 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeo-Semantic-Parsing: AI-powered geoparsing by traversing semantic knowledge graphs
Mar 03, 2025



Online social networks convey rich information about geospatial facets of reality. However in most cases, geographic information is not explicit and structured, thus preventing its exploitation in real-time applications. We address this limitation by introducing a novel geoparsing and geotagging technique called Geo-Semantic-Parsing (GSP). GSP identifies location references in free text and extracts the corresponding geographic coordinates. To reach this goal, we employ a semantic annotator to identify relevant portions of the input text and to link them to the corresponding entity in a knowledge graph. Then, we devise and experiment with several efficient strategies for traversing the knowledge graph, thus expanding the available set of information for the geoparsing task. Finally, we exploit all available information for learning a regression model that selects the best entity with which to geotag the input text. We evaluate GSP on a well-known reference dataset including almost 10k event-related tweets, achieving $F1=0.66$. We extensively compare our results with those of 2 baselines and 3 state-of-the-art geoparsing techniques, achieving the best performance. On the same dataset, competitors obtain $F1 \leq 0.55$. We conclude by providing in-depth analyses of our results, showing that the overall superior performance of GSP is mainly due to a large improvement in recall, with respect to existing techniques.
* Postprint of the article published in the Decision Support Systems journal. Please, cite accordingly
Contextualized Counterspeech: Strategies for Adaptation, Personalization, and Evaluation
Dec 10, 2024
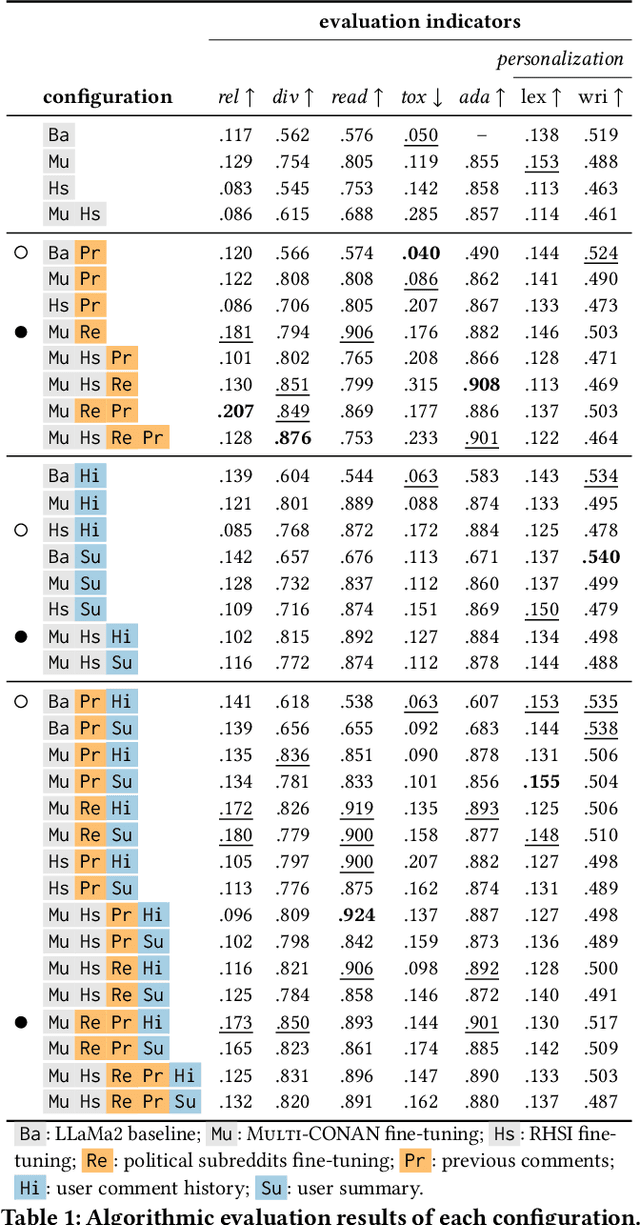
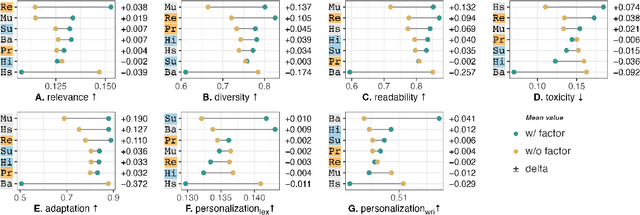

AI-generated counterspeech offers a promising and scalable strategy to curb online toxicity through direct replies that promote civil discourse. However, current counterspeech is one-size-fits-all, lacking adaptation to the moderation context and the users involved. We propose and evaluate multiple strategies for generating tailored counterspeech that is adapted to the moderation context and personalized for the moderated user. We instruct an LLaMA2-13B model to generate counterspeech, experimenting with various configurations based on different contextual information and fine-tuning strategies. We identify the configurations that generate persuasive counterspeech through a combination of quantitative indicators and human evaluations collected via a pre-registered mixed-design crowdsourcing experiment. Results show that contextualized counterspeech can significantly outperform state-of-the-art generic counterspeech in adequacy and persuasiveness, without compromising other characteristics. Our findings also reveal a poor correlation between quantitative indicators and human evaluations, suggesting that these methods assess different aspects and highlighting the need for nuanced evaluation methodologies. The effectiveness of contextualized AI-generated counterspeech and the divergence between human and algorithmic evaluations underscore the importance of increased human-AI collaboration in content moderation.
