 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Geometric Analysis of Small-sized Language Model Hallucinations
Feb 16, 2026Hallucinations -- fluent but factually incorrect responses -- pose a major challenge to the reliability of language models, especially in multi-step or agentic settings. This work investigates hallucinations in small-sized LLMs through a geometric perspective, starting from the hypothesis that when models generate multiple responses to the same prompt, genuine ones exhibit tighter clustering in the embedding space, we prove this hypothesis and, leveraging this geometrical insight, we also show that it is possible to achieve a consistent level of separability. This latter result is used to introduce a label-efficient propagation method that classifies large collections of responses from just 30-50 annotations, achieving F1 scores above 90%. Our findings, framing hallucinations from a geometric perspective in the embedding space, complement traditional knowledge-centric and single-response evaluation paradigms, paving the way for further research.
The Big Ban Theory: A Pre- and Post-Intervention Dataset of Online Content Moderation Actions
Jan 16, 2026Online platforms rely on moderation interventions to curb harmful behavior such hate speech, toxicity, and the spread of mis- and disinformation. Yet research on the effects and possible biases of such interventions faces multiple limitations. For example, existing works frequently focus on single or a few interventions, due to the absence of comprehensive datasets. As a result, researchers must typically collect the necessary data for each new study, which limits opportunities for systematic comparisons. To overcome these challenges, we introduce The Big Ban Theory (TBBT), a large dataset of moderation interventions. TBBT covers 25 interventions of varying type, severity, and scope, comprising in total over 339K users and nearly 39M posted messages. For each intervention, we provide standardized metadata and pseudonymized user activity collected three months before and after its enforcement, enabling consistent and comparable analyses of intervention effects. In addition, we provide a descriptive exploratory analysis of the dataset, along with several use cases of how it can support research on content moderation. With this dataset, we aim to support researchers studying the effects of moderation interventions and to promote more systematic, reproducible, and comparable research. TBBT is publicly available at: https://doi.org/10.5281/zenodo.18245670.
PRISM: Phase-enhanced Radial-based Image Signature Mapping framework for fingerprinting AI-generated images
Sep 18, 2025A critical need has emerged for generative AI: attribution methods. That is, solutions that can identify the model originating AI-generated content. This feature, generally relevant in multimodal applications, is especially sensitive in commercial settings where users subscribe to paid proprietary services and expect guarantees about the source of the content they receive. To address these issues, we introduce PRISM, a scalable Phase-enhanced Radial-based Image Signature Mapping framework for fingerprinting AI-generated images. PRISM is based on a radial reduction of the discrete Fourier transform that leverages amplitude and phase information to capture model-specific signatures. The output of the above process is subsequently clustered via linear discriminant analysis to achieve reliable model attribution in diverse settings, even if the model's internal details are inaccessible. To support our work, we construct PRISM-36K, a novel dataset of 36,000 images generated by six text-to-image GAN- and diffusion-based models. On this dataset, PRISM achieves an attribution accuracy of 92.04%. We additionally evaluate our method on four benchmarks from the literature, reaching an average accuracy of 81.60%. Finally, we evaluate our methodology also in the binary task of detecting real vs fake images, achieving an average accuracy of 88.41%. We obtain our best result on GenImage with an accuracy of 95.06%, whereas the original benchmark achieved 82.20%. Our results demonstrate the effectiveness of frequency-domain fingerprinting for cross-architecture and cross-dataset model attribution, offering a viable solution for enforcing accountability and trust in generative AI systems.
Multimodal Coordinated Online Behavior: Trade-offs and Strategies
Jul 16, 2025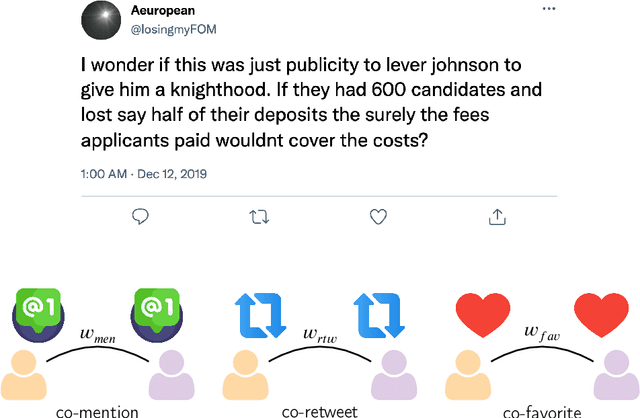



Coordinated online behavior, which spans from beneficial collective actions to harmful manipulation such as disinformation campaigns, has become a key focus in digital ecosystem analysis. Traditional methods often rely on monomodal approaches, focusing on single types of interactions like co-retweets or co-hashtags, or consider multiple modalities independently of each other. However, these approaches may overlook the complex dynamics inherent in multimodal coordination. This study compares different ways of operationalizing the detection of multimodal coordinated behavior. It examines the trade-off between weakly and strongly integrated multimodal models, highlighting the balance between capturing broader coordination patterns and identifying tightly coordinated behavior. By comparing monomodal and multimodal approaches, we assess the unique contributions of different data modalities and explore how varying implementations of multimodality impact detection outcomes. Our findings reveal that not all the modalities provide distinct insights, but that with a multimodal approach we can get a more comprehensive understanding of coordination dynamics. This work enhances the ability to detect and analyze coordinated online behavior, offering new perspectives for safeguarding the integrity of digital platforms.
