 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovieRecapsQA: A Multimodal Open-Ended Video Question-Answering Benchmark
Jan 05, 2026Understanding real-world videos such as movies requires integrating visual and dialogue cues to answer complex questions. Yet existing VideoQA benchmarks struggle to capture this multimodal reasoning and are largely not open-ended, given the difficulty of evaluating free-form answers. In this paper, we introduce a novel open-ended multi-modal VideoQA benchmark, MovieRecapsQA created using movie recap videos--a distinctive type of YouTube content that summarizes a film by presenting its key events through synchronized visual (recap video) and textual (recap summary) modalities. Using the recap summary, we generate $\approx 8.2$ K question-answer (QA) pairs (aligned with movie-subtitles) and provide the necessary "facts" needed to verify an answer in a reference-free manner. To our knowledge, this is the first open-ended VideoQA benchmark that supplies explicit textual context of the input (video and/or text); which we use for evaluation. Our benchmark provides videos of multiple lengths (i.e., recap-segments, movie-segments) and categorizations of questions (by modality and type) to enable fine-grained analysis. We evaluate the performance of seven state-of-the-art MLLMs using our benchmark and observe that: 1) visual-only questions remain the most challenging; 2) models default to textual inputs whenever available; 3) extracting factually accurate information from video content is still difficult for all models; and 4) proprietary and open-source models perform comparably on video-dependent questions.
Are Triggers Needed for Document-Level Event Extraction?
Nov 13, 2024Most existing work on event extraction has focused on sentence-level texts and presumes the identification of a trigger-span -- a word or phrase in the input that evokes the occurrence of an event of interest. Event arguments are then extracted with respect to the trigger. Indeed, triggers are treated as integral to, and trigger detection as an essential component of, event extraction. In this paper, we provide the first investigation of the role of triggers for the more difficult and much less studied task of document-level event extraction. We analyze their usefulness in multiple end-to-end and pipelined neural event extraction models for three document-level event extraction datasets, measuring performance using triggers of varying quality (human-annotated, LLM-generated, keyword-based, and random). Our research shows that trigger effectiveness varies based on the extraction task's characteristics and data quality, with basic, automatically-generated triggers serving as a viable alternative to human-annotated ones. Furthermore, providing detailed event descriptions to the extraction model helps maintain robust performance even when trigger quality degrades. Perhaps surprisingly, we also find that the mere existence of trigger input, even random ones, is important for prompt-based LLM approaches to the task.
