 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman and LLM Biases in Hate Speech Annotations: A Socio-Demographic Analysis of Annotators and Targets
Oct 10, 2024


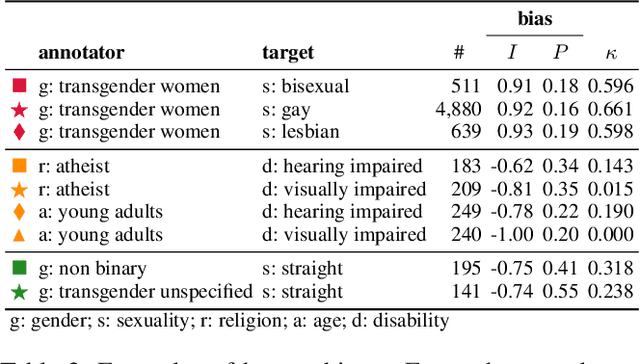
The rise of online platforms exacerbated the spread of hate speech, demanding scalable and effective detection. However, the accuracy of hate speech detection systems heavily relies on human-labeled data, which is inherently susceptible to biases. While previous work has examined the issue, the interplay between the characteristics of the annotator and those of the target of the hate are still unexplored. We fill this gap by leveraging an extensive dataset with rich socio-demographic information of both annotators and targets, uncovering how human biases manifest in relation to the target's attributes. Our analysis surfaces the presence of widespread biases, which we quantitatively describe and characterize based on their intensity and prevalence, revealing marked differences. Furthermore, we compare human biases with those exhibited by persona-based LLMs. Our findings indicate that while persona-based LLMs do exhibit biases, these differ significantly from those of human annotators. Overall, our work offers new and nuanced results on human biases in hate speech annotations, as well as fresh insights into the design of AI-driven hate speech detection systems.
The DSA Transparency Database: Auditing Self-reported Moderation Actions by Social Media
Dec 16, 2023



Since September 2023, the Digital Services Act (DSA) obliges large online platforms to submit detailed data on each moderation action they take within the European Union (EU) to the DSA Transparency Database. From its inception, this centralized database has sparked scholarly interest as an unprecedented and potentially unique trove of data on real-world online moderation. Here, we thoroughly analyze all 195.61M records submitted by the eight largest social media platforms in the EU during the first 60 days of the database. Specifically, we conduct a platform-wise comparative study of their: volume of moderation actions, grounds for decision, types of applied restrictions, types of moderated content, timeliness in undertaking and submitting moderation actions, and use of automation. Furthermore, we systematically cross-check the contents of the database with the platforms' own transparency reports. Our analyses reveal that (i) the platforms adhered only in part to the philosophy and structure of the database, (ii) the structure of the database is partially inadequate for the platforms' reporting needs, (iii) the platforms exhibited substantial differences in their moderation actions, (iv) a remarkable fraction of the database data is inconsistent, (v) the platform X (formerly Twitter) presents the most inconsistencies. Our findings have far-reaching implications for policymakers and scholars across diverse disciplines. They offer guidance for future regulations that cater to the reporting needs of online platforms in general, but also highlight opportunities to improve and refine the database itself.
Personalized Interventions for Online Moderation
May 19, 2022

Current online moderation follows a one-size-fits-all approach, where each intervention is applied in the same way to all users. This naive approach is challenged by established socio-behavioral theories and by recent empirical results that showed the limited effectiveness of such interventions. We propose a paradigm-shift in online moderation by moving towards a personalized and user-centered approach. Our multidisciplinary vision combines state-of-the-art theories and practices in diverse fields such as computer science, sociology and psychology, to design personalized moderation interventions (PMIs). In outlining the path leading to the next-generation of moderation interventions, we also discuss the most prominent challenges introduced by such a disruptive change.