Geo-Semantic-Parsing: AI-powered geoparsing by traversing semantic knowledge graphs
Mar 03, 2025



Online social networks convey rich information about geospatial facets of reality. However in most cases, geographic information is not explicit and structured, thus preventing its exploitation in real-time applications. We address this limitation by introducing a novel geoparsing and geotagging technique called Geo-Semantic-Parsing (GSP). GSP identifies location references in free text and extracts the corresponding geographic coordinates. To reach this goal, we employ a semantic annotator to identify relevant portions of the input text and to link them to the corresponding entity in a knowledge graph. Then, we devise and experiment with several efficient strategies for traversing the knowledge graph, thus expanding the available set of information for the geoparsing task. Finally, we exploit all available information for learning a regression model that selects the best entity with which to geotag the input text. We evaluate GSP on a well-known reference dataset including almost 10k event-related tweets, achieving $F1=0.66$. We extensively compare our results with those of 2 baselines and 3 state-of-the-art geoparsing techniques, achieving the best performance. On the same dataset, competitors obtain $F1 \leq 0.55$. We conclude by providing in-depth analyses of our results, showing that the overall superior performance of GSP is mainly due to a large improvement in recall, with respect to existing techniques.
* Postprint of the article published in the Decision Support Systems journal. Please, cite accordingly
Contextualized Counterspeech: Strategies for Adaptation, Personalization, and Evaluation
Dec 10, 2024
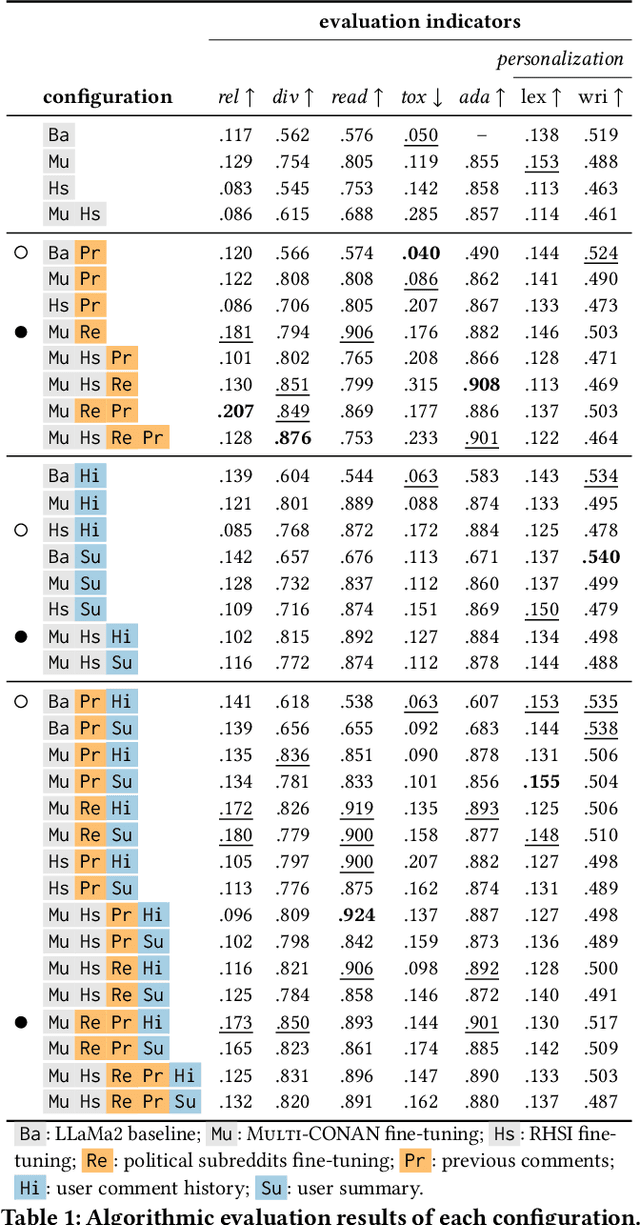
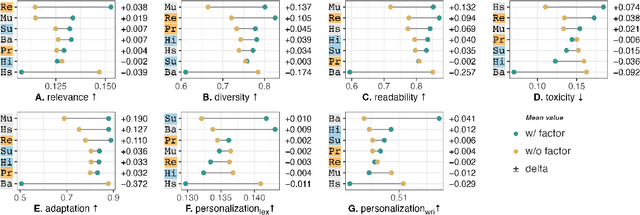

AI-generated counterspeech offers a promising and scalable strategy to curb online toxicity through direct replies that promote civil discourse. However, current counterspeech is one-size-fits-all, lacking adaptation to the moderation context and the users involved. We propose and evaluate multiple strategies for generating tailored counterspeech that is adapted to the moderation context and personalized for the moderated user. We instruct an LLaMA2-13B model to generate