Findings of the NLP4IF-2021 Shared Tasks on Fighting the COVID-19 Infodemic and Censorship Detection
Sep 23, 2021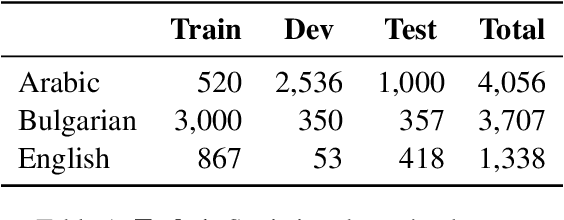
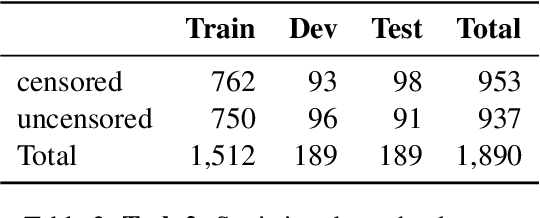
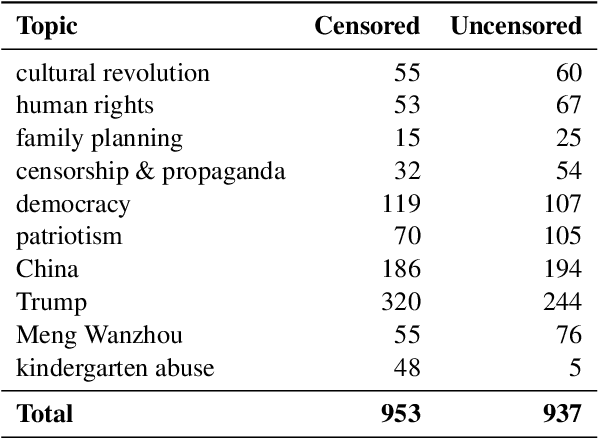
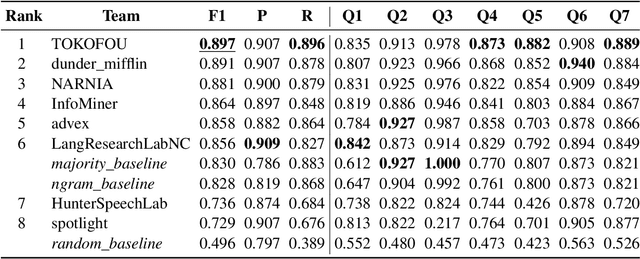
We present the results and the main findings of the NLP4IF-2021 shared tasks. Task 1 focused on fighting the COVID-19 infodemic in social media, and it was offered in Arabic, Bulgarian, and English. Given a tweet, it asked to predict whether that tweet contains a verifiable claim, and if so, whether it is likely to be false, is of general interest, is likely to be harmful, and is worthy of manual fact-checking; also, whether it is harmful to society, and whether it requires the attention of policy makers. Task~2 focused on censorship detection, and was offered in Chinese. A total of ten teams submitted systems for task 1, and one team participated in task 2; nine teams also submitted a system description paper. Here, we present the tasks, analyze the results, and discuss the system submissions and the methods they used. Most submissions achieved sizable improvements over several baselines, and the best systems used pre-trained Transformers and ensembles. The data, the scorers and the leaderboards for the tasks are available at http://gitlab.com/NLP4IF/nlp4if-2021.
* COVID-19, infodemic, harmfulness, check-worthiness, censorship, social media, tweets, Arabic, Bulgarian, English, Chinese
Overview of the CLEF--2021 CheckThat! Lab on Detecting Check-Worthy Claims, Previously Fact-Checked Claims, and Fake News
Sep 23, 2021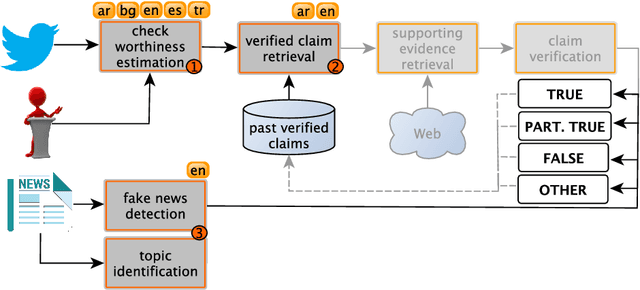
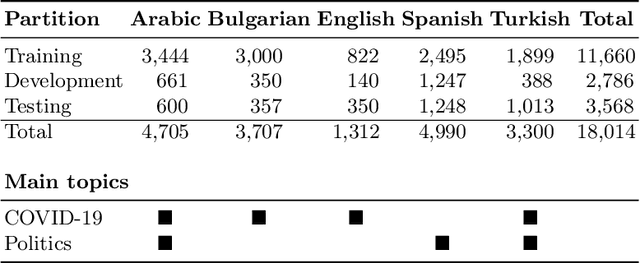
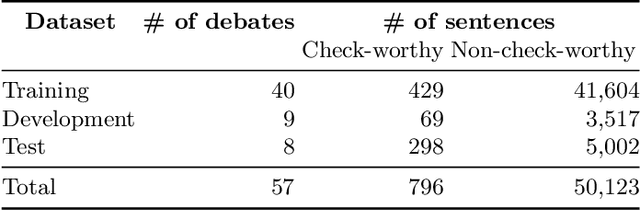
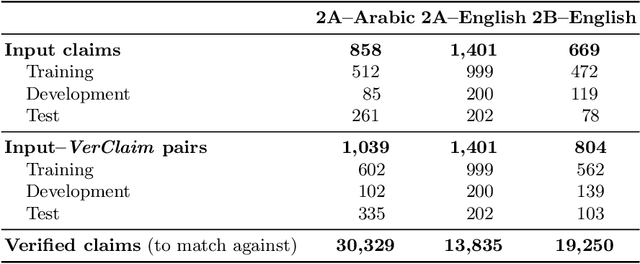
We describe the fourth edition of the CheckThat! Lab, part of the 2021 Conference and Labs of the Evaluation Forum (CLEF). The lab evaluates technology supporting tasks related to factuality, and covers Arabic, Bulgarian, English, Spanish, and Turkish. Task 1 asks to predict which posts in a Twitter stream are worth fact-checking, focusing on COVID-19 and politics (in all five languages). Task 2 asks to determine whether a claim in a tweet can be verified using a set of previously fact-checked claims (in Arabic and English). Task 3 asks to predict the veracity of a news article and its topical domain (in English). The evaluation is based on mean average precision or precision at rank k for the ranking tasks, and macro-F1 for the classification tasks. This was the most popular CLEF-2021 lab in terms of team registrations: 132 teams. Nearly one-third of them participated: 15, 5, and 25 teams submitted official runs for tasks 1, 2, and 3, respectively.
