 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Geometric Analysis of Small-sized Language Model Hallucinations
Feb 16, 2026Hallucinations -- fluent but factually incorrect responses -- pose a major challenge to the reliability of language models, especially in multi-step or agentic settings. This work investigates hallucinations in small-sized LLMs through a geometric perspective, starting from the hypothesis that when models generate multiple responses to the same prompt, genuine ones exhibit tighter clustering in the embedding space, we prove this hypothesis and, leveraging this geometrical insight, we also show that it is possible to achieve a consistent level of separability. This latter result is used to introduce a label-efficient propagation method that classifies large collections of responses from just 30-50 annotations, achieving F1 scores above 90%. Our findings, framing hallucinations from a geometric perspective in the embedding space, complement traditional knowledge-centric and single-response evaluation paradigms, paving the way for further research.
The Big Ban Theory: A Pre- and Post-Intervention Dataset of Online Content Moderation Actions
Jan 16, 2026Online platforms rely on moderation interventions to curb harmful behavior such hate speech, toxicity, and the spread of mis- and disinformation. Yet research on the effects and possible biases of such interventions faces multiple limitations. For example, existing works frequently focus on single or a few interventions, due to the absence of comprehensive datasets. As a result, researchers must typically collect the necessary data for each new study, which limits opportunities for systematic comparisons. To overcome these challenges, we introduce The Big Ban Theory (TBBT), a large dataset of moderation interventions. TBBT covers 25 interventions of varying type, severity, and scope, comprising in total over 339K users and nearly 39M posted messages. For each intervention, we provide standardized metadata and pseudonymized user activity collected three months before and after its enforcement, enabling consistent and comparable analyses of intervention effects. In addition, we provide a descriptive exploratory analysis of the dataset, along with several use cases of how it can support research on content moderation. With this dataset, we aim to support researchers studying the effects of moderation interventions and to promote more systematic, reproducible, and comparable research. TBBT is publicly available at: https://doi.org/10.5281/zenodo.18245670.
PRISM: Phase-enhanced Radial-based Image Signature Mapping framework for fingerprinting AI-generated images
Sep 18, 2025A critical need has emerged for generative AI: attribution methods. That is, solutions that can identify the model originating AI-generated content. This feature, generally relevant in multimodal applications, is especially sensitive in commercial settings where users subscribe to paid proprietary services and expect guarantees about the source of the content they receive. To address these issues, we introduce PRISM, a scalable Phase-enhanced Radial-based Image Signature Mapping framework for fingerprinting AI-generated images. PRISM is based on a radial reduction of the discrete Fourier transform that leverages amplitude and phase information to capture model-specific signatures. The output of the above process is subsequently clustered via linear discriminant analysis to achieve reliable model attribution in diverse settings, even if the model's internal details are inaccessible. To support our work, we construct PRISM-36K, a novel dataset of 36,000 images generated by six text-to-image GAN- and diffusion-based models. On this dataset, PRISM achieves an attribution accuracy of 92.04%. We additionally evaluate our method on four benchmarks from the literature, reaching an average accuracy of 81.60%. Finally, we evaluate our methodology also in the binary task of detecting real vs fake images, achieving an average accuracy of 88.41%. We obtain our best result on GenImage with an accuracy of 95.06%, whereas the original benchmark achieved 82.20%. Our results demonstrate the effectiveness of frequency-domain fingerprinting for cross-architecture and cross-dataset model attribution, offering a viable solution for enforcing accountability and trust in generative AI systems.
Hallucination Detection: A Probabilistic Framework Using Embeddings Distance Analysis
Feb 10, 2025