counterspeech, experimenting with various configurations based on different contextual information and fine-tuning strategies. We identify the configurations that generate persuasive counterspeech through a combination of quantitative indicators and human evaluations collected via a pre-registered mixed-design crowdsourcing experiment. Results show that contextualized counterspeech can significantly outperform state-of-the-art generic counterspeech in adequacy and persuasiveness, without compromising other characteristics. Our findings also reveal a poor correlation between quantitative indicators and human evaluations, suggesting that these methods assess different aspects and highlighting the need for nuanced evaluation methodologies. The effectiveness of contextualized AI-generated counterspeech and the divergence between human and algorithmic evaluations underscore the importance of increased human-AI collaboration in content moderation.
Human and LLM Biases in Hate Speech Annotations: A Socio-Demographic Analysis of Annotators and Targets
Oct 10, 2024


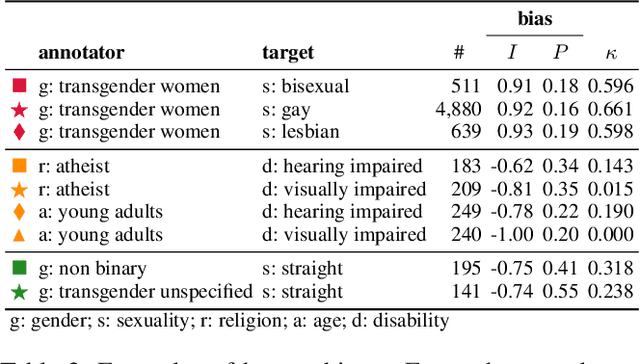
The rise of online platforms exacerbated the spread of hate speech, demanding scalable and effective detection. However, the accuracy of hate speech detection systems heavily relies on human-labeled data, which is inherently susceptible to biases. While previous work has examined the issue, the interplay between the characteristics of the annotator and those of the target of the hate are still unexplored. We fill this gap by leveraging an extensive dataset with rich socio-demographic information of both annotators and targets, uncovering how human biases manifest in relation to the target's attributes. Our analysis surfaces the presence of widespread biases, which we quantitatively describe and characterize based on their intensity and prevalence, revealing marked differences. Furthermore, we compare human biases with those exhibited by persona-based LLMs. Our findings indicate that while persona-based LLMs do exhibit biases, these differ significantly from those of human annotators. Overall, our work offers new and nuanced results on human biases in hate speech annotations, as well as fresh insights into the design of AI-driven hate speech detection systems.
