 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous AI imitators increase diversity in homogeneous information ecosystems
Mar 21, 2025Recent breakthroughs in large language models (LLMs) have facilitated autonomous AI agents capable of imitating human-generated content. This technological advancement raises fundamental questions about AI's impact on the diversity and democratic value of information ecosystems. We introduce a large-scale simulation framework to examine AI-based imitation within news, a context crucial for public discourse. By systematically testing two distinct imitation strategies across a range of information environments varying in initial diversity, we demonstrate that AI-generated articles do not uniformly homogenize content. Instead, AI's influence is strongly context-dependent: AI-generated content can introduce valuable diversity in originally homogeneous news environments but diminish diversity in initially heterogeneous contexts. These results illustrate that the initial diversity of an information environment critically shapes AI's impact, challenging assumptions that AI-driven imitation uniformly threatens diversity. Instead, when information is initially homogeneous, AI-driven imitation can expand perspectives, styles, and topics. This is especially important in news contexts, where information diversity fosters richer public debate by exposing citizens to alternative viewpoints, challenging biases, and preventing narrative monopolies, which is essential for a resilient democracy.
How to Surprisingly Consider Recommendations? A Knowledge-Graph-based Approach Relying on Complex Network Metrics
May 14, 2024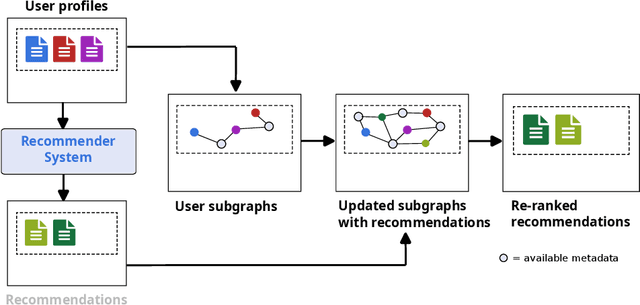

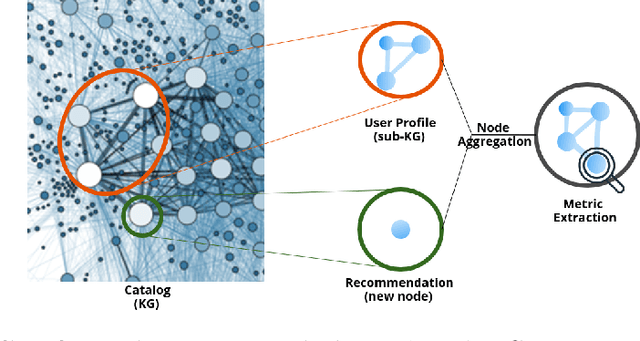
Traditional recommendation proposals, including content-based and collaborative filtering, usually focus on similarity between items or users. Existing approaches lack ways of introducing unexpectedness into recommendations, prioritizing globally popular items over exposing users to unforeseen items. This investigation aims to design and evaluate a novel layer on top of recommender systems suited to incorporate relational information and suggest items with a user-defined degree of surprise. We propose a Knowledge Graph (KG) based recommender system by encoding user interactions on item catalogs. Our study explores whether network-level metrics on KGs can influence the degree of surprise in recommendations. We hypothesize that surprisingness correlates with certain network metrics, treating user profiles as subgraphs within a larger catalog KG. The achieved solution reranks recommendations based on their impact on structural graph metrics. Our research contributes to optimizing recommendations to reflect the metrics. We experimentally evaluate our approach on two datasets of LastFM listening histories and synthetic Netflix viewing profiles. We find that reranking items based on complex network metrics leads to a more unexpected and surprising composition of recommendation lists.