 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaping Event Backstories to Estimate Potential Emotion Contexts
Aug 13, 2025Emotion analysis is an inherently ambiguous task. Previous work studied annotator properties to explain disagreement, but this overlooks the possibility that ambiguity may stem from missing information about the context of events. In this paper, we propose a novel approach that adds reasonable contexts to event descriptions, which may better explain a particular situation. Our goal is to understand whether these enriched contexts enable human annotators to annotate emotions more reliably. We disambiguate a target event description by automatically generating multiple event chains conditioned on differing emotions. By combining techniques from short story generation in various settings, we achieve coherent narratives that result in a specialized dataset for the first comprehensive and systematic examination of contextualized emotion analysis. Through automatic and human evaluation, we find that contextual narratives enhance the interpretation of specific emotions and support annotators in producing more consistent annotations.
Which Demographics do LLMs Default to During Annotation?
Oct 11, 2024

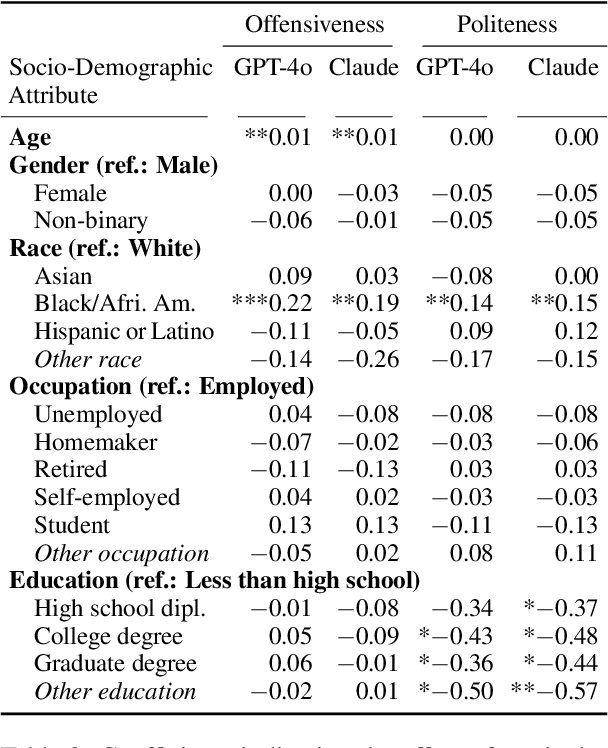
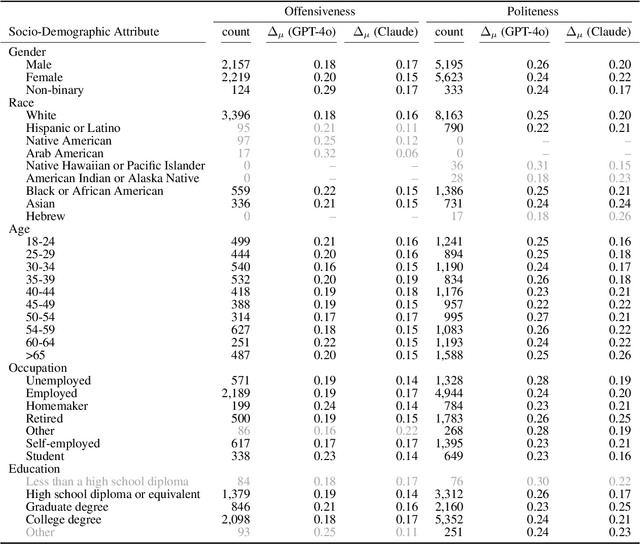
Demographics and cultural background of annotators influence the labels they assign in text annotation -- for instance, an elderly woman might find it offensive to read a message addressed to a "bro", but a male teenager might find it appropriate. It is therefore important to acknowledge label variations to not under-represent members of a society. Two research directions developed out of this observation in the context of using large language models (LLM) for data annotations, namely (1) studying biases and inherent knowledge of LLMs and (2) injecting diversity in the output by manipulating the prompt with demographic information. We combine these two strands of research and ask the question to which demographics an LLM resorts to when no demographics is given. To answer this question, we evaluate which attributes of human annotators LLMs inherently mimic. Furthermore, we compare non-demographic conditioned prompts and placebo-conditioned prompts (e.g., "you are an annotator who lives in house number 5") to demographics-conditioned prompts ("You are a 45 year old man and an expert on politeness annotation. How do you rate {instance}"). We study these questions for politeness and offensiveness annotations on the POPQUORN data set, a corpus created in a controlled manner to investigate human label variations based on demographics which has not been used for LLM-based analyses so far. We observe notable influences related to gender, race, and age in demographic prompting, which contrasts with previous studies that found no such effects.