* Check-Worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Detecting Previously Fact-Checked Claims, Social Media Verification, Computational Journalism, COVID-19
A Second Pandemic? Analysis of Fake News About COVID-19 Vaccines in Qatar
Sep 22, 2021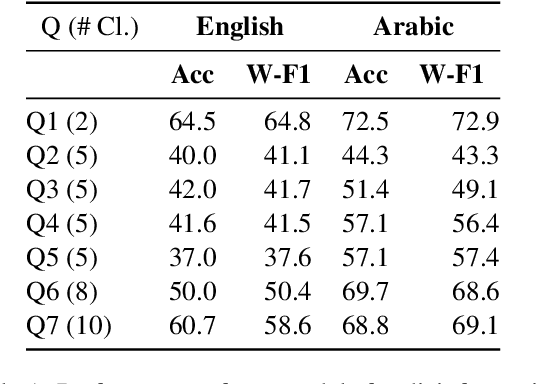
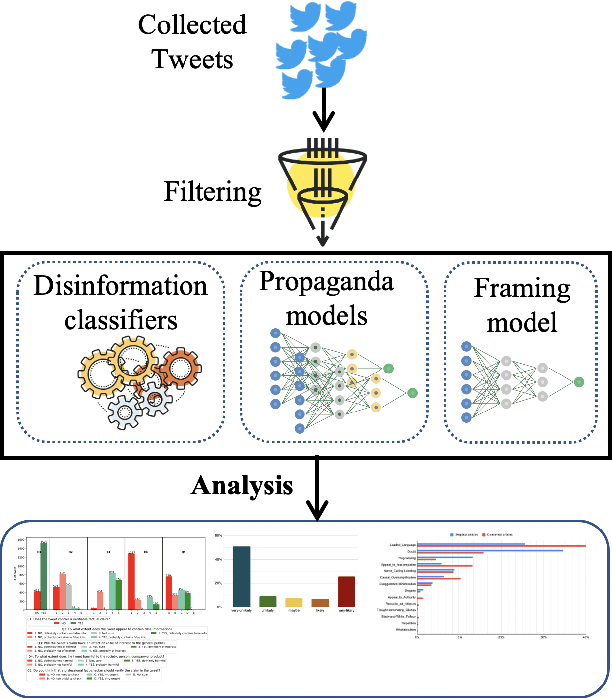
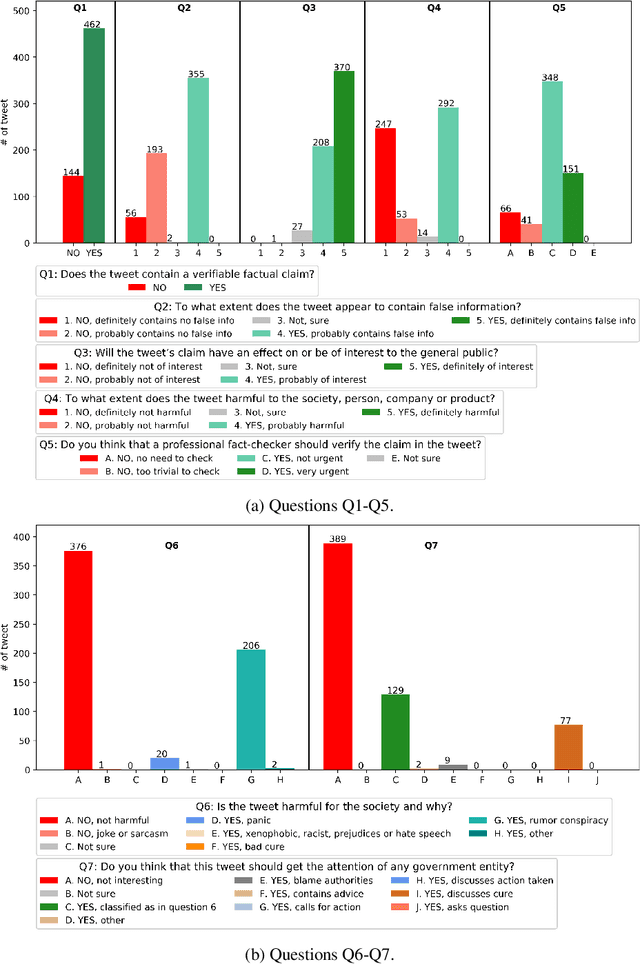
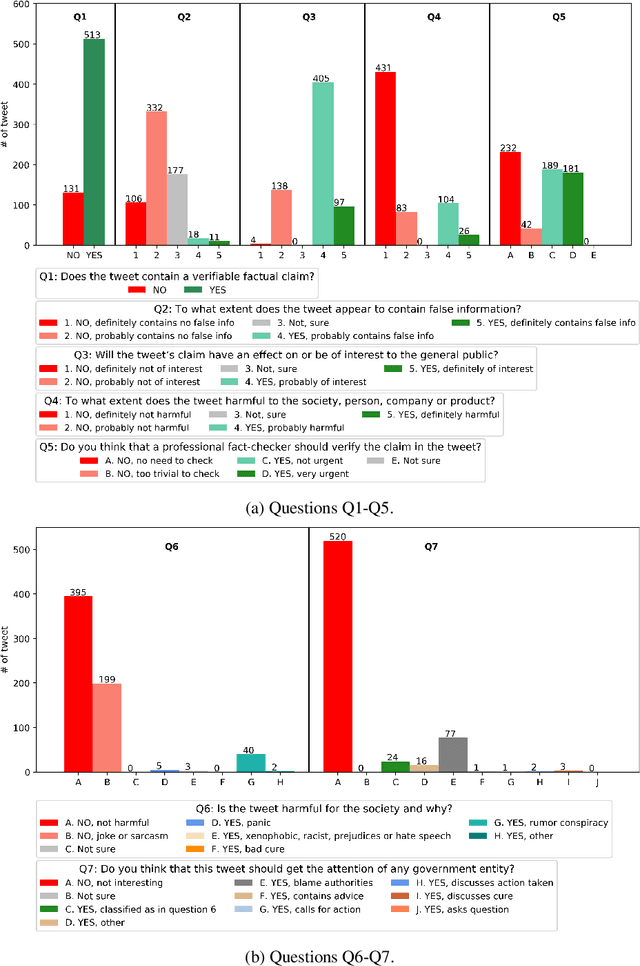
While COVID-19 vaccines are finally becoming widely available, a second pandemic that revolves around the circulation of anti-vaxxer fake news may hinder efforts to recover from the first one. With this in mind, we performed an extensive analysis of Arabic and English tweets about COVID-19 vaccines, with focus on messages originating from Qatar. We found that Arabic tweets contain a lot of false information and rumors, while English tweets are mostly factual. However, English tweets are much more propagandistic than Arabic ones. In terms of propaganda techniques, about half of the Arabic tweets express doubt, and 1/5 use loaded language, while English tweets are abundant in loaded language, exaggeration, fear, name-calling, doubt, and flag-waving. Finally, in terms of framing, Arabic tweets adopt a health and safety perspective, while in English economic concerns dominate.
* COVID-19, disinformation, misinformation, factuality, fact-checking, fact-checkers, check-worthiness, framing, harmfulness, social media platforms, social media
