 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Surprisingly Consider Recommendations? A Knowledge-Graph-based Approach Relying on Complex Network Metrics
May 14, 2024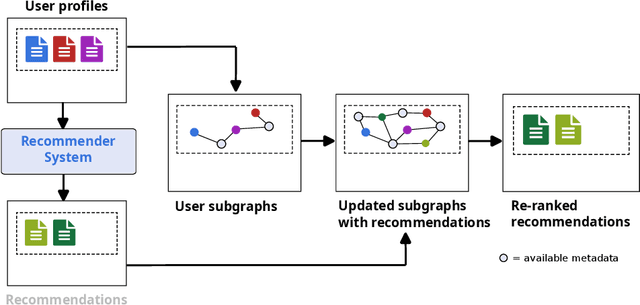

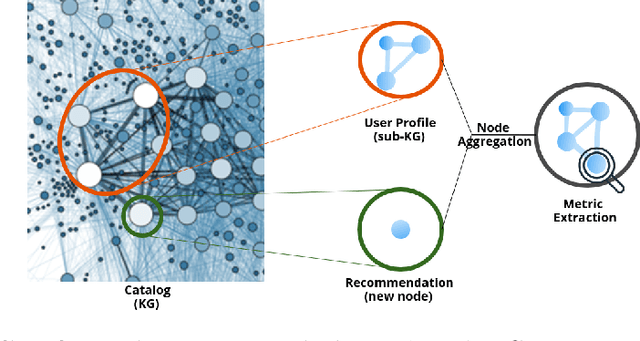
Traditional recommendation proposals, including content-based and collaborative filtering, usually focus on similarity between items or users. Existing approaches lack ways of introducing unexpectedness into recommendations, prioritizing globally popular items over exposing users to unforeseen items. This investigation aims to design and evaluate a novel layer on top of recommender systems suited to incorporate relational information and suggest items with a user-defined degree of surprise. We propose a Knowledge Graph (KG) based recommender system by encoding user interactions on item catalogs. Our study explores whether network-level metrics on KGs can influence the degree of surprise in recommendations. We hypothesize that surprisingness correlates with certain network metrics, treating user profiles as subgraphs within a larger catalog KG. The achieved solution reranks recommendations based on their impact on structural graph metrics. Our research contributes to optimizing recommendations to reflect the metrics. We experimentally evaluate our approach on two datasets of LastFM listening histories and synthetic Netflix viewing profiles. We find that reranking items based on complex network metrics leads to a more unexpected and surprising composition of recommendation lists.
Explaining Hate Speech Classification with Model Agnostic Methods
May 30, 2023



There have been remarkable breakthroughs in Machine Learning and Artificial Intelligence, notably in the areas of Natural Language Processing and Deep Learning. Additionally, hate speech detection in dialogues has been gaining popularity among Natural Language Processing researchers with the increased use of social media. However, as evidenced by the recent trends, the need for the dimensions of explainability and interpretability in AI models has been deeply realised. Taking note of the factors above, the research goal of this paper is to bridge the gap between hate speech prediction and the explanations generated by the system to support its decision. This has been achieved by first predicting the classification of a text and then providing a posthoc, model agnostic and surrogate interpretability approach for explainability and to prevent model bias. The bidirectional transformer model BERT has been used for prediction because of its state of the art efficiency over other Machine Learning models. The model agnostic algorithm LIME generates explanations for the output of a trained classifier and predicts the features that influence the model decision. The predictions generated from the model were evaluated manually, and after thorough evaluation, we observed that the model performs efficiently in predicting and explaining its prediction. Lastly, we suggest further directions for the expansion of the provided research work.