Tweets2Stance: Users stance detection exploiting Zero-Shot Learning Algorithms on Tweets
Apr 22, 2022


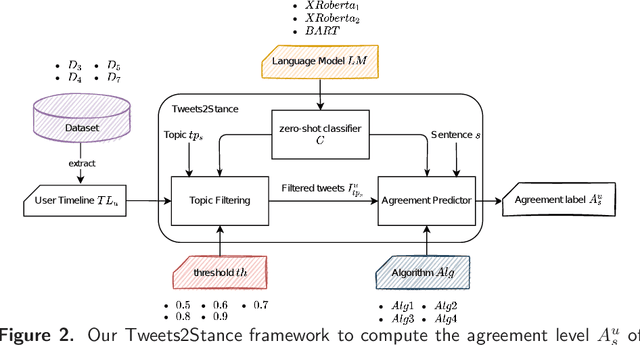
In the last years there has been a growing attention towards predicting the political orientation of active social media users, being this of great help to study political forecasts, opinion dynamics modeling and users polarization. Existing approaches, mainly targeting Twitter users, rely on content-based analysis or are based on a mixture of content, network and communication analysis. The recent research perspective exploits the fact that a user's political affinity mainly depends on his/her positions on major political and social issues, thus shifting the focus on detecting the stance of users through user-generated content shared on social networks. The work herein described focuses on a completely unsupervised stance detection framework that predicts the user's stance about specific social-political statements by exploiting content-based analysis of its Twitter timeline. The ground-truth user's stance may come from Voting Advice Applications, online tools that help citizens to identify their political leanings by comparing their political preferences with party political stances. Starting from the knowledge of the agreement level of six parties on 20 different statements, the objective of the study is to predict the stance of a Party p in regard to each statement s exploiting what the Twitter Party account wrote on Twitter. To this end we propose Tweets2Stance (T2S), a novel and totally unsupervised stance detector framework which relies on the zero-shot learning technique to quickly and accurately operate on non-labeled data. Interestingly, T2S can be applied to any social media user for any context of interest, not limited to the political one. Results obtained from multiple experiments show that, although the general maximum F1 value is 0.4, T2S can correctly predict the stance with a general minimum MAE of 1.13, which is a great achievement considering the task complexity.
Fine-Grained Prediction of Political Leaning on Social Media with Unsupervised Deep Learning
Feb 23, 2022


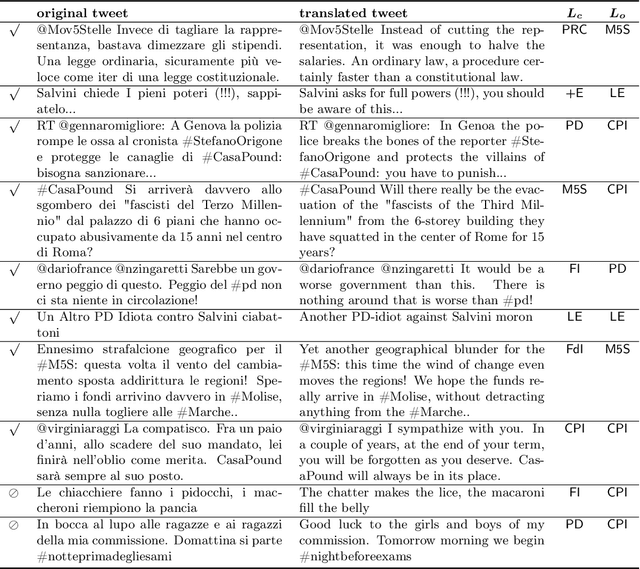
Predicting the political leaning of social media users is an increasingly popular task, given its usefulness for electoral forecasts, opinion dynamics models and for studying the political dimension of polarization and disinformation. Here, we propose a novel unsupervised technique for learning fine-grained political leaning from the textual content of social media posts. Our technique leverages a deep neural network for learning latent political ideologies in a representation learning task. Then, users are projected in a low-dimensional ideology space where they are subsequently clustered. The political leaning of a user is automatically derived from the cluster to which the user is assigned. We evaluated our technique in two challenging classification tasks and we compared it to baselines and other state-of-the-art approaches. Our technique obtains the best results among all unsupervised techniques, with micro F1 = 0.426 in the 8-class task and micro F1 = 0.772 in the 3-class task. Other than being interesting on their own, our results also pave the way for the development of new and better unsupervised approaches for the detection of fine-grained political leaning.