Assisting the Human Fact-Checkers: Detecting All Previously Fact-Checked Claims in a Document
Sep 14, 2021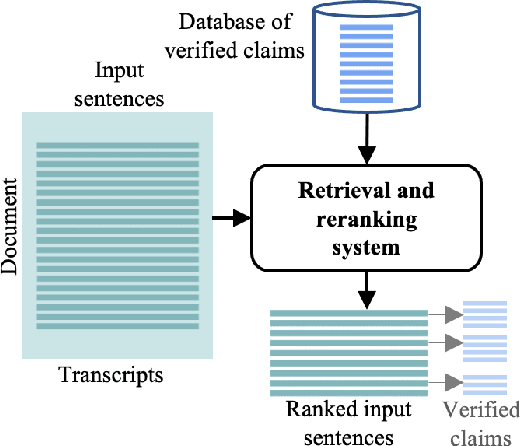
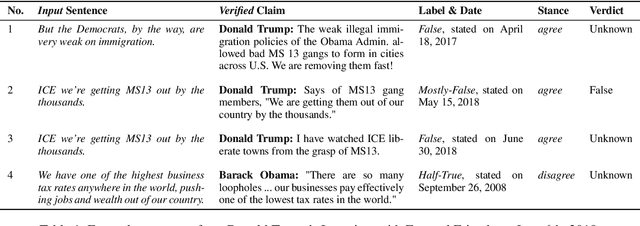

Given the recent proliferation of false claims online, there has been a lot of manual fact-checking effort. As this is very time-consuming, human fact-checkers can benefit from tools that can support them and make them more efficient. Here, we focus on building a system that could provide such support. Given an input document, it aims to detect all sentences that contain a claim that can be verified by some previously fact-checked claims (from a given database). The output is a re-ranked list of the document sentences, so that those that can be verified are ranked as high as possible, together with corresponding evidence. Unlike previous work, which has looked into claim retrieval, here we take a document-level perspective. We create a new manually annotated dataset for the task, and we propose suitable evaluation measures. We further experiment with a learning-to-rank approach, achieving sizable performance gains over several strong baselines. Our analysis demonstrates the importance of modeling text similarity and stance, while also taking into account the veracity of the retrieved previously fact-checked claims. We believe that this research would be of interest to fact-checkers, journalists, media, and regulatory authorities.