Overview of the HASOC Subtrack at FIRE 2021: Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Dec 17, 2021
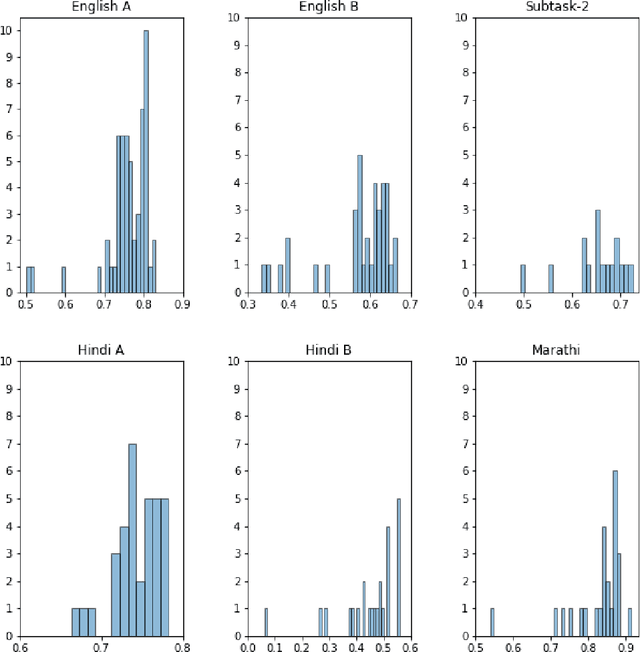
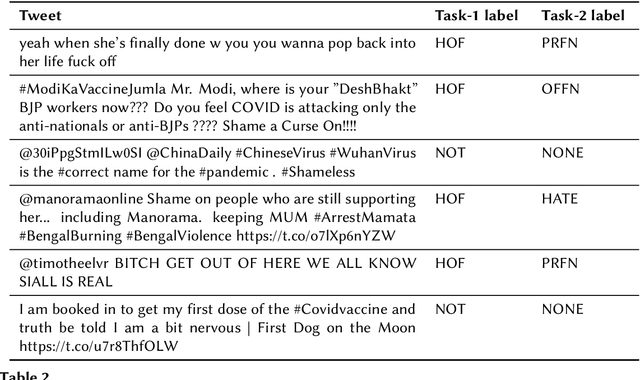
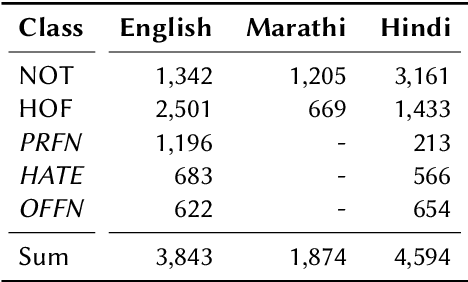
The widespread of offensive content online such as hate speech poses a growing societal problem. AI tools are necessary for supporting the moderation process at online platforms. For the evaluation of these identification tools, continuous experimentation with data sets in different languages are necessary. The HASOC track (Hate Speech and Offensive Content Identification) is dedicated to develop benchmark data for this purpose. This paper presents the HASOC subtrack for English, Hindi, and Marathi. The data set was assembled from Twitter. This subtrack has two sub-tasks. Task A is a binary classification problem (Hate and Not Offensive) offered for all three languages. Task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY offered for English and Hindi. Overall, 652 runs were submitted by 65 teams. The performance of the best classification algorithms for task A are F1 measures 0.91, 0.78 and 0.83 for Marathi, Hindi and English, respectively. This overview presents the tasks and the data development as well as the detailed results. The systems submitted to the competition applied a variety of technologies. The best performing algorithms were mainly variants of transformer architectures.
Overview of the HASOC track at FIRE 2020: Hate Speech and Offensive Content Identification in Indo-European Languages
Aug 12, 2021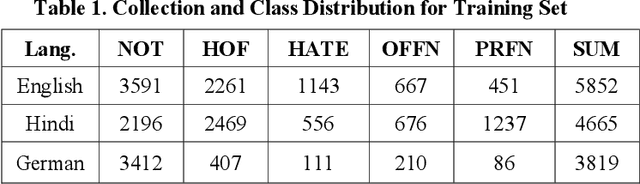
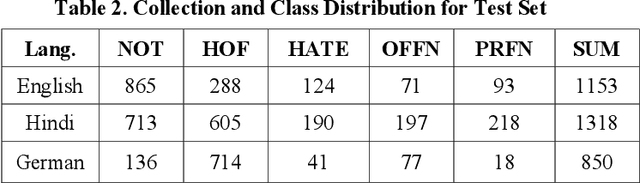
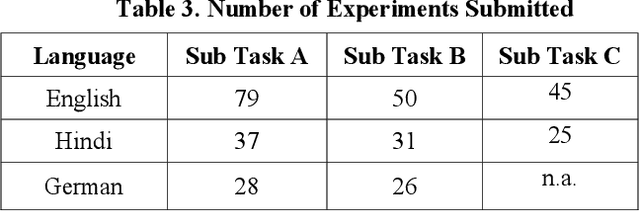
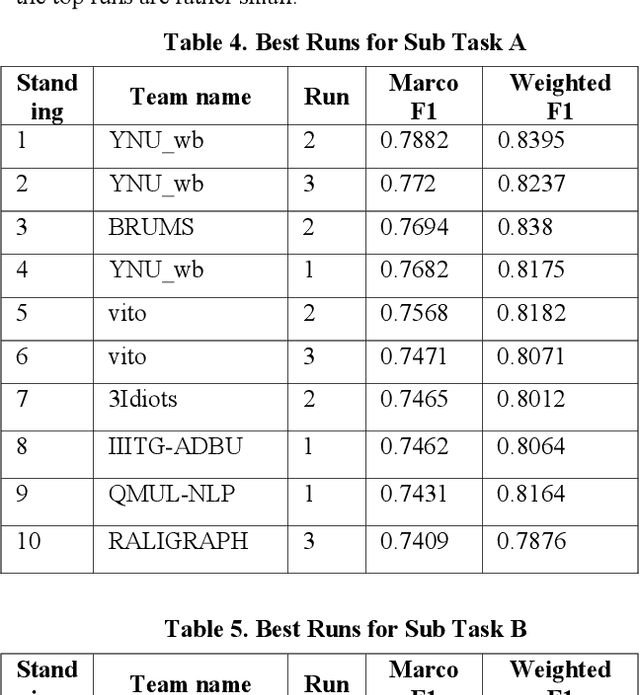
With the growth of social media, the spread of hate speech is also increasing rapidly. Social media are widely used in many countries. Also Hate Speech is spreading in these countries. This brings a need for multilingual Hate Speech detection algorithms. Much research in this area is dedicated to English at the moment. The HASOC track intends to provide a platform to develop and optimize Hate Speech detection algorithms for Hindi, German and English. The dataset is collected from a Twitter archive and pre-classified by a machine learning system. HASOC has two sub-task for all three languages: task A is a binary classification problem (Hate and Not Offensive) while task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY. Overall, 252 runs were submitted by 40 teams. The performance of the best classification algorithms for task A are F1 measures of 0.51, 0.53 and 0.52 for English, Hindi, and German, respectively. For task B, the best classification algorithms achieved F1 measures of 0.26, 0.33 and 0.29 for English, Hindi, and German, respectively. This article presents the tasks and the data development as well as the results. The best performing algorithms were mainly variants of the transformer architecture BERT. However, also other systems were applied with good success