Overview of the HASOC track at FIRE 2020: Hate Speech and Offensive Content Identification in Indo-European Languages
Aug 12, 2021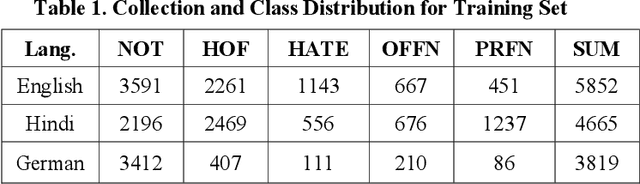
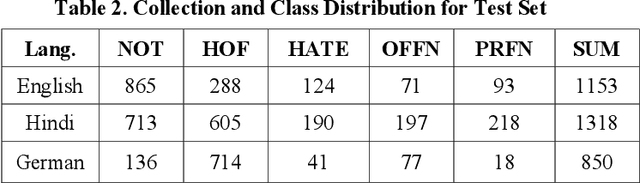
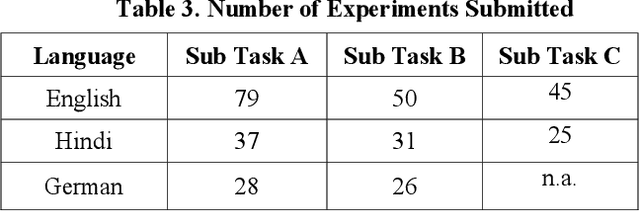
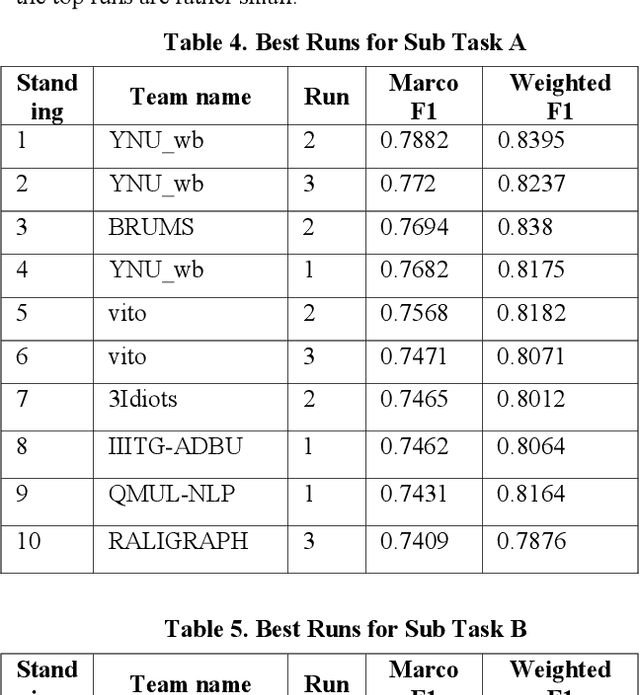
With the growth of social media, the spread of hate speech is also increasing rapidly. Social media are widely used in many countries. Also Hate Speech is spreading in these countries. This brings a need for multilingual Hate Speech detection algorithms. Much research in this area is dedicated to English at the moment. The HASOC track intends to provide a platform to develop and optimize Hate Speech detection algorithms for Hindi, German and English. The dataset is collected from a Twitter archive and pre-classified by a machine learning system. HASOC has two sub-task for all three languages: task A is a binary classification problem (Hate and Not Offensive) while task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY. Overall, 252 runs were submitted by 40 teams. The performance of the best classification algorithms for task A are F1 measures of 0.51, 0.53 and 0.52 for English, Hindi, and German, respectively. For task B, the best classification algorithms achieved F1 measures of 0.26, 0.33 and 0.29 for English, Hindi, and German, respectively. This article presents the tasks and the data development as well as the results. The best performing algorithms were mainly variants of the transformer architecture BERT. However, also other systems were applied with good success