TweepFake: about Detecting Deepfake Tweets
Jul 31, 2020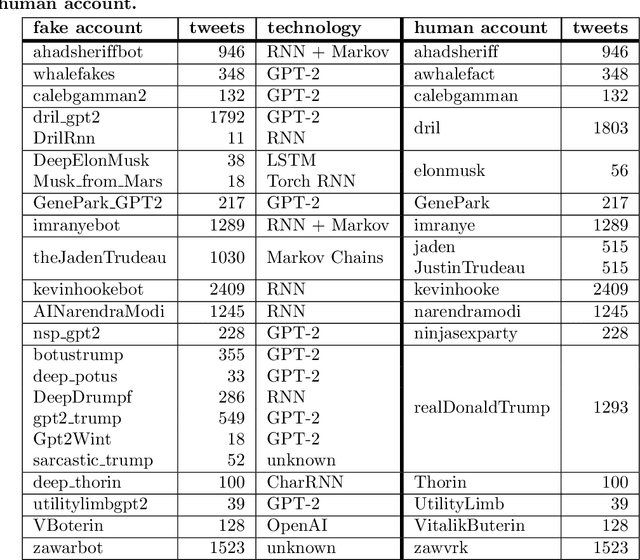
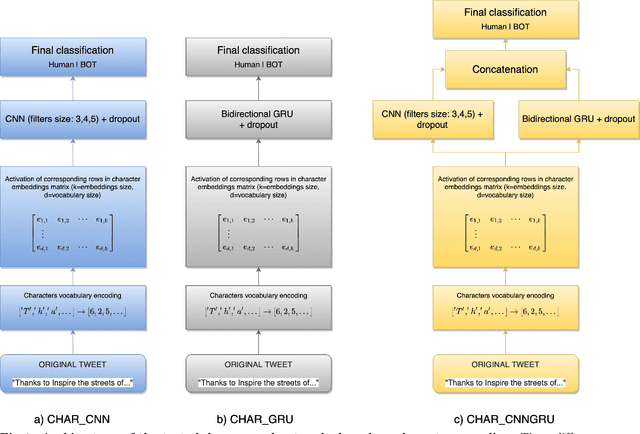

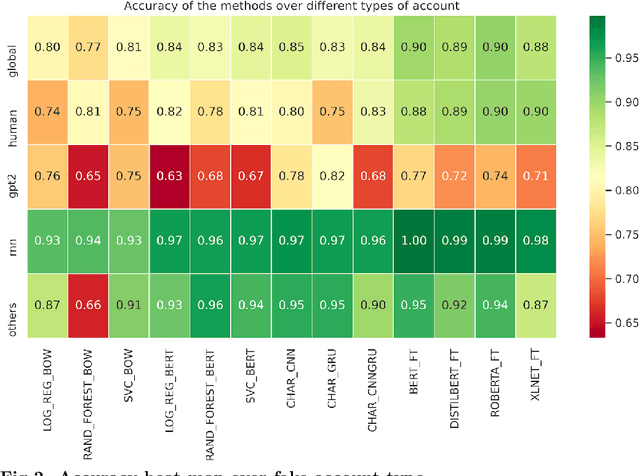
The threat of deepfakes, synthetic, or manipulated media, is becoming increasingly alarming, especially for social media platforms that have already been accused of manipulating public opinion. Even the cheapest text generation techniques (e.g. the search-and-replace method) can deceive humans, as the Net Neutrality scandal proved in 2017. Meanwhile, more powerful generative models have been released, from RNN-based methods to the GPT-2 language model. State-of-the-art language models, transformer-based in particular, can generate synthetic text in response to the model being primed with arbitrary input. Thus, Therefore, it is crucial to develop tools that help to detect media authenticity. To help the research in this field, we collected a dataset of real Deepfake tweets. It is real in the sense that each deepfake tweet was actually posted on Twitter. We collected tweets from a total of 23 bots, imitating 17 human accounts. The bots are based on various generation techniques, i.e., Markov Chains, RNN, RNN+Markov, LSTM, GPT-2. We also randomly selected tweets from the humans imitated by the bots to have an overall balanced dataset of 25,836 tweets (half human and half bots generated). The dataset is publicly available on Kaggle. In order to create a solid baseline for detection techniques on the proposed dataset we tested 13 detection methods based on various state-of-the-art approaches. The detection results reported as a baseline using 13 detection methods, confirm that the newest and more sophisticated generative methods based on transformer architecture (e.g., GPT-2) can produce high-quality short texts, difficult to detect.