Cross-lingual Emotion Detection
Jun 10, 2021

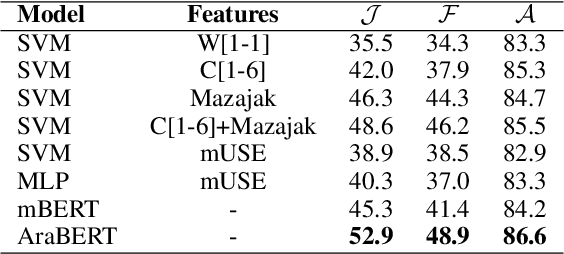
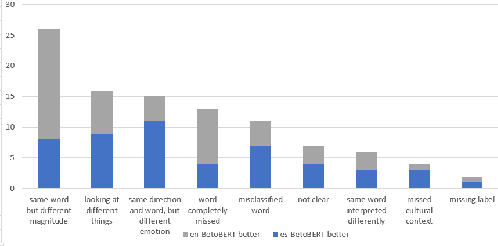
Emotion detection is of great importance for understanding humans. Constructing annotated datasets to train automated models can be expensive. We explore the efficacy of cross-lingual approaches that would use data from a source language to build models for emotion detection in a target language. We compare three approaches, namely: i) using inherently multilingual models; ii) translating training data into the target language; and iii) using an automatically tagged parallel corpus. In our study, we consider English as the source language with Arabic and Spanish as target languages. We study the effectiveness of different classification models such as BERT and SVMs trained with different features. Our BERT-based monolingual models that are trained on target language data surpass state-of-the-art (SOTA) by 4% and 5% absolute Jaccard score for Arabic and Spanish respectively. Next, we show that using cross-lingual approaches with English data alone, we can achieve more than 90% and 80% relative effectiveness of the Arabic and Spanish BERT models respectively. Lastly, we use LIME to interpret the differences between models.
SemEval-2021 Task 6: Detection of Persuasion Techniques in Texts and Images
Apr 25, 2021



We describe SemEval-2021 task 6 on Detection of Persuasion Techniques in Texts and Images: the data, the annotation guidelines, the evaluation setup, the results, and the participating systems. The task focused on memes and had three subtasks: (i) detecting the techniques in the text, (ii) detecting the text spans where the techniques are used, and (iii) detecting techniques in the entire meme, i.e., both in the text and in the image. It was a popular task, attracting 71 registrations, and 22 teams that eventually made an official submission on the test set. The evaluation results for the third subtask confirmed the importance of both modalities, the text and the image. Moreover, some teams reported benefits when not just combining the two modalities, e.g., by using early or late fusion, but rather modeling the interaction between them in a joint model.