Human and LLM Biases in Hate Speech Annotations: A Socio-Demographic Analysis of Annotators and Targets
Oct 10, 2024


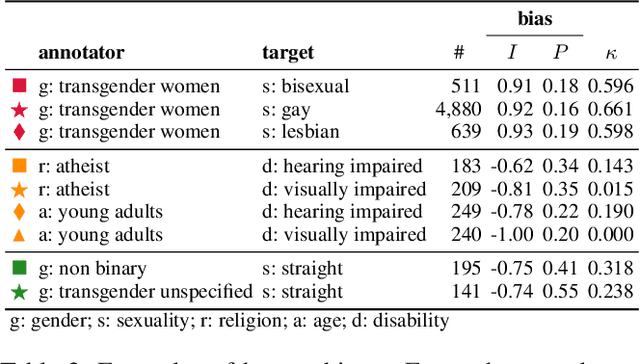
The rise of online platforms exacerbated the spread of hate speech, demanding scalable and effective detection. However, the accuracy of hate speech detection systems heavily relies on human-labeled data, which is inherently susceptible to biases. While previous work has examined the issue, the interplay between the characteristics of the annotator and those of the target of the hate are still unexplored. We fill this gap by leveraging an extensive dataset with rich socio-demographic information of both annotators and targets, uncovering how human biases manifest in relation to the target's attributes. Our analysis surfaces the presence of widespread biases, which we quantitatively describe and characterize based on their intensity and prevalence, revealing marked differences. Furthermore, we compare human biases with those exhibited by persona-based LLMs. Our findings indicate that while persona-based LLMs do exhibit biases, these differ significantly from those of human annotators. Overall, our work offers new and nuanced results on human biases in hate speech annotations, as well as fresh insights into the design of AI-driven hate speech detection systems.
Mind the Prompt: A Novel Benchmark for Prompt-based Class-Agnostic Counting
Sep 24, 2024Class-agnostic counting (CAC) is a recent task in computer vision that aims to estimate the number of instances of arbitrary object classes never seen during model training. With the recent advancement of robust vision-and-language foundation models, there is a growing interest in prompt-based CAC, where object categories to be counted can be specified using natural language. However, we identify significant limitations in current benchmarks for evaluating this task, which hinder both accurate assessment and the development of more effective solutions. Specifically, we argue that the current evaluation protocols do not measure the ability of the model to understand which object has to be counted. This is due to two main factors: (i) the shortcomings of CAC datasets, which primarily consist of images containing objects from a single class, and (ii) the limitations of current counting performance evaluators, which are based on traditional class-specific counting and focus solely on counting errors. To fill this gap, we introduce the Prompt-Aware Counting (PrACo) benchmark, which comprises two targeted tests, each accompanied by appropriate evaluation metrics. We evaluate state-of-the-art methods and demonstrate that, although some achieve impressive results on standard class-specific counting metrics, they exhibit a significant deficiency in understanding the input prompt, indicating the need for more careful training procedures or revised designs. The code for reproducing our results is available at https://github.com/ciampluca/PrACo.
