 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakeClaim: A Multiple Platform-driven Dataset for Identification of Fake News on 2023 Israel-Hamas War
Jan 29, 2024



We contribute the first publicly available dataset of factual claims from different platforms and fake YouTube videos on the 2023 Israel-Hamas war for automatic fake YouTube video classification. The FakeClaim data is collected from 60 fact-checking organizations in 30 languages and enriched with metadata from the fact-checking organizations curated by trained journalists specialized in fact-checking. Further, we classify fake videos within the subset of YouTube videos using textual information and user comments. We used a pre-trained model to classify each video with different feature combinations. Our best-performing fine-tuned language model, Universal Sentence Encoder (USE), achieves a Macro F1 of 87\%, which shows that the trained model can be helpful for debunking fake videos using the comments from the user discussion. The dataset is available on Github\footnote{https://github.com/Gautamshahi/FakeClaim}
Overview of the HASOC Subtrack at FIRE 2021: Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Dec 17, 2021
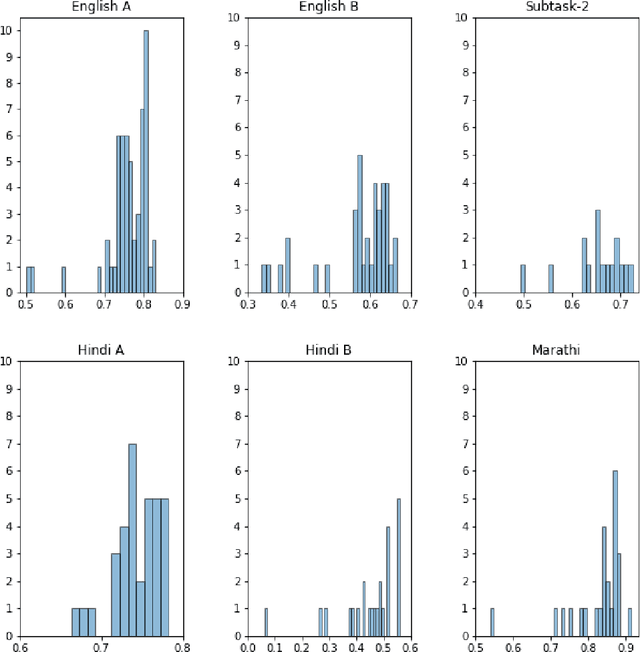
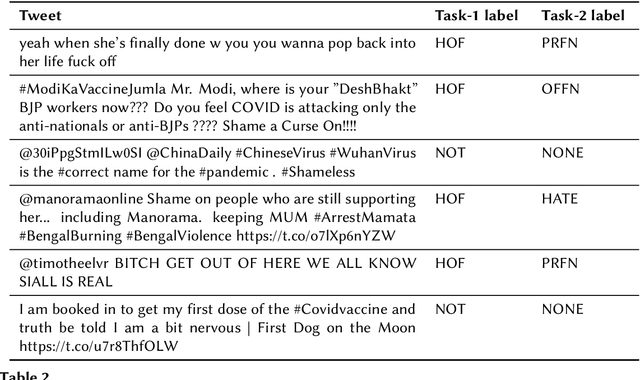
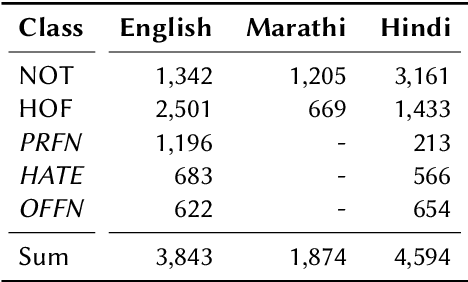
The widespread of offensive content online such as hate speech poses a growing societal problem. AI tools are necessary for supporting the moderation process at online platforms. For the evaluation of these identification tools, continuous experimentation with data sets in different languages are necessary. The HASOC track (Hate Speech and Offensive Content Identification) is dedicated to develop benchmark data for this purpose. This paper presents the HASOC subtrack for English, Hindi, and Marathi. The data set was assembled from Twitter. This subtrack has two sub-tasks. Task A is a binary classification problem (Hate and Not Offensive) offered for all three languages. Task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY offered for English and Hindi. Overall, 652 runs were submitted by 65 teams. The performance of the best classification algorithms for task A are F1 measures 0.91, 0.78 and 0.83 for Marathi, Hindi and English, respectively. This overview presents the tasks and the data development as well as the detailed results. The systems submitted to the competition applied a variety of technologies. The best performing algorithms were mainly variants of transformer architectures.
