 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Counterspeech: Strategies for Adaptation, Personalization, and Evaluation
Paper and Code
Dec 10, 2024
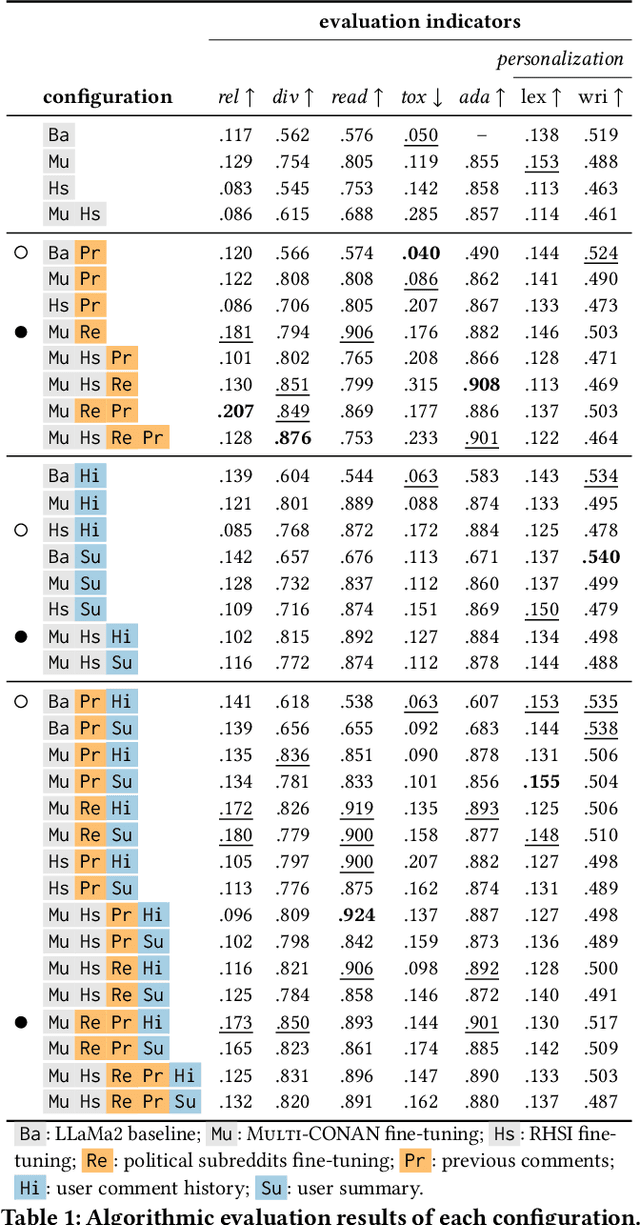
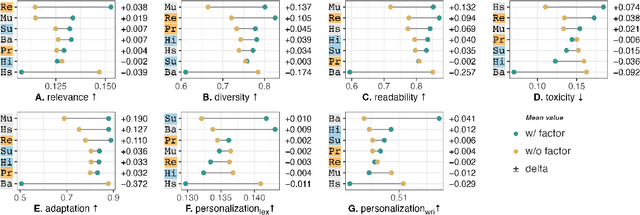

AI-generated counterspeech offers a promising and scalable strategy to curb online toxicity through direct replies that promote civil discourse. However, current counterspeech is one-size-fits-all, lacking adaptation to the moderation context and the users involved. We propose and evaluate multiple strategies for generating tailored counterspeech that is adapted to the moderation context and personalized for the moderated user. We instruct an LLaMA2-13B model to generate counterspeech, experimenting with various configurations based on different contextual information and fine-tuning strategies. We identify the configurations that generate persuasive counterspeech through a combination of quantitative indicators and human evaluations collected via a pre-registered mixed-design crowdsourcing experiment. Results show that contextualized counterspeech can significantly outperform state-of-the-art generic counterspeech in adequacy and persuasiveness, without compromising other characteristics. Our findings also reveal a poor correlation between quantitative indicators and human evaluations, suggesting that these methods assess different aspects and highlighting the need for nuanced evaluation methodologies. The effectiveness of contextualized AI-generated counterspeech and the divergence between human and algorithmic evaluations underscore the importance of increased human-AI collaboration in content moderation.