A Spatio-Temporal Attentive Network for Video-Based Crowd Counting
Aug 24, 2022
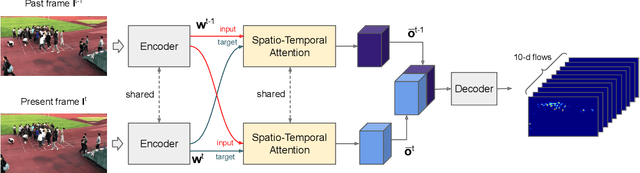
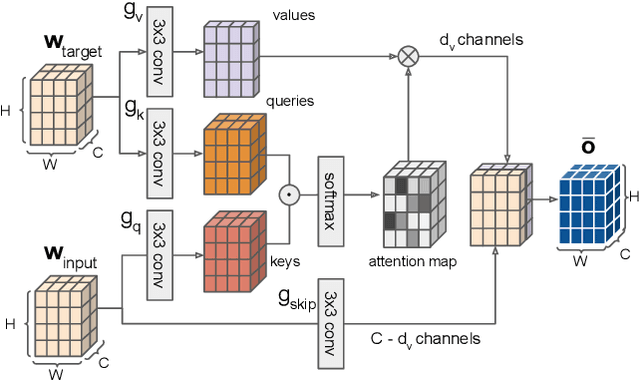
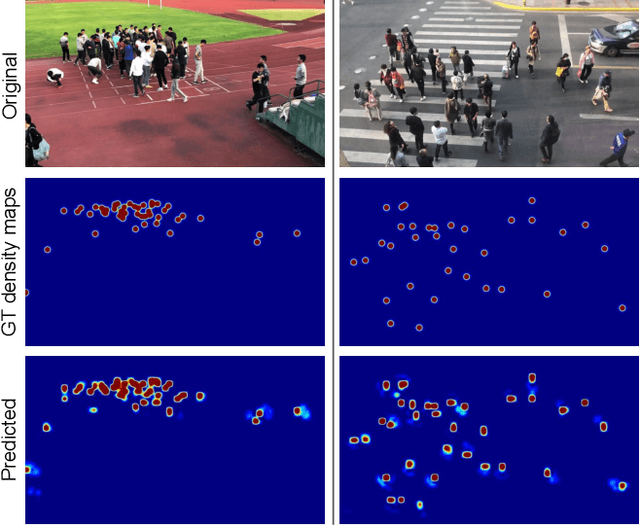
Automatic people counting from images has recently drawn attention for urban monitoring in modern Smart Cities due to the ubiquity of surveillance camera networks. Current computer vision techniques rely on deep learning-based algorithms that estimate pedestrian densities in still, individual images. Only a bunch of works take advantage of temporal consistency in video sequences. In this work, we propose a spatio-temporal attentive neural network to estimate the number of pedestrians from surveillance videos. By taking advantage of the temporal correlation between consecutive frames, we lowered state-of-the-art count error by 5% and localization error by 7.5% on the widely-used FDST benchmark.
Towards better social crisis data with HERMES: Hybrid sensing for EmeRgency ManagEment System
Dec 04, 2019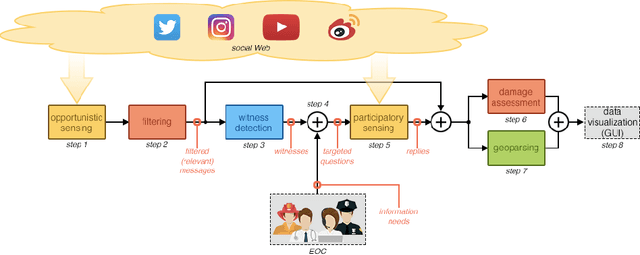
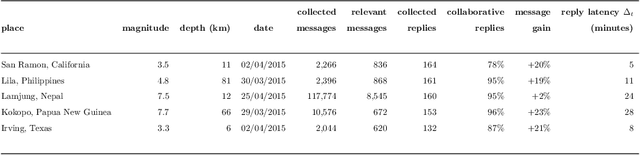
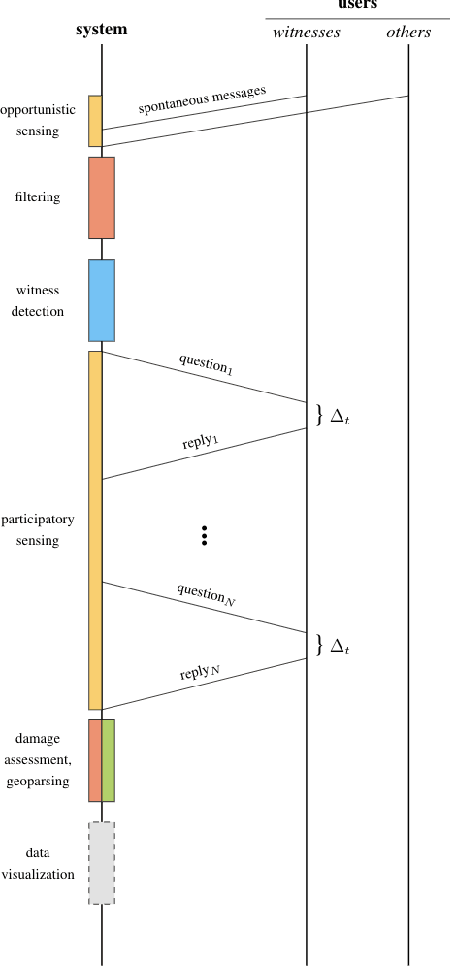
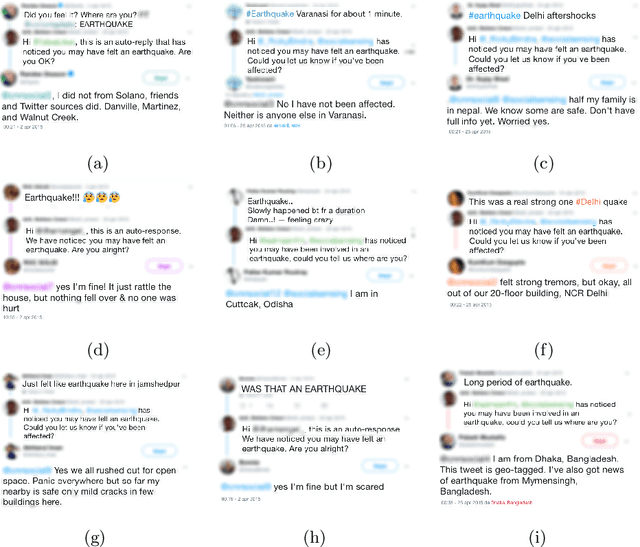
People involved in mass emergencies increasingly publish information-rich contents in online social networks (OSNs), thus acting as a distributed and resilient network of human sensors. In this work, we present HERMES, a system designed to enrich the information spontaneously disclosed by OSN users in the aftermath of disasters. HERMES leverages a mixed data collection strategy, called hybrid crowdsensing, and state-of-the-art AI techniques. Evaluated in real-world emergencies, HERMES proved to increase: (i) the amount of the available damage information; (ii) the density (up to 7x) and the variety (up to 18x) of the retrieved geographic information; (iii) the geographic coverage (up to 30%) and granularity.