Hallucinations are one of the major issues affecting LLMs, hindering their wide adoption in production systems. While current research solutions for detecting hallucinations are mainly based on heuristics, in this paper we introduce a mathematically sound methodology to reason about hallucination, and leverage it to build a tool to detect hallucinations. To the best of our knowledge, we are the first to show that hallucinated content has structural differences with respect to correct content. To prove this result, we resort to the Minkowski distances in the embedding space. Our findings demonstrate statistically significant differences in the embedding distance distributions, that are also scale free -- they qualitatively hold regardless of the distance norm used and the number of keywords, questions, or responses. We leverage these structural differences to develop a tool to detect hallucinated responses, achieving an accuracy of 66\% for a specific configuration of system parameters -- comparable with the best results in the field. In conclusion, the suggested methodology is promising and novel, possibly paving the way for further research in the domain, also along the directions highlighted in our future work.
Contextualized Counterspeech: Strategies for Adaptation, Personalization, and Evaluation
Dec 10, 2024
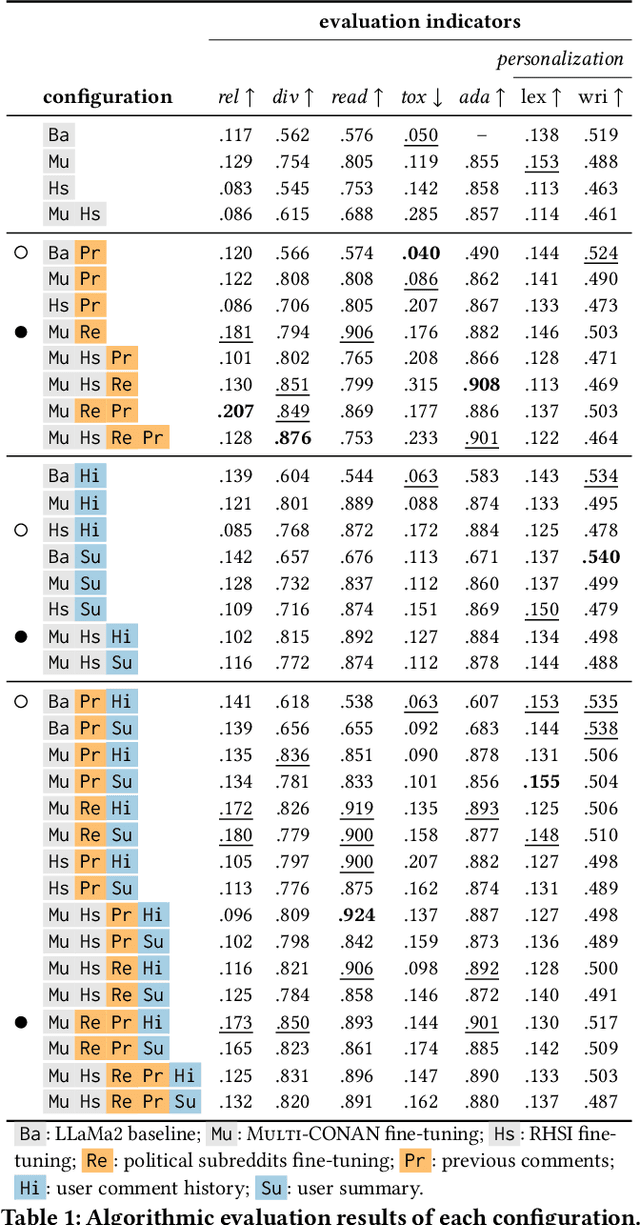
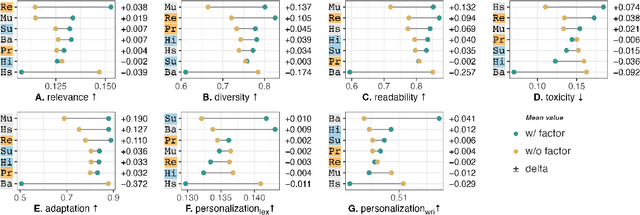

AI-generated counterspeech offers a promising and scalable strategy to curb online toxicity through direct replies that promote civil discourse. However, current counterspeech is one-size-fits-all, lacking adaptation to the moderation context and the users involved. We propose and evaluate multiple strategies for generating tailored counterspeech that is adapted to the moderation context and personalized for the moderated user. We instruct an LLaMA2-13B model to generate counterspeech, experimenting with various configurations based on different contextual information and fine-tuning strategies. We identify the configurations that generate persuasive counterspeech through a combination of quantitative indicators and human evaluations collected via a pre-registered mixed-design crowdsourcing experiment. Results show that contextualized counterspeech can significantly outperform state-of-the-art generic counterspeech in adequacy and persuasiveness, without compromising other characteristics. Our findings also reveal a poor correlation between quantitative indicators and human evaluations, suggesting that these methods assess different aspects and highlighting the need for nuanced evaluation methodologies. The effectiveness of contextualized AI-generated counterspeech and the divergence between human and algorithmic evaluations underscore the importance of increased human-AI collaboration in content moderation.
Human and LLM Biases in Hate Speech Annotations: A Socio-Demographic Analysis of Annotators and Targets
Oct 10, 2024


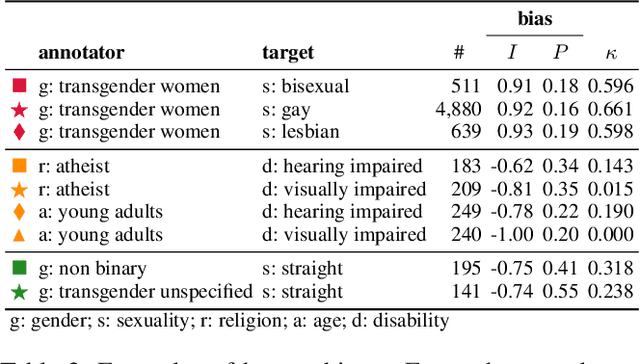
The rise of online platforms exacerbated the spread of hate speech, demanding scalable and effective detection. However, the accuracy of hate speech detection systems heavily relies on human-labeled data, which is inherently susceptible to biases. While previous work has examined the issue, the interplay between the characteristics of the annotator and those of the target of the hate are still unexplored. We fill this gap by leveraging an extensive dataset with rich socio-demographic information of both annotators and targets, uncovering how human biases manifest in relation to the target's attributes. Our analysis surfaces the presence of widespread biases, which we quantitatively describe and characterize based on their intensity and prevalence, revealing marked differences. Furthermore, we compare human biases with those exhibited by persona-based LLMs. Our findings indicate that while persona-based LLMs do exhibit biases, these differ significantly from those of human annotators. Overall, our work offers new and nuanced results on human biases in hate speech annotations, as well as fresh insights into the design of AI-driven hate speech detection systems.