* propaganda, disinformation, misinformation, fake news, memes, multimodality
The Role of Context in Detecting Previously Fact-Checked Claims
Apr 15, 2021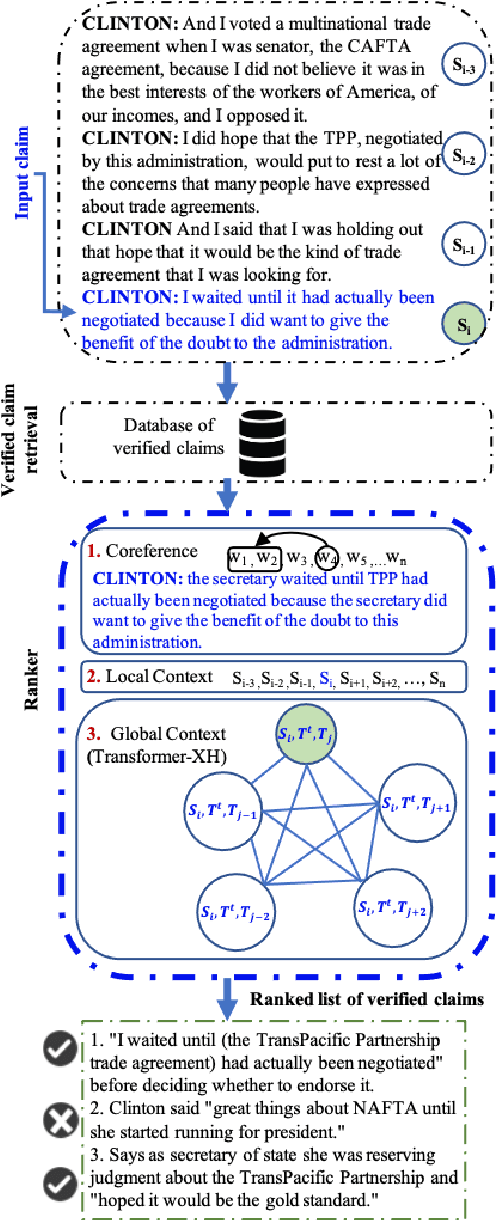
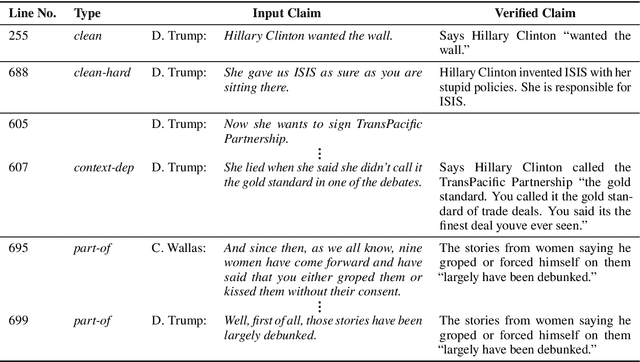


Recent years have seen the proliferation of disinformation and misinformation online, thanks to the freedom of expression on the Internet and to the rise of social media. Two solutions were proposed to address the problem: (i) manual fact-checking, which is accurate and credible, but slow and non-scalable, and (ii) automatic fact-checking, which is fast and scalable, but lacks explainability and credibility. With the accumulation of enough manually fact-checked claims, a middle-ground approach has emerged: checking whether a given claim has previously been fact-checked. This can be made automatically, and thus fast, while also offering credibility and explainability, thanks to the human fact-checking and explanations in the associated fact-checking article. This is a relatively new and understudied research direction, and here we focus on claims made in a political debate, where context really matters. Thus, we study the impact of modeling the context of the claim: both on the source side, i.e., in the debate, as well as on the target side, i.e., in the fact-checking explanation document. We do this by modeling the local context, the global context, as well as by means of co-reference resolution, and reasoning over the target text using Transformer-XH. The experimental results show that each of these represents a valuable information source, but that modeling the source-side context is more important, and can yield 10+ points of absolute improvement.
Automated Fact-Checking for Assisting Human Fact-Checkers
Mar 13, 2021
The reporting and analysis of current events around the globe has expanded from professional, editor-lead journalism all the way to citizen journalism. Politicians and other key players enjoy direct access to their audiences through social media, bypassing the filters of official cables or traditional media. However, the multiple advantages of free speech and direct communication are dimmed by the misuse of the media to spread inaccurate or misleading claims. These phenomena have led to the modern incarnation of the fact-checker -- a professional whose main aim is to examine claims using available evidence to assess their veracity. As in other text forensics tasks, the amount of information available makes the work of the fact-checker more difficult. With this in mind, starting from the perspective of the professional fact-checker, we survey the available intelligent technologies that can support the human expert in the different steps of her fact-checking endeavor. These include identifying claims worth fact-checking; detecting relevant previously fact-checked claims; retrieving relevant evidence to fact-check a claim; and actually verifying a claim. In each case, we pay attention to the challenges in future work and the potential impact on real-world fact-checking.