JaTeCS an open-source JAva TExt Categorization System
Jun 21, 2017
JaTeCS is an open source Java library that supports research on automatic text categorization and other related problems, such as ordinal regression and quantification, which are of special interest in opinion mining applications. It covers all the steps of an experimental activity, from reading the corpus to the evaluation of the experimental results. As JaTeCS is focused on text as the main input data, it provides the user with many text-dedicated tools, e.g.: data readers for many formats, including the most commonly used text corpora and lexical resources, natural language processing tools, multi-language support, methods for feature selection and weighting, the implementation of many machine learning algorithms as well as wrappers for well-known external software (e.g., SVM_light) which enable their full control from code. JaTeCS support its expansion by abstracting through interfaces many of the typical tools and procedures used in text processing tasks. The library also provides a number of "template" implementations of typical experimental setups (e.g., train-test, k-fold validation, grid-search optimization, randomized runs) which enable fast realization of experiments just by connecting the templates with data readers, learning algorithms and evaluation measures.
Picture It In Your Mind: Generating High Level Visual Representations From Textual Descriptions
Jun 23, 2016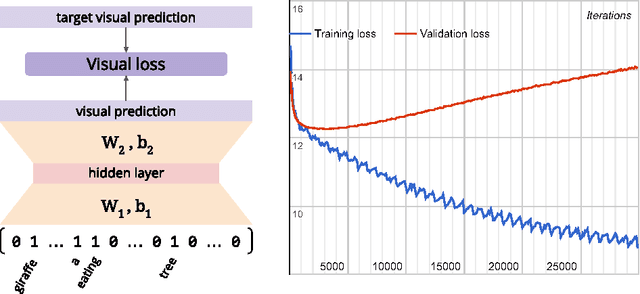
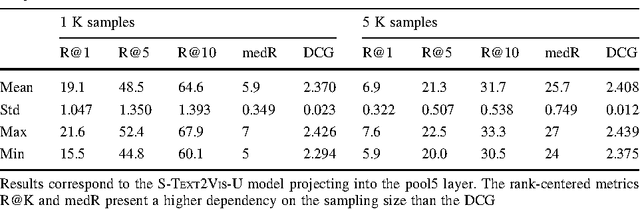
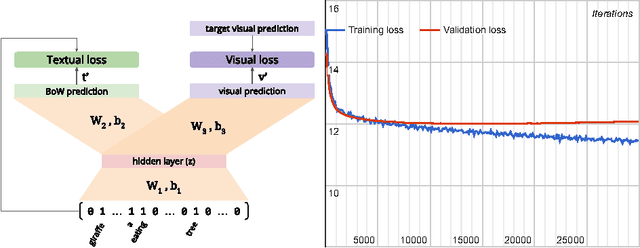
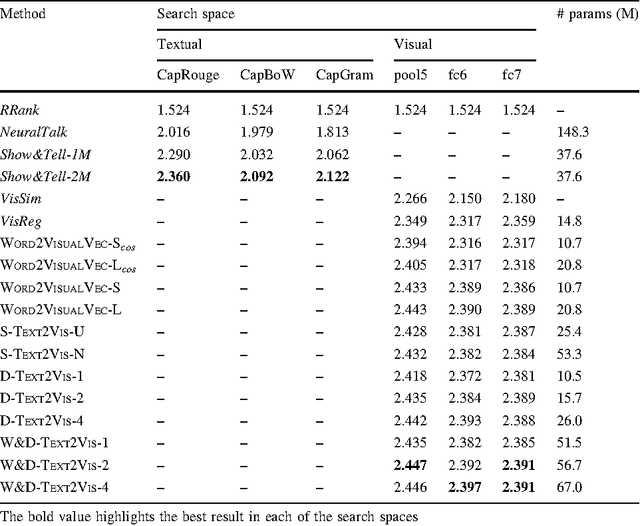
In this paper we tackle the problem of image search when the query is a short textual description of the image the user is looking for. We choose to implement the actual search process as a similarity search in a visual feature space, by learning to translate a textual query into a visual representation. Searching in the visual feature space has the advantage that any update to the translation model does not require to reprocess the, typically huge, image collection on which the search is performed. We propose Text2Vis, a neural network that generates a visual representation, in the visual feature space of the fc6-fc7 layers of ImageNet, from a short descriptive text. Text2Vis optimizes two loss functions, using a stochastic loss-selection method. A visual-focused loss is aimed at learning the actual text-to-visual feature mapping, while a text-focused loss is aimed at modeling the higher-level semantic concepts expressed in language and countering the overfit on non-relevant visual components of the visual loss. We report preliminary results on the MS-COCO dataset.