RTbust: Exploiting Temporal Patterns for Botnet Detection on Twitter
Feb 12, 2019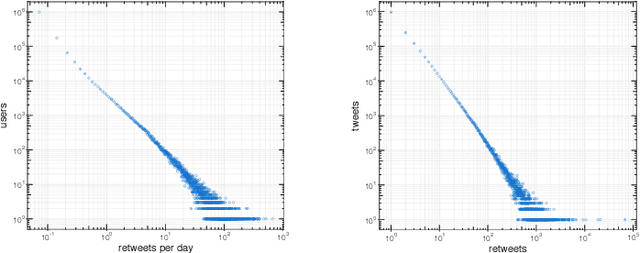

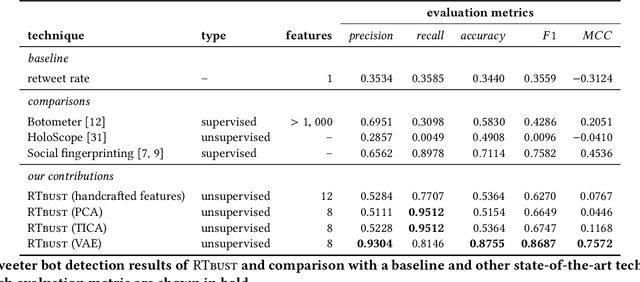
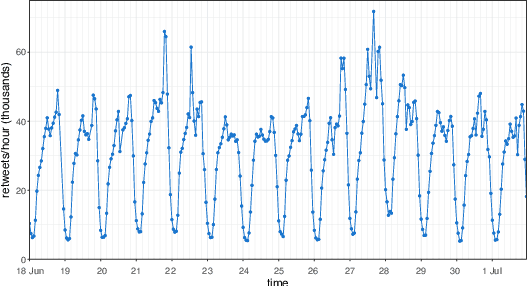
Within OSNs, many of our supposedly online friends may instead be fake accounts called social bots, part of large groups that purposely re-share targeted content. Here, we study retweeting behaviors on Twitter, with the ultimate goal of detecting retweeting social bots. We collect a dataset of 10M retweets. We design a novel visualization that we leverage to highlight benign and malicious patterns of retweeting activity. In this way, we uncover a 'normal' retweeting pattern that is peculiar of human-operated accounts, and 3 suspicious patterns related to bot activities. Then, we propose a bot detection technique that stems from the previous exploration of retweeting behaviors. Our technique, called Retweet-Buster (RTbust), leverages unsupervised feature extraction and clustering. An LSTM autoencoder converts the retweet time series into compact and informative latent feature vectors, which are then clustered with a hierarchical density-based algorithm. Accounts belonging to large clusters characterized by malicious retweeting patterns are labeled as bots. RTbust obtains excellent detection results, with F1 = 0.87, whereas competitors achieve F1 < 0.76. Finally, we apply RTbust to a large dataset of retweets, uncovering 2 previously unknown active botnets with hundreds of accounts.