Detection and Characterization of Coordinated Online Behavior: A Survey
Aug 02, 2024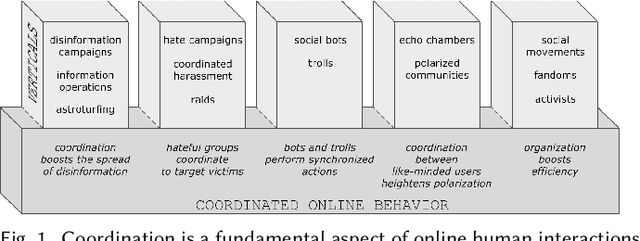

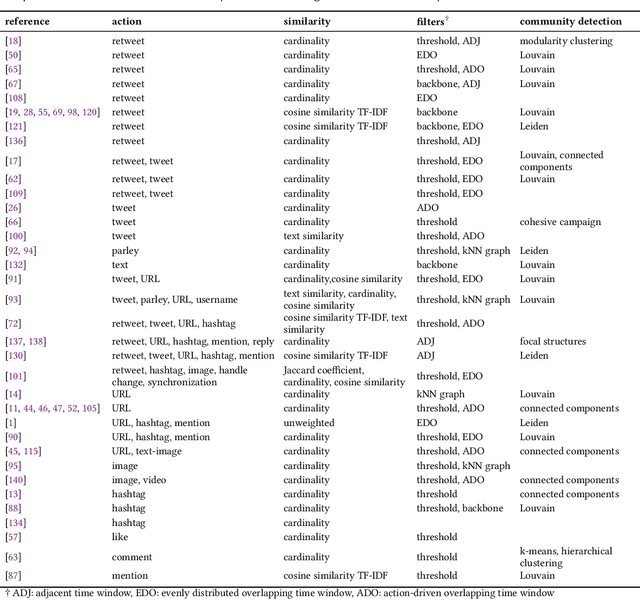
Coordination is a fundamental aspect of life. The advent of social media has made it integral also to online human interactions, such as those that characterize thriving online communities and social movements. At the same time, coordination is also core to effective disinformation, manipulation, and hate campaigns. This survey collects, categorizes, and critically discusses the body of work produced as a result of the growing interest on coordinated online behavior. We reconcile industry and academic definitions, propose a comprehensive framework to study coordinated online behavior, and review and critically discuss the existing detection and characterization methods. Our analysis identifies open challenges and promising directions of research, serving as a guide for scholars, practitioners, and policymakers in understanding and addressing the complexities inherent to online coordination.
The DSA Transparency Database: Auditing Self-reported Moderation Actions by Social Media
Dec 16, 2023



Since September 2023, the Digital Services Act (DSA) obliges large online platforms to submit detailed data on each moderation action they take within the European Union (EU) to the DSA Transparency Database. From its inception, this centralized database has sparked scholarly interest as an unprecedented and potentially unique trove of data on real-world online moderation. Here, we thoroughly analyze all 195.61M records submitted by the eight largest social media platforms in the EU during the first 60 days of the database. Specifically, we conduct a platform-wise comparative study of their: volume of moderation actions, grounds for decision, types of applied restrictions, types of moderated content, timeliness in undertaking and submitting moderation actions, and use of automation. Furthermore, we systematically cross-check the contents of the database with the platforms' own transparency reports. Our analyses reveal that (i) the platforms adhered only in part to the philosophy and structure of the database, (ii) the structure of the database is partially inadequate for the platforms' reporting needs, (iii) the platforms exhibited substantial differences in their moderation actions, (iv) a remarkable fraction of the database data is inconsistent, (v) the platform X (formerly Twitter) presents the most inconsistencies. Our findings have far-reaching implications for policymakers and scholars across diverse disciplines. They offer guidance for future regulations that cater to the reporting needs of online platforms in general, but also highlight opportunities to improve and refine the database itself.
Demystifying Misconceptions in Social Bots Research
Mar 30, 2023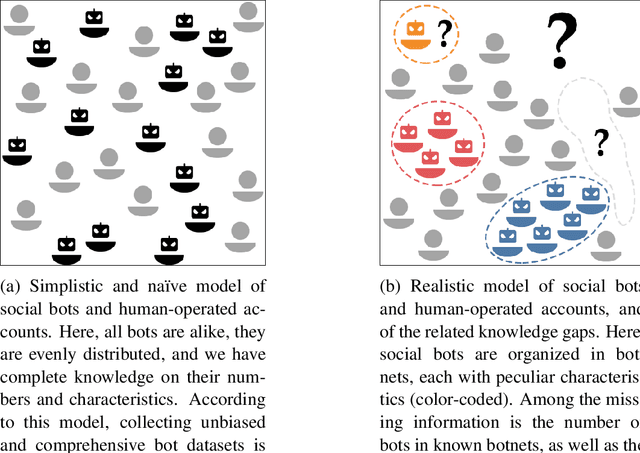
The science of social bots seeks knowledge and solutions to one of the most debated forms of online misinformation. Yet, social bots research is plagued by widespread biases, hyped results, and misconceptions that set the stage for ambiguities, unrealistic expectations, and seemingly irreconcilable findings. Overcoming such issues is instrumental towards ensuring reliable solutions and reaffirming the validity of the scientific method. In this contribution we revise some recent results in social bots research, highlighting and correcting factual errors as well as methodological and conceptual issues. More importantly, we demystify common misconceptions, addressing fundamental points on how social bots research is discussed. Our analysis surfaces the need to discuss misinformation research in a rigorous, unbiased, and responsible way. This article bolsters such effort by identifying and refuting common fallacious arguments used by both proponents and opponents of social bots research as well as providing indications on the correct methodologies and sound directions for future research in the field.