the tips sent to a WhatsApp tipline run during the 2019 Indian national elections with the messages circulating in large, public groups on WhatsApp and other social media platforms during the same period. We find that tiplines are a very useful lens into WhatsApp conversations: a significant fraction of messages and images sent to the tipline match with the content being shared on public WhatsApp groups and other social media. Our analysis also shows that tiplines cover the most popular content well, and a majority of such content is often shared to the tipline before appearing in large, public WhatsApp groups. Overall, the analysis suggests tiplines can be an effective source for discovering content to fact-check.
AMUSED: An Annotation Framework of Multi-modal Social Media Data
Oct 01, 2020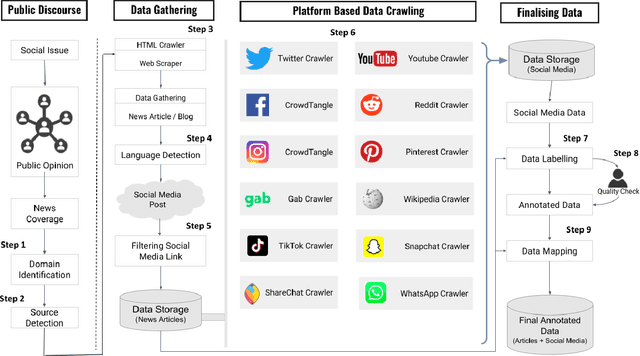



In this paper, we present a semi-automated framework called AMUSED for gathering multi-modal annotated data from the multiple social media platforms. The framework is designed to mitigate the issues of collecting and annotating social media data by cohesively combining machine and human in the data collection process. From a given list of the articles from professional news media or blog, AMUSED detects links to the social media posts from news articles and then downloads contents of the same post from the respective social media platform to gather details about that specific post. The framework is capable of fetching the annotated data from multiple platforms like Twitter, YouTube, Reddit. The framework aims to reduce the workload and problems behind the data annotation from the social media platforms. AMUSED can be applied in multiple application domains, as a use case, we have implemented the framework for collecting COVID-19 misinformation data from different social media platforms.