Overview of the CLEF--2021 CheckThat! Lab on Detecting Check-Worthy Claims, Previously Fact-Checked Claims, and Fake News
Sep 23, 2021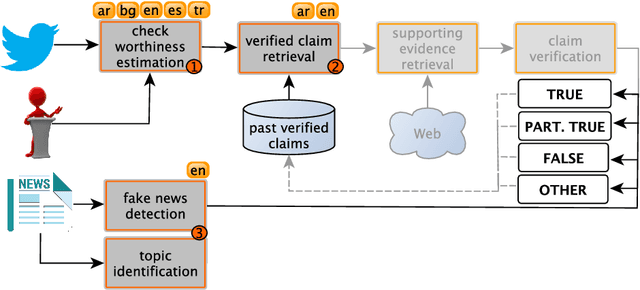
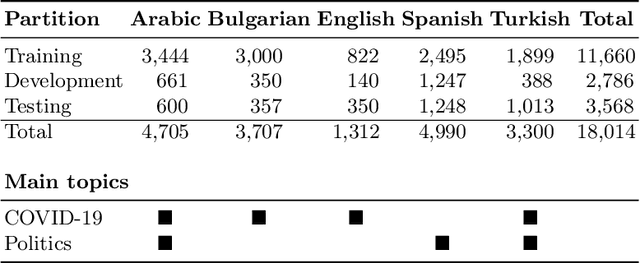
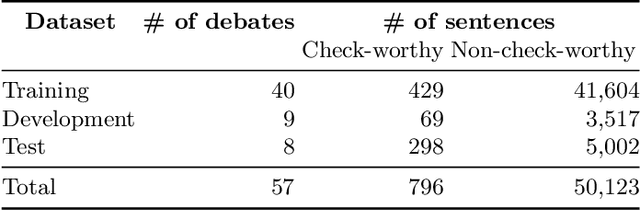
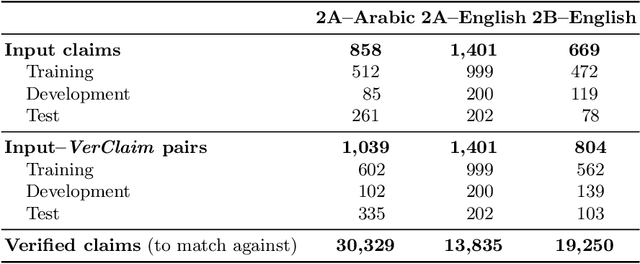
We describe the fourth edition of the CheckThat! Lab, part of the 2021 Conference and Labs of the Evaluation Forum (CLEF). The lab evaluates technology supporting tasks related to factuality, and covers Arabic, Bulgarian, English, Spanish, and Turkish. Task 1 asks to predict which posts in a Twitter stream are worth fact-checking, focusing on COVID-19 and politics (in all five languages). Task 2 asks to determine whether a claim in a tweet can be verified using a set of previously fact-checked claims (in Arabic and English). Task 3 asks to predict the veracity of a news article and its topical domain (in English). The evaluation is based on mean average precision or precision at rank k for the ranking tasks, and macro-F1 for the classification tasks. This was the most popular CLEF-2021 lab in terms of team registrations: 132 teams. Nearly one-third of them participated: 15, 5, and 25 teams submitted official runs for tasks 1, 2, and 3, respectively.
* Check-Worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Detecting Previously Fact-Checked Claims, Social Media Verification, Computational Journalism, COVID-19
Deep Learning Approaches to Classification of Production Technology for 19th Century Books
Sep 17, 2020



Cultural research is dedicated to understanding the processes of knowledge dissemination and the social and technological practices in the book industry. Research on children books in the 19th century can be supported by computer systems. Specifically, the advances in digital image processing seem to offer great opportunities for analyzing and quantifying the visual components in the books. The production technology for illustrations in books in the 19th century was characterized by a shift from wood or copper engraving to lithography. We report classification experiments which intend to classify images based on the production technology. For a classification task that is also difficult for humans, the classification quality reaches only around 70%. We analyze some further error sources and identify reasons for the low performance.
* LWDA 2018: Mannheim, Germany